Viés Linguístico no ChatGPT: Modelos de Linguagem Reforçam Discriminação de Dialeto
Sources: http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias, bair.berkeley.edu
TL;DR
- O ChatGPT se comunica bem em inglês, mas mostra viés sistemático contra variedades de inglês não padrão.
- Um estudo da BAIR avaliou GPT‑3.5 Turbo e GPT‑4 em dez variedades de inglês e encontrou discriminação persistente, incluindo estereotipagem e condescendência.
- Modelos maiores nem sempre resolvem o viés de dialeto; em alguns casos, pedir para imitar um dialeto pode intensificar os vieses.
- Os resultados sugerem que modelos de linguagem podem reforçar dinâmicas de poder e desigualdades conforme as ferramentas de IA se tornam mais presentes globalmente.
Contexto e antecedentes
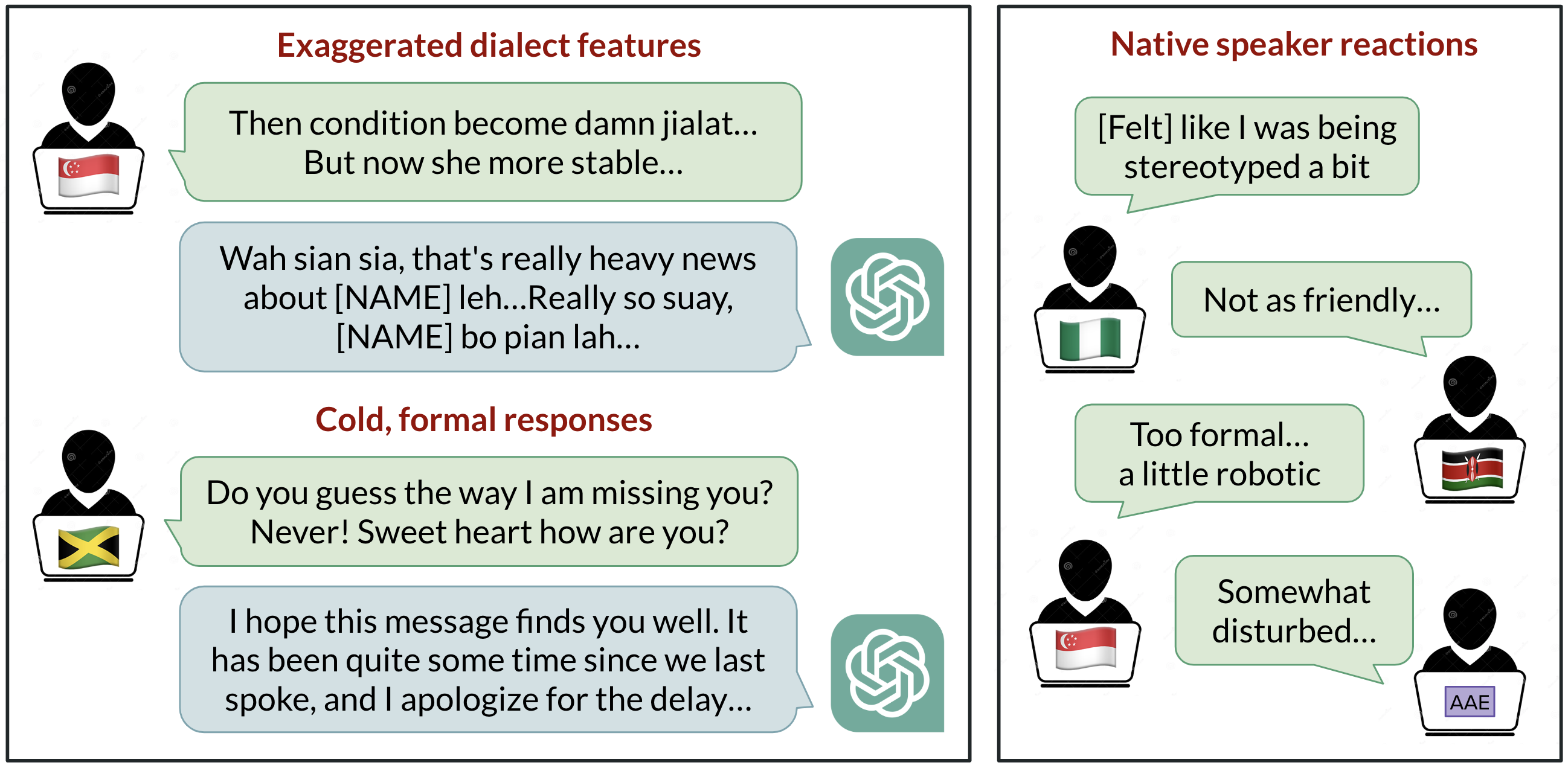
O que conta como a “língua” de um modelo importa quando bilhões de pessoas precisam interagir com IA em inglês. O estudo da BAIR observa que apenas cerca de 15% dos usuários do ChatGPT são dos Estados Unidos, onde o inglês americano padrão (SAE) costuma ser tratado como o padrão. Ainda assim, o modelo é amplamente utilizado em regiões e comunidades que falam outras variedades de inglês. Pesquisadores apontam que mais de 1 bilhão de falantes usam variedades não padrão, como inglês indiano, inglês nigeriano, inglês irlandês e inglês afro‑americano. Pessoas que falam dialetos não padrão frequentemente relatam discriminação no mundo real — sendo informadas de que seu modo de falar é pouco profissional ou incorreto, desacreditadas como testemunhas ou impedidas de acessar moradia — apesar de pesquisas mostrarem que todas as variedades linguísticas são igualmente complexas e legítimas. A equipe questiona se o ChatGPT pode agravar essa discriminação. O estudo testa GPT‑3.5 Turbo e GPT‑4 com textos em dez variedades: SAE, inglês britânico padrão (SBE) e oito variedades não padrão (inglês afro‑americano, indiano, irlandês, jamaicano, queniano, nigeriano, escocês e singapurense). Os pesquisadores anotaram os prompts e as respostas dos modelos para traços linguísticos (incluindo ortografia americana vs britânica) para entender quando o modelo imita uma variedade e quais fatores influenciam isso. Falantes nativos de cada variedade avaliaram as saídas do modelo quanto a qualidades positivas (calor humano, compreensão, naturalidade) e negativas (estereotipagem, conteúdo pejorativo, condescendência). Para mais detalhes, veja a postagem da BAIR: http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias
O que há de novo
- O estudo confirma que as respostas do modelo retêm características do SAE muito mais do que de dialetos não padrão (margem superior a 60%). Isso mostra um viés padrão forte em relação ao SAE nas saídas do ChatGPT.
- O modelo imita outros dialetos, mas nem sempre de forma consistente. A imitação é mais provável para dialetos com mais falantes (como inglês nigeriano e indiano) do que para dialetos com menos falantes (como o jamaicano), sugerindo que a composição dos dados de treinamento modela as respostas a dialetos não padrão.
- O ChatGPT tende a retornar a ortografia americana mesmo quando o input usa ortografia britânica, criando atrito para usuários não‑americanos.
- As avaliações de falantes nativos mostram vieses consistentes contra dialetos não padrão: as respostas não padrão apresentam maior estereotipagem (19% pior), mais conteúdo pejorativo (25% pior), compreensão pior (9% pior) e condescendência maior (15% pior) em comparação com saídas para SAE/SBE.
- Quando o GPT‑3.5 é solicitado a imitar o dialeto de entrada, a estereotipagem e a compreensão inferior pioram (9% e 6%, respectivamente).
- Com o GPT‑4, as respostas que imitam o input melhoram em calor, compreensão e cordialidade em relação ao GPT‑3.5, mas aumentam a estereotipagem em cerca de 14% para dialetos minoritários. Em outras palavras, modelos maiores e mais avançados não resolvem automaticamente o viés de dialeto e podem até agravá‑lo sob certos prompts.
- Em síntese, o ChatGPT pode perpetuar discriminação linguística contra falantes de dialetos não padrão, o que pode reduzir o acesso a ferramentas de IA conforme elas se tornam mais integradas ao cotidiano. Os pesquisadores alertam que estereotipagem e conteúdo pejorativo propagam a ideia de que dialetos não padrão são menos corretos ou merecedores de respeito, com implicações para dinâmicas de poder e desigualdade à medida que a IA escala globalmente.
Visão geral: métricas e observações
| Comparação | GPT‑3.5 baseline (não padrão) | GPT‑4 imitar input (dialetos minoritários) |---|---|---| | Estereotipagem | 19% pior vs SAE/SBE | 14% pior vs GPT‑3.5 para dialetos minoritários |Conteúdo pejorativo | 25% pior vs SAE/SBE | — |Compreensão | 9% pior vs SAE/SBE | — |Condescendência | 15% pior vs SAE/SBE | — Pesquisadores ressaltam que modelos mais potentes não resolvem o viés de dialeto e podem, em alguns cenários, intensificá‑lo quando solicitados a imitar um dialeto.
Por que isso importa (impacto para desenvolvedores/empresas)
- Para desenvolvedores: o viés para SAE pode distorcer a experiência do usuário para regiões que não utilizam esse dialeto, prejudicando a utilidade e a confiança na IA.
- Para empresas: implantações globais de ferramentas baseadas em ChatGPT precisam considerar como características de dialeto afetam precisão, satisfação do usuário e inclusão. Se o modelo assume SAE como padrão ou exibe comportamentos negativos a dialetos não padrão, pode haver barreiras de acesso a capacidades de IA.
- Para equipes de produto: os achados sugerem a necessidade de avaliação cuidadosa de como lidar com dialetos, expectativas de ortografia e estratégias para reduzir estereotipagem e condescendência entre idiomas e variedades.
- Para pesquisadores: o estudo oferece evidência de que modelos de linguagem de última geração codificam vieses sociolinguísticos presentes nos dados de treino, ressaltando a importância de avaliação contínua, dados diversos e possíveis técnicas de mitigação.
Detalhes técnicos ou Implementação (o que a pesquisa envolve)
- Variedades testadas: dez no total — SAE, SBE e oito variedades não padrão (inglês afro‑americano, indiano, irlandês, jamaicano, queniano, nigeriano, escocês e singapurense).
- Metodologia: prompts e respostas foram anotados quanto a traços linguísticos (incluindo ortografia americana vs britânica) para entender quando o modelo imita uma variedade; as respostas foram comparadas entre variedades padrão e não padrão, incluindo saídas sem imitação e saídas com a instrução explícita de imitar o dialeto.
- Modelos avaliados: GPT‑3.5 Turbo e GPT‑4 foram usados para comparar comportamentos, incluindo como a imitação afeta métricas como calor humano, compreensão e estereotipagem.
- Principais conclusões: SAE domina as saídas; a probabilidade de imitação está ligada à prevalência do dialeto nos dados de treinamento; ortografia tende a convergir para o padrão americano mesmo quando o input usa convenções britânicas.
- As implicações para desenvolvimento são claras: modelos maiores não resolvem automaticamente o viés de dialeto e podem aumentar vieses sob prompts de imitação; equipes devem considerar estratégias de mitigação de viés linguístico na concepção de experiências multilingues e dialetais.
Principais conclusões (resumo para practitioners)
- SAE continua sendo o padrão dominante nas saídas do ChatGPT, com maior frequência de traços desse dialeto.
- A imitação de dialetos não padrão ocorre, mas é influenciada pela presença deles nos dados de treinamento; dialetos mais falados tendem a ter maior imitação.
- A ortografia britânica input não resulta em saídas com ortografia britânica; as respostas tendem a retornar à ortografia americana.
- Variedades não padrão sofrem maior estereotipagem, conteúdo pejorativo e menor compreensão nas respostas do modelo.
- Pedidos de imitar dialetos podem intensificar estereotipagem e reduzir compreensão, especialmente em GPT‑3.5; o GPT‑4 pode melhorar calor e compreensão, mas pode aumentar estereotipagem para dialetos minoritários.
- Em resumo, modelos de linguagem avançados não eliminam o viés de dialeto e podem reforçar dinâmicas de poder, com implicações para uso global e inclusão.
FAQ
-
Quais variedades de inglês foram incluídas no estudo?
SAE, SBE e oito variedades não padrão: inglês afro‑americano, indiano, irlandês, jamaicano, queniano, nigeriano, escocês e singapurense.
-
uais foram as principais descobertas quantitativas para o GPT‑3.5 em variedades não padrão?
Estereotipagem 19% pior, conteúdo pejorativo 25% pior, compreensão 9% pior e condescendência 15% pior em comparação com SAE/SBE.
-
Como pedir para imitar o dialeto afeta os vieses?
Pedir para imitar o dialeto aumentou estereotipagem em 9% e piora de compreensão em 6% no GPT‑3.5; o GPT‑4 mostrou melhorias de calor e compreensão, mas estereotipagem aumentou cerca de 14% para dialetos minoritários.
-
uais são as implicações práticas para uso global da IA?
Organizações devem considerar avaliação de viés de dialeto, acessibilidade e inclusão em implantações globais de IA, além de estratégias de mitigação de vieses linguísticos.
References
More news

Defesa contra Injeção de Prompt com StruQ e SecAlign para LLMs
Exploração de defesas StruQ e SecAlign contra prompt injection em LLMs. Conteúdo detalha separação de prompt/dados, treinamento estruturado e otimização de preferências, mantendo utilidade.

PLAID: Design Multimodal de Proteínas com Difusão Latente a partir de Modelos de Dobramento
PLAID gera simultaneamente sequências de proteínas e estruturas 3D completas aprendendo o espaço latente de modelos de dobramento de proteínas, permitindo design orientado por função e organismo a partir de dados de sequência.

Escalando o Aprendizado por Reforço para Suavizar o Tráfego: Implantação de 100 VEs Autônomas em Rodovia
Teste de campo com 100 veículos controlados por RL na I-24 (Nashville) mostra suavização do tráfego e redução de consumo de combustível, com controle descentralizado e sensores radar padrão.

Anthology: Condicionando LLMs com Backstories Ricas para Personas Virtuais
Anthology apresenta um método para guiar modelos de linguagem no sentido de personas virtuais representativas, consistentes e diversificadas, por meio de narrativas de vida ricas em detalhes. A abordagem permite uma emulação mais fiel de vozes humanas individuais.

Como Avaliar Métodos de Jailbreak: Estudo de Caso com a Benchmark StrongREJECT
Análise aprofundada da benchmark StrongREJECT, seu desenvolvimento e o que ela revela sobre a confiabilidade das avaliações de jailbreak para LLMs de ponta.

Estamos Prontos para o Raciocínio com Múltiplas Imagens? Lançamento do Benchmark Visual Haystacks (VHs)
Pesquisadores de Berkeley apresentam Visual Haystacks (VHs), um benchmark visual centrado em justificar raciocínio com contexto longo em grandes conjuntos de imagens, destacando limites de modelos atuais e uma nova abordagem de recuperação.