
Scaleway Como Novo Fornecedor de Inferência no Hugging Face para Inferência serverless de Baixa Latência
Sources: https://huggingface.co/blog/inference-providers-scaleway, Hugging Face Blog
TL;DR
- A Scaleway passa a ser um Fornecedor de Inferência suportado no Hugging Face Hub, ampliando o ecossistema para inferência serverless.
- Fornecedores de Inferência estão integrados aos SDKs de cliente JavaScript e Python da Hugging Face, facilitando o uso entre modelos.
- Você pode acessar modelos abertos populares (p.ex., gpt-oss, Qwen3, DeepSeek R1, Gemma 3) diretamente do Hugging Face com a Scaleway como provedor.
- Scaleway Generative APIs oferece um serviço serverless, gerenciado, com preço a partir de €0,20 por milhão de tokens, com dados em centros europeus (Paris) e latência sub-200 ms no primeiro token.
- Faturamento transparente: cobrança direta pelo provedor ao usar uma chave de provedor; solicitações roteadas via Hugging Face cobram as taxas padrão de API do provedor, sem markup.
Contexto e pano de fundo
O Hugging Face continua ampliando o conjunto de opções de inferência compatíveis ao adicionar Fornecedores de Inferência às páginas de modelos. A Scaleway é o mais novo participante, permitindo inferência serverless diretamente no Hub juntamente com outros provedores. Essa integração facilita a adoção de modelos no ambiente de produção, oferecendo uma rota simples para workloads de IA que exigem baixa latência e escalabilidade. A integração também se beneficia das ferramentas de desenvolvedor: os Fornecedores de Inferência estão integrados aos SDKs de cliente da Hugging Face para JavaScript e Python, facilitando o uso da infraestrutura da Scaleway com stacks de desenvolvimento já existentes. Os usuários podem navegar pela organização Scaleway no Hub e experimentar modelos em alta, promovendo experimentação rápida e integração em fluxos de ML já estabelecidos.
O que há de novo
Este anúncio formaliza a Scaleway como um Fornecedor de Inferência suportado no Hugging Face Hub. Recursos e capacidades incluem:
- Acesso a modelos populares abertos via Scaleway no Hugging Face, incluindo gpt-oss, Qwen3, DeepSeek R1 e Gemma 3.
- Integração direta aos SDKs de cliente JS e Python para uso simplificado entre provedores.
- Scaleway Generative APIs como serviço totalmente gerenciado e serverless, com chamadas de API simples para acessar modelos de ponta.
- Preços competitivos a partir de €0,20 por milhão de tokens, com centros de dados na Europa (Paris, França) para apoiar soberania de dados e baixa latência.
- Funcionalidades avançadas como saídas estruturadas, chamadas de função e capacidades multimodais para texto e processamento de imagem.
- Tempos de resposta inferiores a 200 ms para os primeiros tokens, tornando o Scaleway adequado para aplicativos interativos e fluxos de trabalho agentizados; suporte para geração de texto e embeddings.
- Modelo de faturamento claro: cobranças diretas do provedor ou solicitações roteadas com tarifas padrão de API do provedor, sem markup pela Hugging Face.
- Reconhecimento da necessidade de feedback contínuo dos desenvolvedores e possibilidades de acordos de compartilhamento de receita no futuro com parceiros do provedor.
Por que isso importa (impacto para desenvolvedores/empresas)
A colaboração Scaleway–Hugging Face reduz as barreiras para adotar inferência serverless escalável no Hub. Para desenvolvedores, a integração com os SDKs de JS e Python permite incorporar a inferência respaldada pela Scaleway diretamente em aplicações, sem configurações complexas ou roteamento personalizado. A possibilidade de acessar modelos de alto interesse por meio de um único canal de provedor simplifica a experimentação e a implantação em fluxos de trabalho de IA, acelerando o desenvolvimento de recursos que dependem de linguagem, embeddings ou capacidades multimodais. Do ponto de vista empresarial, os centros de dados europeus oferecem opções de soberania de dados adequadas para implementações que exigem conformidade. A arquitetura serverless reduz a sobrecarga operacional, enquanto a latência baixa ajuda a atender às expectativas de experiência do usuário para recursos de IA em tempo real. A capacidade de escolher entre cobrança via provedor ou cobrança via Hugging Face oferece flexibilidade de precificação para alinhar o uso com governança de custos interna. A transparência de preços também é um ponto positivo: cobranças diretas ao usar uma chave de provedor são faturadas pela Scaleway, enquanto solicitações roteadas through Hugging Face são cobradas às tarifas padrão de API do provedor, sem acréscimo pela plataforma. Isso facilita a modelagem de custos e a comparação com outros provedores no ecossistema.
Detalhes técnicos ou Implementação
A integração da Scaleway como Fornecedor de Inferência foi projetada para ser facilmente integrada em fluxos existentes:
- Acesso a modelos: é possível navegar pela organização Scaleway no Hub e experimentar modelos em alta compatibilidade, como gpt-oss, Qwen3, DeepSeek R1 e Gemma 3.
- Como rotear: você pode usar um token do Hugging Face para roteamento automático ou uma chave de API Scaleway; é necessário usar uma versão recente do huggingface_hub (>= 0,34,6).
- Modelo de faturamento: solicitações diretas geram cobranças na conta Scaleway; solicitações roteadas via Hugging Face cobram tarifas padrão de API do provedor, sem markup.
- Disponibilidade e desempenho: Scaleway Generative APIs são descritas como totalmente gerenciadas e serverless, com latência de sub-200 ms para os primeiros tokens e suporte a geração de texto e embeddings. O conjunto suporta saídas estruturadas, chamadas de função e processamento multimodal de texto e imagem.
- Soberania de dados: os serviços operam em centros de dados europeus, com Paris, França, como exemplo de localização.
- Documentação e referências: saiba mais sobre a plataforma Scaleway em https://www.scaleway.com/en/generative-apis/ e leia a documentação dedicada sobre usar Scaleway como Fornecedor de Inferência no Hugging Face. Aspectos de implementação para equipes incluem garantir versões adequadas de ferramentas, gerenciar senhas/keys com segurança e entender o modelo de faturamento para otimizar custos entre uso roteado versus direto.
Principais conclusões
- Scaleway é um Fornecedor de Inferência suportado no Hugging Face Hub, expandindo as opções de inferência serverless.
- A integração facilita o uso via SDKs JS e Python da Hugging Face para diversos modelos.
- Scaleway Generative APIs oferece uma experiência de inferência pronta para produção, com preços competitivos na Europa, latência baixa e soberania de dados.
- Os modelos de faturamento oferecem flexibilidade entre cobrança direta pelo provedor ou cobrança via Hugging Face sem markup.
- O ecossistema continua evoluindo, com espaço para feedback e potenciais acordos futuros com parceiros do provedor.
FAQ
-
O que significa Scaleway ser um Fornecedor de Inferência no Hugging Face?
Significa que Scaleway é uma opção suportada para inferência serverless diretamente nas páginas de modelos do Hugging Face, com integração aos SDKs de JS e Python.
-
Como funciona a precificação ao usar Scaleway no Hugging Face?
Solicitações diretas são faturadas pela Scaleway na conta do provedor; solicitações roteadas via Hugging Face são cobradas às tarifas padrão de API do provedor, sem markup pela Hugging Face.
-
uais modelos estão disponíveis via Scaleway no Hugging Face?
Modelos populares abertos como gpt-oss, Qwen3, DeepSeek R1 e Gemma 3 estão entre os citados como acessíveis pela Scaleway na Plataforma.
-
uais são os requisitos técnicos para usar Scaleway como Fornecedor de Inferência?
Você pode autenticar com um token do Hugging Face para roteamento automático ou com uma chave de API Scaleway; use uma versão recente do huggingface_hub (>= 0,34,6).
-
References
More news

Construir Fluxos de Trabalho Agenticos com GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore
Visão geral de ponta a ponta para implantar modelos GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore, alimentando um analisador de ações com múltiplos agentes usando LangGraph, incluindo quantização MXFP4 de 4 bits e orquestração serverless.

Maximizando a Baixa Latência de Rede para Serviços Financeiros com NVIDIA Rivermax e NEIO FastSocket
Examina como NVIDIA Rivermax e NEIO FastSocket oferecem latência ultra‑baixa e alto rendimento, usando kernel bypass, zero‑copy e GPUDirect para mover dados diretamente do NIC para GPUs.

Conectando Centros de Dados Distribuídos em Grandes Fábricas de IA com Scale-Across Networking
O Spectrum-XGS Ethernet da NVIDIA habilita scale-across Networking para unir centros de dados dispersos em uma única fábrica de IA, proporcionando ganhos de largura de banda NCCL e desempenho previsível em longas distâncias.

Faça seus ZeroGPU Spaces trabalharem rápido com compilação ahead-of-time do PyTorch
Spaces com ZeroGPU ganham demos mais rápidas em hardware Nvidia H200 por meio da compilação ahead-of-time (AoT) do PyTorch, com inicialização mais ágil e inferência eficiente, suporte a FP8 e formas dinâmicas.
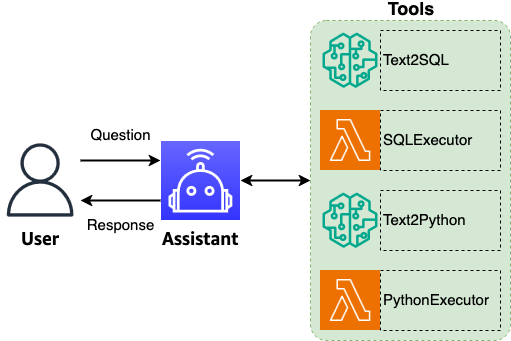
Análise de bancos de dados baseada em linguagem natural com Amazon Nova
Explora análises de bancos de dados via linguagem natural usando os modelos de base Amazon Nova, o padrão ReAct e LangGraph para traduzir consultas em NL para SQL preciso, com fluxos HITL e autocorreção.
Faça seus ZeroGPU Spaces ficarem mais rápidos com compilação AoT do PyTorch
Descubra como a compilação ahead-of-time (AoT) do PyTorch acelera ZeroGPU Spaces em GPUs Nvidia H200, com recarregamento instantâneo, quantização FP8, formas dinâmicas e ganhos de desempenho práticos (1,3x–1,8x) para Flux, Wan e LTX.