developer.nvidia.com
Cómo reducir cuellos de botella KV Cache con NVIDIA Dynamo
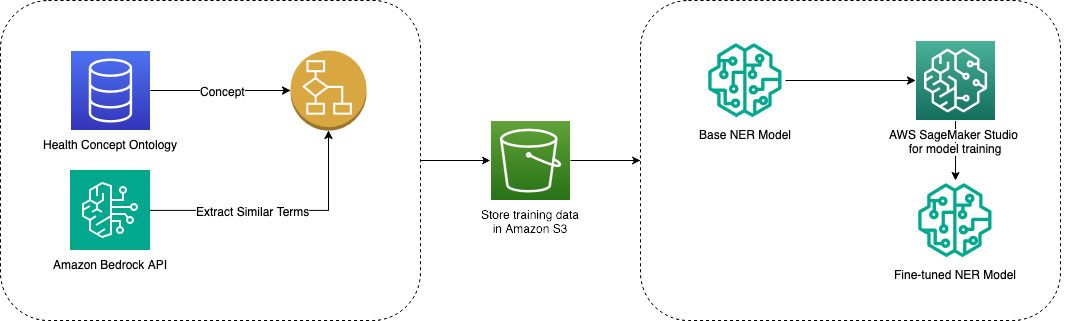
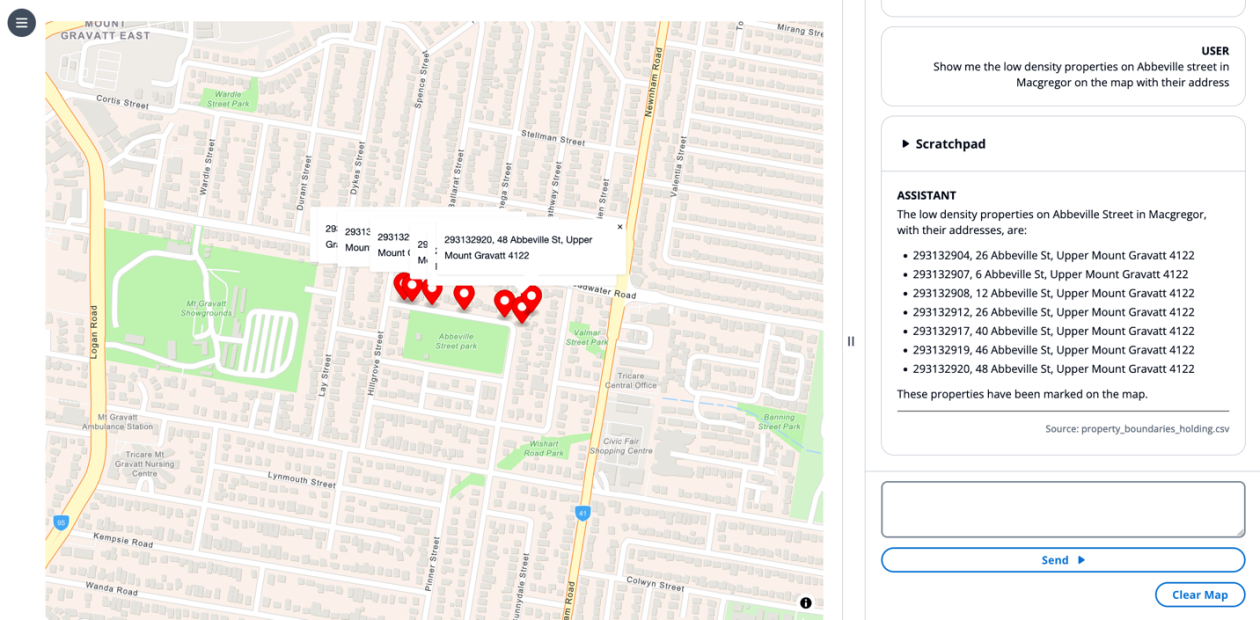
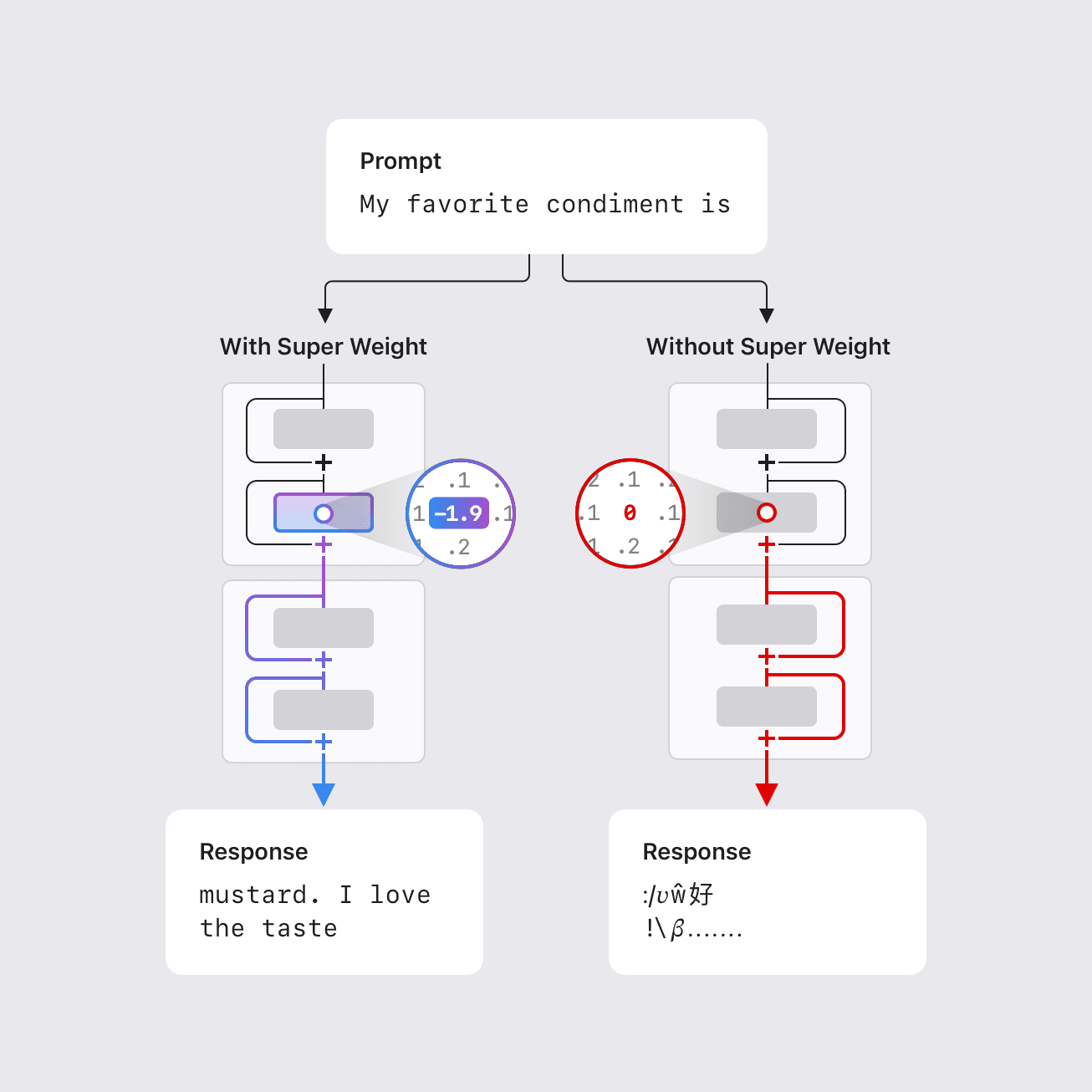
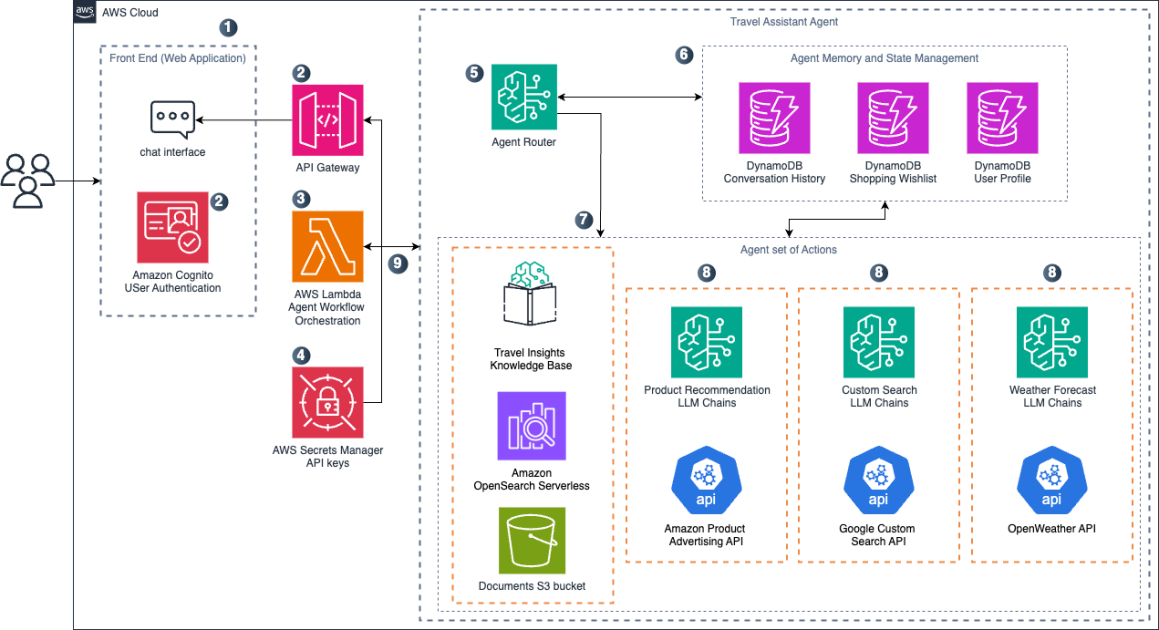
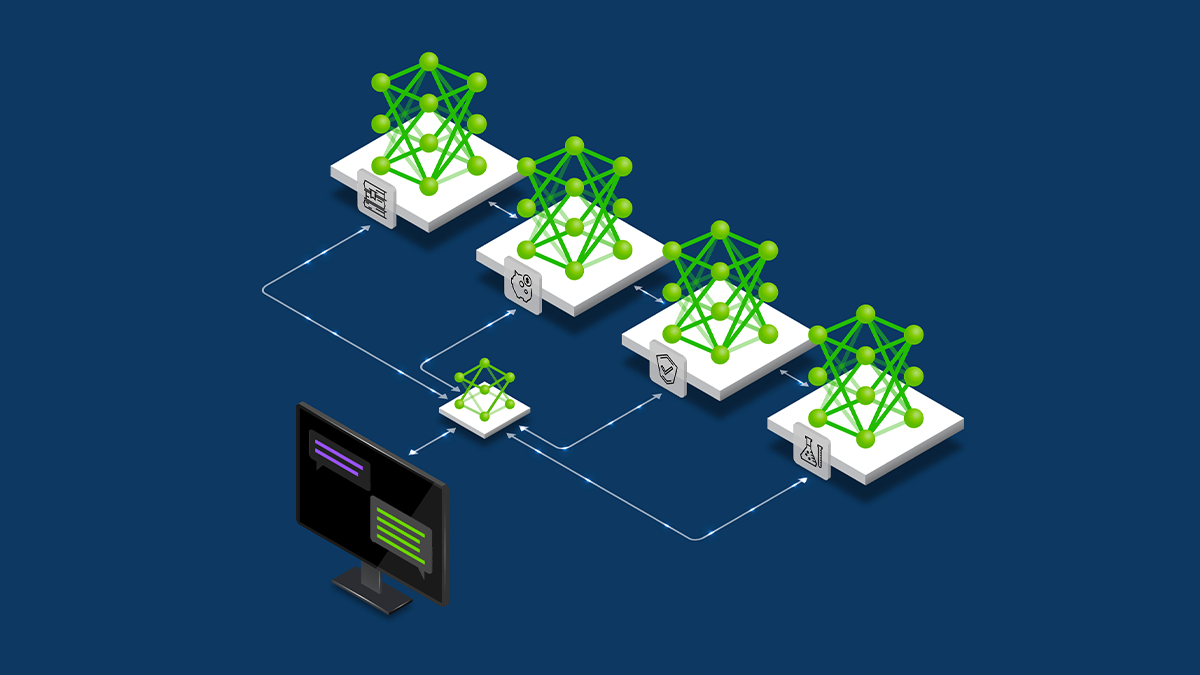
NVIDIA Dynamo offloads KV Cache desde la memoria de la GPU hacia almacenamiento económico, habilitando contextos más largos, mayor concurrencia y costos de inferencia más bajos para grandes modelos y cargas de IA generativa.