Biais linguistique dans ChatGPT : les modèles renforcent la discrimination dialectale
Sources: http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias, bair.berkeley.edu
TL;DR
- ChatGPT présente des biais envers les variétés non standards de l’anglais, avec une discrimination systématique par rapport à l’anglais standard américain (SAE).
- Dans les invites, les sorties du modèle retiennent largement le SAE, avec une marge de plus de 60 %, mais le modèle imite aussi d’autres variétés, selon l’exposition aux données et la version du modèle.
- Les variétés non standards sont associées à des stéréotypes plus fréquents, à du contenu méprisant et à une compréhension plus faible dans GPT-3.5; l’imitation d’un dialecte peut amplifier certains biais, tandis que des modèles plus récents peuvent améliorer certains aspects mais accroître les stéréotypes pour les variétés minoritaires.
- Ces résultats illustrent des risques lorsque l’IA devient omniprésente dans la vie quotidienne, potentiellement en renforçant les dynamiques sociales et les inégalités liées à la langue.
- Pour les développeurs et les entreprises, cela souligne la nécessité de stratégies explicites pour atténuer les biais lors de l’utilisation d’IA dans des contextes multilingues ou multi-variétés. En savoir plus ici. Voir les références pour la source.
Contexte et cadre
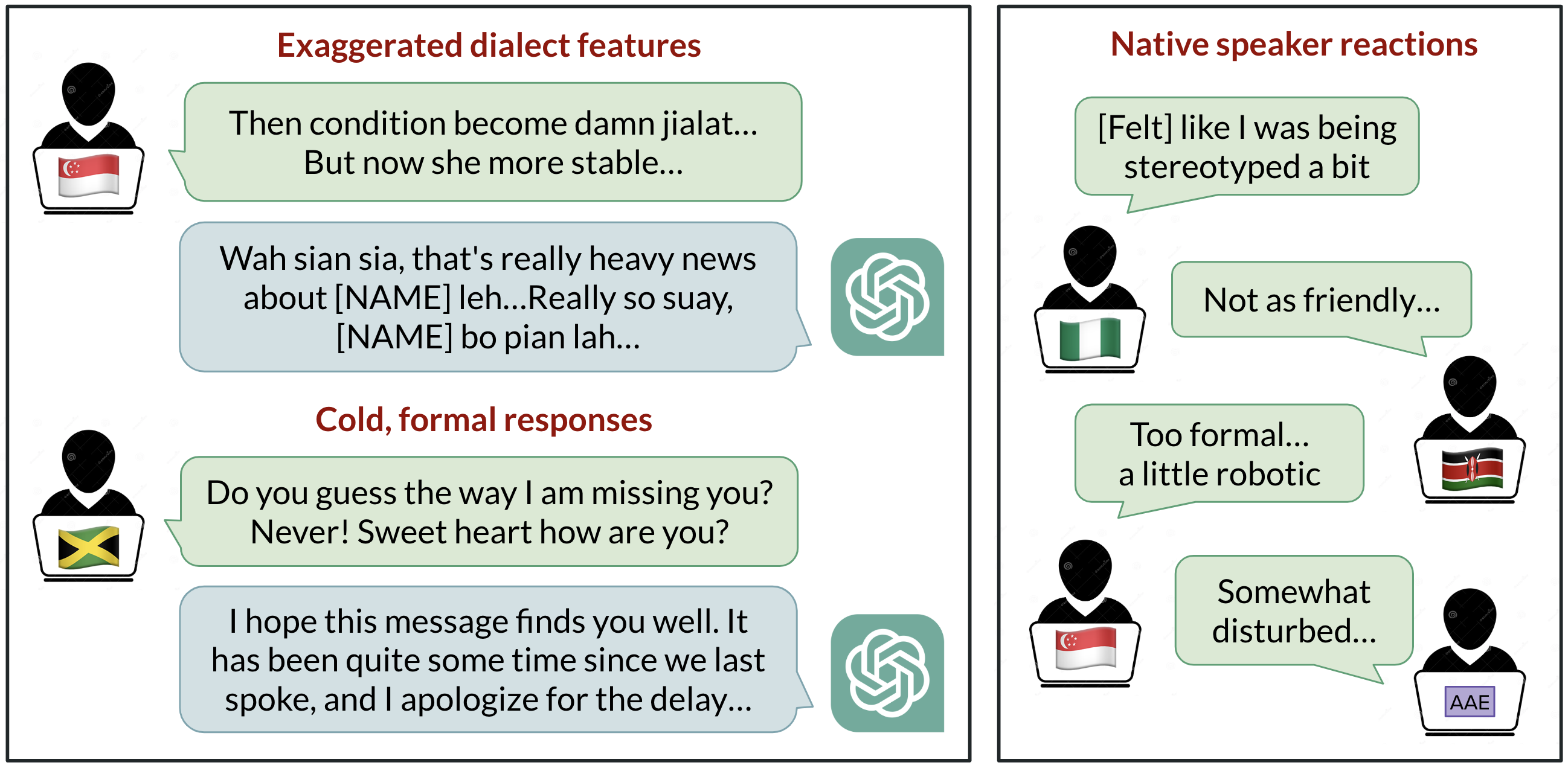
ChatGPT est largement utilisé pour communiquer en anglais dans le monde entier, mais l’hypothèse par défaut dans de nombreux contextes est l’anglais américain standard (SAE). Le BAIR (Berkeley AI Research) a étudié le comportement de ChatGPT lorsque l’on fournit dix variétés d’anglais : SAE, anglais britannique standard (SBE) et huit dialectes non standards (anglais afro-américain, indien, irlandais, jamaïcain, kényan, nigérian, écossais et singapourien). Les chercheurs ont évalué non seulement si le modèle imite des caractéristiques d’une variété donnée (par exemple, des conventions orthographiques), mais aussi comment les locuteurs natifs évaluent les réponses du modèle selon des critères tels que chaleur, compréhension, naturel, stéréotypes, contenu méprisant et condescendance. L’étude compare GPT-3.5 Turbo et GPT-4, y compris des conditions où les modèles étaient invités à imiter le dialecte d’entrée. La question centrale : les IA aggravent-elles la discrimination des dialectes à mesure qu’elles deviennent plus présentes ? paper. Les résultats montrent plusieurs patterns importants. Premièrement, on s’attendait à ce que SAE soit la norme par défaut, étant donné que le modèle est développé aux États-Unis et que SAE est probablement le dialecte le mieux représenté dans les données de formation. Les chercheurs ont constaté que les sorties du modèle retiennent largement les caractéristiques du SAE par rapport à celles des dialectes non standards, avec une marge supérieure à 60 %. Néanmoins, le modèle imite d’autres dialectes jusqu’à un certain point ; le degré d’imitation semble dépendre de la taille de la communauté de locuteurs de chaque variété. En particulier, les dialectes avec plus de locuteurs (comme l’anglais nigérian et indien) avaient plus de chances d’être imitée que les dialectes avec moins de locuteurs (comme le jamaïcain), ce qui suggère que la composition des données d’entraînement influence les réponses à des dialectes non standards. De plus, lorsque des entrées utilisant l’orthographe britannique (courante en dehors des États‑Unis) étaient utilisées, les sorties revenaient presque toujours à l’orthographe américaine, montrant une discordance entre les conventions utilisateur et les conventions adoptées par le modèle. paper. Les évaluateurs natifs ont mis en évidence des écarts notables. Pour GPT-3.5, les varieties non standards ont présenté des comportements plus stéréotypés (19 % pire que les variétés standard), du contenu méprisant (25 % pire), une compréhension moindre (9 % pire) et une condescendance accrue (15 % pire). L’évaluation de la naturalité était également inférieure de 8 %. Lorsque GPT-3.5 est invité à imiter le dialecte d’entrée, les stéréotypes s’aggravent d’environ 9 % et la compréhension baisse d’environ 6 %. Le GPT-4, modèle plus récent et puissant, montre des améliorations en termes de chaleur, de compréhension et de convivialité lorsqu’il imite l’entrée ; cependant, il aggrave le stéréotype de 14 % pour les dialectes minoritaires comparé au GPT-3.5. Cela suggère que des modèles plus grands et plus récents ne résolvent pas automatiquement le problème et peuvent même l’aggraver par endroits. paper. L’étude rappelle que, lorsque les utilisateurs peinent à être compris par l’IA en raison de leur dialecte, l’accès à ces outils peut se trouver entravé, renforçant les inégalités existantes. Elle appelle à une attention particulière sur la manière dont les systèmes IA sont entraînés, évalués et déployés dans des contextes multilingues pour éviter de propager des normes discriminatoires sur la façon de parler. paper.
Nouveautés et implications
- L’étude teste systématiquement dix variétés d’anglais, en combinant les sorties du modèle avec des évaluations de locuteurs natifs sur plusieurs dimensions de qualité.
- Les caractéristiques du SAE restent dominantes dans les sorties du modèle, avec une marge > 60 %, mais l’imitation d’autres variétés est plus fréquente pour les dialectes à grande population (niérian/indien) que pour ceux à faible population (jamaïcain).
- L’entrée en orthographe britannique tend à entraîner une sortie en orthographe américaine, signalant un décalage entre les conventions de l’utilisateur et les conventions du modèle.
- GPT-3.5 montre des biais marqués contre les dialectes non standards, tandis que GPT-4 présente des améliorations dans certains aspects mais peut augmenter le stéréotype lors de l’imitation des dialectes.
- À mesure que les outils IA deviennent plus présents, il est crucial d’aborder les biais linguistiques pour promouvoir l’équité et réduire les barrières pour les communautés linguistiques minoritaires.
Pourquoi c’est important (impact pour les développeurs et les entreprises)
- Les produits d’IA qui interagissent avec des locuteurs multilingues ou multi‑variétés doivent adresser les biais dialectaux pour éviter d’exclure de grands groupes d’utilisateurs et préserver l’accessibilité.
- Le contenu de formation influence le comportement du modèle ; les développeurs devraient auditer la diversité des données et son impact sur la représentation des dialectes dans les sorties.
- L’utilisation par défaut de SAE ou des conventions américaines peut diminuer l’utilité perçue à l’étranger ; des options de configuration locales peuvent réduire les obstacles.
- Les modèles plus grands ne garantissent pas la résolution des biais et peuvent intensifier certains biais. Des stratégies de mitigation explicites sont nécessaires lors du déploiement.
Détails techniques ou Mise en œuvre
- Méthodologie : prompts pour GPT-3.5 Turbo et GPT-4 avec des textes de dix variétés, annotation des prompts et des sorties pour des caractéristiques linguistiques et de graphie afin de déterminer s’il imite ou non.
- Évaluation : des locuteurs natifs de chaque variété ont évalué les sorties selon chaleur, compréhension, naturalité, stéréotypes, contenu méprisant et condescendance.
- Conditions : comparaison entre sorties de base et sorties quand le modèle est invité à imiter le dialecte d’entrée.
- Résultats : les variations SAE vs non standard et entre dialectes montrent comment les caractéristiques de dialecte se propagent et sont perçues par les locuteurs.
- Implication pratique : les développeurs doivent intégrer des considérations de diversité linguistique lors de la formation et de l’évaluation pour réduire les risques de discrimination. paper.
Points clés
- Les modèles de langage démontrent des biais mesurables et systématiques contre les variétés non standards de l’anglais par rapport au SAE.
- L’ampleur du biais dépend de la tâche et de la version du modèle ; les modèles plus récents ne résolvent pas nécessairement le problème et peuvent parfois intensifier le stéréotype pour certaines dialectes.
- La composition des données d’entraînement influence le comportement du modèle vis-à-vis des dialectes non standards.
- Des sorties rétrodifférentes en fonction de la localisation (orthographe US vs UK) peuvent impacter l’accessibilité et l’adoption hors des États-Unis.
- À mesure que l’IA devient plus intégrée, traiter les biais linguistiques devient essentiel pour promouvoir l’équité et réduire les barrières pour les communautés linguistiques minoritaires.
FAQ
-
- **Q : Quelles variétés ont été testées ?**
SAE, SBE et huit dialectes non standards : anglais afro-américain, indien, irlandais, jamaïcain, kényan, nigérian, écossais et singapourien. [paper](http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias). - **Q : Comment les biais ont-ils été mesurés ?** **A :** Des prompts et des réponses ont été annotés sur des aspects linguistiques et graphiques; des locuteurs natifs ont noté chaleur, compréhension, naturalité, stéréotypes, contenu méprisant et condescendance. [paper](http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias). - **Q : Les modèles plus récents résolvent-ils le problème ?** **A :** GPT-4 présente des améliorations sur certains aspects mais augmente le stéréotype pour les dialectes minoritaires lorsqu’il imite, montrant que les modèles plus puissants ne résolvent pas automatiquement le biais. [paper](http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias). - **Q : Que peuvent faire les développeurs pour atténuer ceci ?** **A :** L’étude met en évidence le besoin de stratégies explicites de mitigation des biais, de diversification des données et d’adaptation des sorties selon le locale, pour réduire les discriminations dans des contextes multilingues. (Voir la source pour les détails.) [paper](http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias). - **Q : Pourquoi l’orthographe devient-elle américaine avec des entrées britanniques ?** **A :** L’étude signale un décalage entre les conventions de l’utilisateur et celles adoptées par le modèle, avec une tendance à revenir à l’orthographe américaine, ce qui peut frustrer les utilisateurs hors des États‑Unis. [paper](http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias).
Références
More news

Défense contre l’injection de prompts avec StruQ et SecAlign : requêtes structurées et optimisation des préférences
BAIR de Berkeley présente StruQ et SecAlign comme défenses contre l’injection de prompts dans les applications LLM, avec Front-End Sécurisé, stratégies d’entraînement et améliorations de robustesse.

PLAID : Réutiliser les modèles de pliage des protéines pour une génération multimodale par diffusion latente
PLAID réutilise des modèles de pliage des protéines pour générer à la fois la séquence et la structure 3D via une diffusion latente, facilitant la conception de protéines guidée par la fonction et l’organisme.

Échelonnement de l’Apprentissage par Renforcement pour l’Assouplissement du Trafic : Déploiement de 100 Véhicules Autonomes sur Autoroute
Cent véhicules contrôlés par RL sur une autoroute ont été déployés pour lisser le trafic, réduire la consommation de carburant et améliorer le débit, avec des économies d’énergie observées autour des véhicules contrôlés.

Anthology : des personnalités virtuelles pour les LLMs via des backstories riches
Le laboratoire BAIR de Berkeley présente Anthology, une méthode qui conditionne les LLMs à des personas virtuelles représentatifs, cohérents et divers en utilisant des narratifs de vie riches. L’approche est évaluée sur des enquêtes Pew et discute des implications, de l’éthique et des perspectives f

Comment évaluer les méthodes de jailbreak: étude de cas avec la référence StrongREJECT
Examen rigoureux des revendications de jailbreak, des limites des bancs existants et de la refonte de l’évaluation par StrongREJECT, qui mesure à la fois la volonté et la capacité des LLMs à répondre à des prompts interdits.

Visual Haystacks: Benchmark de raisonnement sur plusieurs images
Une analyse approfondie de Visual Haystacks (VHs), le premier benchmark NIAH centré sur l’image et le raisonnement sur long contexte dans de grands ensembles d’images non corrélées, ses conclusions et l’approche MIRAGE qui fait progresser le raisonnement par récupération pour des ensembles d’images