vec2text : inversion des embeddings de texte et implications pour la sécurité
Sources: https://thegradient.pub/text-embedding-inversion, https://thegradient.pub/text-embedding-inversion/, The Gradient
Vue d’ensemble
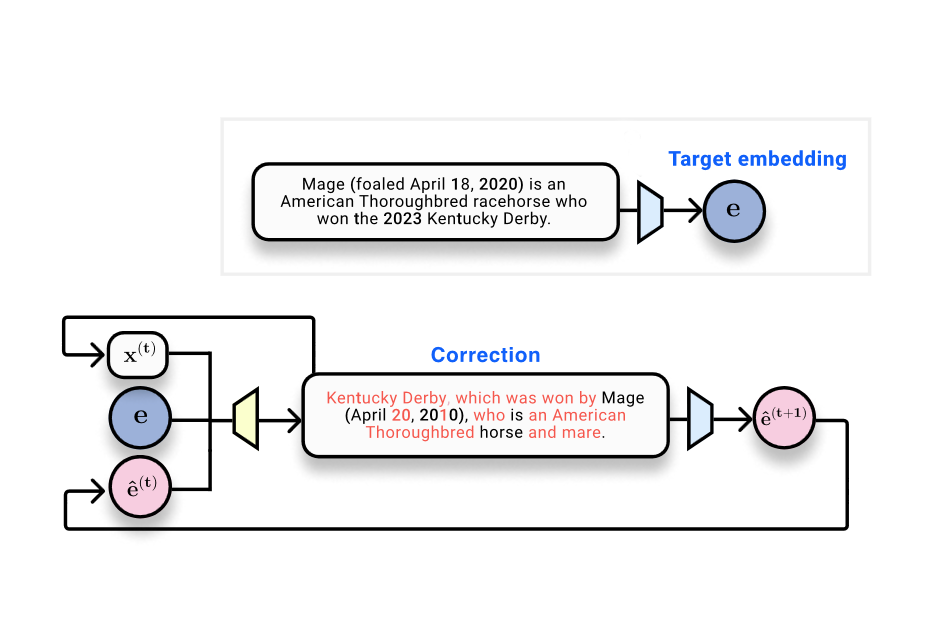
Les systèmes de Récupération Améliorée par Génération (RAG) stockent et recherchent des documents à l’aide d’embeddings — des représentations vectorielles du texte produites par des modèles d’embedding. The Gradient interroge une question centrale : peut-on récupérer le texte d’entrée à partir de ses embeddings ? Le texte situe les embeddings dans le contexte des bases de données vectorielles et des préoccupations de confidentialité liées au stockage des embeddings plutôt que du texte brut. Les auteurs évoquent l’étude Text Embeddings Reveal As Much as Text (EMNLP 2023), qui traite directement l’inversion : peut-on reconstruire le texte à partir d’embeddings de sortie ? Sur le plan technique, les embeddings sont le résultat de réseaux neuronaux : le texte est tokenisé, passe par des couches non linéaires et est finalement condensé dans un vecteur fixe de taille donnée. Des résultats issus des théories de l’information indiquent que de telles mappings ne peuvent pas augmenter l’information contenue dans l’entrée ; ils peuvent seulement la préserver ou la perdre. Dans le domaine de la vision, des travaux montrent que les images peuvent être reconstruites à partir des représentations profondes, ce qui motive l’enquête dans le domaine du texte. Un exemple “toy” considère 32 tokens mappés en embeddings 768-dimensionnels (32 × 768 = 24 576 bits, soit environ 3 ko). Cela fournit des mesures concrètes pour évaluer la récupération du texte. L’article présente une progression de méthodes et de mesures pour répondre à la question. Une approche initiale traite l’inversion comme un problème d’apprentissage automatique classique : rassembler des paires embedding–texte et entraîner un modèle à produire le texte à partir de l’embedding. Avec cette approche, un transformeur entraîné obtient un BLEU d’environ 30/100 et un taux de correspondance exacte proche de zéro, illustrant la difficulté d’une inversion parfaite en une seule passe. Observation clé : lorsque le texte généré est ré-embedé, l’embedding qui en résulte est très proche de l’embedding de référence — similarité cosinus autour de 0,97. Cela confirme que l’hypothèse textuelle reste proche dans l’espace d’embedding, même si le texte de surface diffère. L’idée centrale est de passer d’une inversion en une passe à un processus d’optimisation appris qui opère dans l’espace d’embeddings. Étant donné un embedding cible (l’objectif), un texte d’hypothèse et son embedding, un modèle correcteur est entraîné pour produire un texte qui se rapproche de la cible. C’est l’essence de vec2text : un optimiseur appris qui met à jour le texte en étapes discrètes pour s’aligner sur l’embedding cible. Après mise en œuvre, les auteurs rapportent une amélioration spectaculaire : un seul pas de correction porte le BLEU de ~30 à ~50. Et vec2text peut être utilisé de manière récursive : générer des hypothèses, les ré-embedder et les ré-introduire pour des mises à jour successives. Avec environ 50 itérations, la méthode récupère 92% des séquences de 32 tokens exactement et atteint un BLEU d’environ 97. En d’autres termes, pour ce cadre contraint, le vecteur d’embedding contient suffisamment d’informations pour reconstruire presque parfaitement le texte de surface d’origine, et pas seulement son sens. Cela suggère que les embeddings peuvent être inversés avec une fidélité élevée dans la pratique, ce qui soulève des questions importantes de sécurité et de confidentialité pour les systèmes d’embedding et les bases de données associées. L’article mentionne aussi certaines réserves. Tout d’abord, l’embedding a une capacité fixe, ce qui impose des limites théoriques à la quantité d’information pouvant être stockée et récupérée. Deuxièmement, les auteurs discutent la possibilité que la fonction d’embedding soit perdante (plusieurs entrées mappeant vers le même embedding), ce qui affecterait l’identifiabilité; dans leurs expériences, ils n’ont pas observé de collisions. Enfin, ce travail est à replacer dans un contexte plus large : si le texte peut être presque parfaitement reconstruit à partir des embeddings, alors des considérations de sécurité et de confidentialité s’imposent pour les bases de données vectorielles et les services qui manipulent des embeddings. Pour ceux qui veulent le cadre technique, l’article établit des parallèles avec l’inversion d’images et se réfère au papier EMNLP 2023 qui motive l’inversion côté texte : voir le lien cité pour une discussion détaillée et les détails expérimentaux : Text Embeddings Reveal As Much as Text.
Caractéristiques clés
- vec2text : une approche d’optimisation-apprise qui prend un embedding de référence, un texte d’hypothèse et sa position dans l’espace d’embedding pour prédire la séquence de texte exacte.
- Itération dans l’espace d’embedding : le procédé prend en charge le raffinement récursif via le ré-embedding du texte généré et son réentraînement.
- Gains de performance démontrés : une étape de correction porte le BLEU de ~30 à ~50 ; avec ~50 étapes, récupération exacte sur 92% des séquences de 32 tokens et BLEU proche de 97.
- Proximité dans l’espace des embeddings : le texte généré produit souvent des embeddings très proches de l’embedding d’origine (similarité cosinus ~0,97), même lorsque le texte de surface diffère.
- Implications de sécurité et de confidentialité : la capacité d’inverser les embeddings soulève des préoccupations pour le stockage et le partage de données basés sur des embeddings.
- Cadre théorique : relie l’inversion d’embeddings à des notions d’information et à des propriétés de lossy representations.
- Contexte inter-domaines : parallèle avec les travaux d’inversion d’images, où des représentations profondes permettent de reconstruire les entrées.
Cas d’usage
- Flux de travail RAG dépendants de la recherche par embeddings : les vecteurs dans une base de données vectorielle représentent des documents et la similarité dirige leur récupération. Si les embeddings peuvent être inversés pour récupérer le texte, cela introduit un risque de confidentialité pour les données stockées sous forme de vecteurs.
- Scénarios de fuite d’embeddings : une exposition accidentelle ou l’accès d’un fournisseur de service aux embeddings pourrait, en théorie, permettre la reconstruction du contenu textuel protégé, selon la capacité du modèle et les schémas d’accès.
- Impacts sur la sécurité des bases de données vectorielles : les organisations peuvent devoir réévaluer les politiques de rétention des données, le contrôle d’accès et les modèles de risque à la lumière de potentielles inversions.
- Piste de recherche : vec2text montre que l’inversion n’est pas seulement possible mais peut être améliorée par des corrections itératives, informant des approches de sécurité dans la conception des embeddings.
Setup & installation
Non fourni dans le document source. Si vous évaluez la sécurité des embeddings dans votre stack, considérez les actions générales suivantes :
# Non fourni dans le texteQuick start
- Partir d’un embedding de référence E et d’une hypothèse de texte H. Calculer l’embedding de H, le comparer à E et appliquer le modèle de correction vec2text pour prédire un texte plus proche de la cible.
- Ré-embedder le texte corrigé, comparer les embeddings et répéter le processus. Cette boucle récursive est le cœur de l’approche vec2text et a montré des gains substantiels de fidélité de surface.
- Dans le cadre toy décrit (32 tokens, embedding 768-d), les tentatives initiales donnent un BLEU d’environ 30 ; des itérations plus longues peuvent amener le BLEU près de 97 avec un nombre suffisant d’étapes, et une récupération exacte sur une grande partie des séquences.
Avantages et inconvénients
- Avantages
- Inversion de haute fidélité : démontrée récupération quasi parfaite pour un cadre 32 tokens après plusieurs itérations.
- Itération conceptuellement simple : réutilise l’embedding et les corrections pour converger vers le texte de référence.
- Définit une voie mesurable d’inversion à partir des embeddings avec des métriques claires (BLEU, correspondance exacte, similarité coseno).
- Peut être utilisé de manière récursive pour un raffinement progressif dans des scénarios de décodage itératif.
- Inconvénients
- Risque pour la vie privée : la capacité d’inverser les embeddings met en évidence les potentiels fuites de données dans le stockage et le partage basés sur des embeddings.
- Pas universel : la fidélité de récupération est démontrée pour un cadre toy spécifique ; des textes réels plus longs et avec des vocabulaires variés peuvent présenter des défis.
- Limites de capacité des embeddings : il existe une capacité binaire fixe dans un vecteur d’embedding, imposant des limites à l’information qui peut être stockée et reconstruite.
- Ambiguïtés possibles : bien que l’approche atteigne une fidélité élevée, les correspondances exactes ne sont pas garanties dans tous les cas ; des collisions (plusieurs entrées vers le même embedding) sont une préoccupation théorique, mais non observées dans ces expériences.
Alternatives (comparaisons rapides)
- Inversion directe avec un transformer entraîné pour mapper les embeddings vers le texte : la baseline a montré un BLEU d’environ 30 et une correspondance exacte proche de zéro, démontrant la difficulté d’une inversion sans raffinement itératif.
- Inversion d’embeddings d’images : en vision par ordinateur, des travaux montrent que les images peuvent être reconstruites à partir de représentations profondes, motivant les préoccupations d’inversion trans-domaines. Dosovitskiy (2016) est cité comme exemple ancien.
- Vision plus générale : les représentations d’embeddings sont intentionnellement lossy, mais les résultats d’inversion remettent en cause certaines hypothèses dans des contextes spécifiques.
Prix ou Licence
Non spécifié dans le matériel.
Références
More resources

IA Générale Non Multimodale : Intelligence axée sur l’Incarnation
Ressource concise expliquant pourquoi les approches multimodales axées sur l’échelle risquent de ne pas aboutir à une AGI et pourquoi l’incarnation et les modèles du monde sont essentiels.

Forme, Simétries et Structure: Le rôle changeant des mathématiques dans la recherche ML
Examine comment les mathématiques restent centrales en ML, mais leur rôle évolue vers la géométrie, les symétries et les explications post-hoc à l’ère des grandes échelles.

Ce qui manque aux chatbots LLM : un sens de l'objectif
Explore le dialogue orienté objectif dans les chatbots LLM, soutenant que les échanges multi-tours s'alignent mieux sur les objectifs des utilisateurs et favorisent la collaboration, notamment pour le code et les assistants personnels.

Visions positives de l'IA fondées sur le bien-être
Cadre centré sur le bien-être pour des IA bénéfiques, associant sciences du bien-être, économie et gouvernance pour tracer des visions pragmatiques et actionnables.

Applications des LLMs au marché financier — aperçu et cas d'utilisation
Aperçu de comment les LLMs peuvent être appliqués aux marchés financiers, incluant la modélisation autoregressive des données de prix, l’intégration multimodale, la résidualisation, les données synthétiques et les prévisions sur plusieurs horizons.

Vue d’ensemble sur les biais de genre dans l’IA
Synthèse des travaux clés mesurant les biais de genre dans l’IA, couvrant les embeddings, la co-référence, la reconnaissance faciale, les benchmarks QA et la génération d’images; discussion sur les mitigations et les lacunes.