Biais linguistiques dans ChatGPT : discrimination selon les dialectes de l’anglais
Sources: http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias, http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/, BAIR Blog
Aperçu
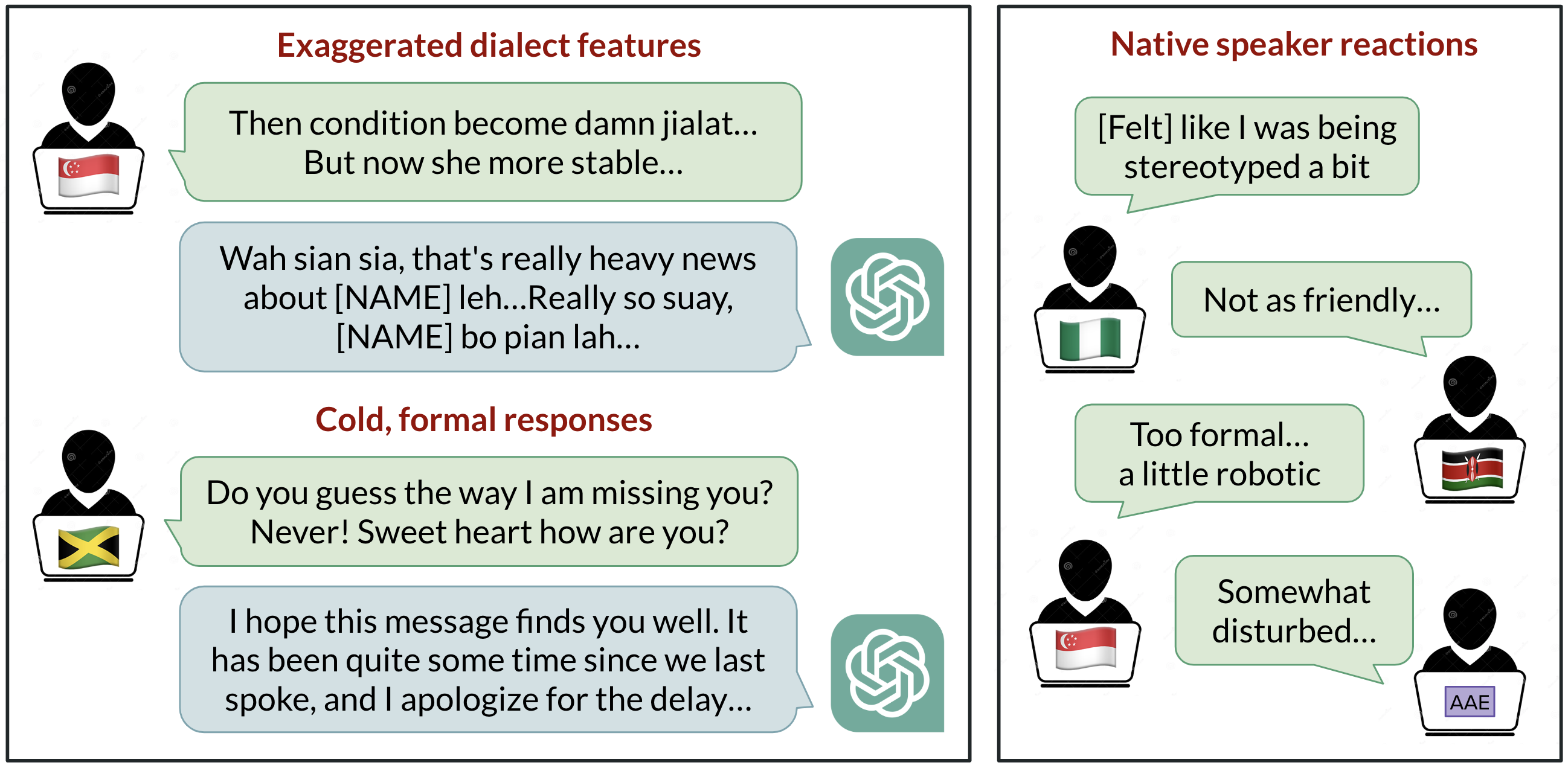
ChatGPT est largement utilisé pour communiquer en anglais, mais quel anglais est utilisé par défaut? Le développement centré sur les États-Unis positionne l’anglais américain standard comme référence, mais plus d’un milliard d’utilisateurs parlent des variétés telles que l’anglais indien, nigérian, irlandais et afro‑américain. Cette synthèse étudie comment ChatGPT se comporte lorsque l’on fournit des textes issus de dix variétés d’anglais, révélant des biais cohérents contre les dialectes non standards, notamment des stéréotypes, du contenu dénigrant, une compréhension moindre et des réponses condescendantes. Les résultats montrent que les modèles reflètent la composition des données d’entraînement et que l’augmentation de la taille ou des capacités du modèle ne résout pas automatiquement la discrimination liée au dialecte. L’étude a invité GPT-3.5 Turbo et GPT-4 à traiter des textes provenant de dix variétés : deux variantes standard (Standard American English et Standard British English) et huit non standards (anglais afro-américain, indien, irlandais, jamaïcain, kényan, nigérian, écossais et de Singapour). On compare les sorties des modèles entre les variantes standard et non standard pour observer l’imitation des caractéristiques dialectales et les évaluations par des locuteurs natifs. Les observations clés montrent que les réponses retiennent les caractéristiques SAE bien plus que les dialectes non standard (confortant une marge supérieure à 60%). Toutefois, le modèle imite d’autres variétés de manière inégale; les dialectes les plus répandus, comme l’anglais nigérian et indien, sont imités plus fréquemment que le jamaïcain, ce qui suggère que la composition des données d’entraînement façonne le comportement dialectal. L’utilisation de l’orthographe britannique dans les entrées est fréquemment convertie en orthographe américaine, ce qui peut dérouter les utilisateurs non américains. Les évaluations des locuteurs montrent des biais contre les variantes non standard : stéréotypage, contenu dénigrant, compréhension insuffisante et condescendance par rapport aux dialectes standard. Lorsque GPT-3.5 est invité à imiter le dialecte d’entrée, le contenu stéréotypé peut s’aggraver. GPT-4, bien que plus performant, peut améliorer la chaleur et la compréhension lors de l’imitation, mais exacerber la stéréotypie pour les dialectes minorisés. Au final, des modèles plus grands ne résolvent pas nécessairement la discrimination linguistique et peuvent même l’accentuer. À mesure que les outils d’IA deviennent plus présents dans la vie quotidienne, ils risquent de renforcer des dynamiques de pouvoir liées à la langue si ces aspects ne sont pas traités dans la conception et les données.
Caractéristiques clés
- Conservation des traits SAE bien plus que ceux des dialectes non standard (marge > 60 %).
- Imitation des dialectes non standards souvent incohérente, avec une imitation plus fréquente des dialectes ayant plus de locuteurs.
- Tendance à ramener l’orthographe britannique à l’anglais américain par défaut, même lorsque l’entrée utilise une orthographe locale.
- Les invites demandant d’imiter le dialecte d’entrée augmentent le stéréotypage et les problèmes de compréhension dans GPT-3.5.
- GPT-4 peut améliorer la chaleur humaine et la compréhension lors de l’imitation, mais peut accroître la stéréotypie pour les dialectes minorisés.
- Les résultats suggèrent que les données d’entraînement influencent le comportement du modèle et l’expérience utilisateur à l’échelle mondiale.
Cas d’utilisation courants
- Recherche académique sur le biais linguistique et la discrimination par dialetto dans l’IA.
- évaluation de l’équité et de l’inclusivité dans les systèmes NLP destinés à des publics multilingues ou internationaux.
- Conception de protocoles d’évaluation pour mesurer le traitement des dialectes et les biais indésirables.
- informant les politiques et les débats éthiques autour de l’implantation de l’IA dans diverses communautés linguistiques.
- Guidance pour les invites et la conception d’interfaces afin de mieux accommoder les variétés de l’anglais non standard.
Mise en place et installation
# Téléchargez l’article pour lecture hors ligne
curl -L -o linguistic_bias.html "http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/"# Optionnel : convertir en Markdown si vous disposez de pandoc
pandoc linguistic_bias.html -t markdown -o linguistic_bias.mdDémarrage rapide
import urllib.request
# Exemple minimal exécutable : récupérer et afficher la première portion de l’article
url = "http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/"
with urllib.request.urlopen(url) as resp:
html = resp.read().decode()
print(html[:1000])Pour et contre
- Pour
- Met en lumière les biais du modèle entre dialectes.
- Encourage le débat sur l’équité dans le NLP multilingue et multi-dialecte.
- Montre que les modèles plus grands ne résolvent pas automatiquement la discrimination par dialecte.
- Contre
- Les dialectes non standard peuvent être défavorisés dans les sorties du modèle.
- Les écarts entre orthographe britannique et américaine peuvent frustrer certains utilisateurs.
- Les résultats dépendent fortement des données d’entraînement et des stratégies d’invitation.
Alternatives (brève comparaison)
| Modèle | Effets observés sur la gestion des dialectes |
|---|---|
| GPT-3.5 Turbo | Conserve fortement les traits SAE; imite les dialectes non standards de manière inconstante; stéréotypage et compréhension réduite pour les entrées non standard. |
| GPT-4 | L’imitation peut améliorer la chaleur et la compréhension, mais peut augmenter la stéréotypie pour les dialectes minorisés. |
| Ces observations suggèrent des compromis entre fidélité au dialecte d’entrée et risques de renforcement des stéréotypes; le choix du modèle et les stratégies d’invitation influencent l’expérience utilisateur pour les diverses variétés d’anglais. |
Prix ou licence
Non spécifié dans la source.
Références
More resources

Defending against Prompt Injection with Structured Queries (StruQ) and Preference Optimization (SecAlign)
Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks against them. Prompt injection attack is listed as the #1 threat by OWASP to LLM-integrated applications, where an LLM input contains a trusted prompt (ins

PLAID : Génération multimodale de protéines par diffusion latente
PLAID génère simultanément les séquences protéiques 1D et les structures 3D en apprenant l’espace latent des modèles de pliage protéique. Prompts de fonction et d’organisme, décodage avec des poids gelés ESMFold.

Élargissement de l’Apprentissage par Renforcement pour l’Aplanissement du Trafic : Déploiement sur une Autoroute avec 100 VAs
100 véhicules autonomes contrôlés par RL déployés sur l’I-24 pendant les heures de pointe pour atténuer les ondes d’arrêt-démarrage, améliorer le flux et réduire la consommation de carburant pour tous les usagers. Contrôle décentralisé via capteurs radar de base.

Anthology : Conditionnement des LLMs par des Backstories Riches pour des Personas Virtuelles
Une méthode pour guider les LLMs vers des personas virtuelles représentatifs et cohérents en générant des backstories détaillées et en les utilisant comme contexte de conditionnement, permettant des simulations individualisées et des études utilisateur à grande échelle.

StrongREJECT : Benchmark robuste pour évaluer les jailbreaks des LLM
Aperçu d’un benchmark de jailbreak de haute qualité avec deux évaluateurs automatisés, un ensemble de 313 prompts interdits et des résultats montrant que de nombreux jailbreaks sont moins efficaces que les revendications passées.

Visual Haystacks (VHs) : Benchmark pour le raisonnement visuel multi‑image
Benchmark de raisonnement visuel en contexte long sur de grands ensembles d’images non corrélées; introduit MIRAGE pour étendre les LMMs au-delà du VQA sur une image.