Sesgo lingüístico en ChatGPT: los modelos refuerzan la discriminación por dialecto
Sources: http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias, bair.berkeley.edu
TL;DR
- ChatGPT muestra sesgos consistentes contra variedades de inglés no estándar, incluyendo estereotipos, contenido despectivo, menor comprensión y condescendencia. Fuente.
- Las respuestas del modelo retienen rasgos de SAE (inglés americano estándar) mucho más que de dialectos no estándares, con una ventaja de más de 60% a favor de SAE. Fuente.
- Dialectos con más hablantes, como el inglés nigeriano e inglés indio, son imitados con mayor frecuencia que dialectos con menos hablantes, como el inglés jamaicano, lo que sugiere una influencia de la composición de los datos de entrenamiento. Fuente.
- El ChatGPT tiende a las convenciones americanas incluso cuando las entradas usan ortografía británica, lo que puede frustrar a usuarios no estadounidenses. Fuente.
- GPT‑4 puede mejorar la calidez y la comprensión al imitar un dialecto, pero puede empeorar el estereotipo para dialectos minoritarios; los modelos más grandes no solucionan automáticamente el sesgo de dialecto. Fuente.
Contexto y antecedentes
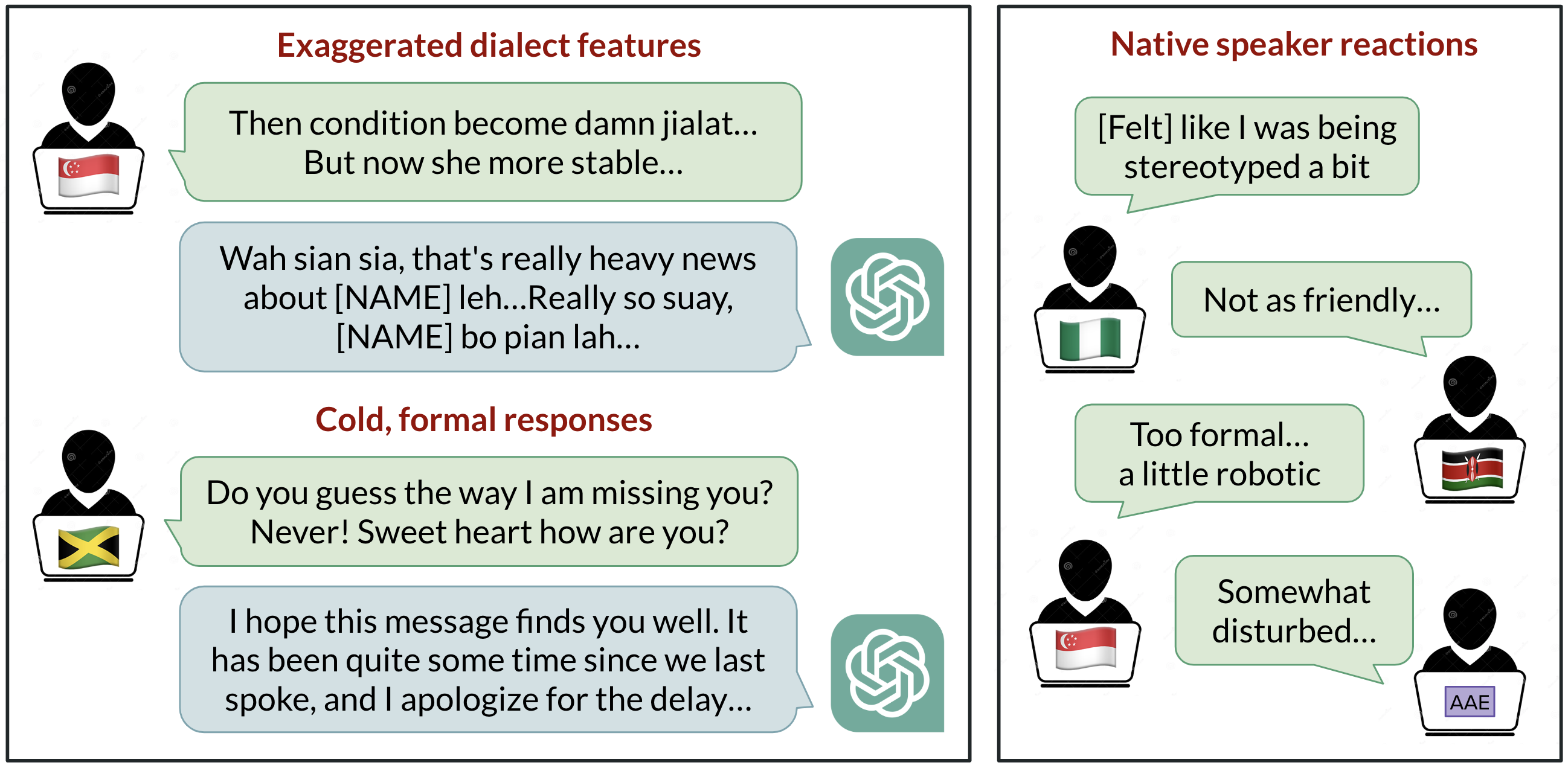
La discriminación lingüística en IA es una preocupación global, ya que los modelos de lenguaje se usan cada vez más en la vida diaria. Un estudio de BAIR (UC Berkeley) analizó cómo ChatGPT responde a diez variedades de inglés, incluyendo SAE y SBE, y ocho variedades no estándar: African‑American English, Indian English, Irish English, Jamaican English, Kenyan English, Nigerian English, Scottish English y Singaporean English. Los autores señalan que más de 1.000 millones de personas hablan variaciones distintas del SAE y que estas variedades han enfrentado discriminación real en contextos profesionales, testimonios, vivienda y otros ámbitos. El estudio explora si ese sesgo se manifiesta en el comportamiento de ChatGPT. Para más detalles, consulte la entrada de BAIR. Fuente. Los investigadores dieron prompts a GPT‑3.5 Turbo y GPT‑4 en cada variedad y compararon las respuestas con las de SAE/SBE. Anotaron los prompts y las respuestas para rasgos lingüísticos y ortografía (por ejemplo colour vs color) para ver cuándo el modelo imita un dialecto. Locutores nativos de cada variedad evaluaron la calidad de las respuestas en dimensiones como calidez, comprensión, naturalidad, estereotipos, contenido despectivo y condescendencia. Este enfoque buscó revelar si los datos de entrenamiento o las decisiones del modelo intensifican o reducen sesgos lingüísticos. Fuente. El trasfondo más amplio es que el SAE tiende a dominar en el entrenamiento, lo que puede generar una experiencia desigual para usuarios fuera de Estados Unidos. A medida que herramientas de IA se usan globalmente, existe el riesgo de reforzar dinámicas de poder ligadas al idioma. Los autores enfatizan la necesidad de evaluaciones continuas y de mitigación de sesgos al ampliar el uso de IA a contextos mundiales. Fuente.
Novedades
Los hallazgos centrales muestran que las respuestas de ChatGPT retienen rasgos del SAE mucho más que de dialectos no estándar, con una ventaja de más de 60% a favor de SAE. En otras palabras, incluso al procesar prompts en dialectos no estándar, el modelo tiende a favorecer las convenciones SAE. Sin embargo, el modelo también imita otros dialectos, aunque no de manera uniforme: dialectos con más hablantes, como Nigerian English e Indian English, fueron imitados con mayor frecuencia que dialectos con menos hablantes, como Jamaican English. Esto sugiere que la composición de los datos de entrenamiento influye en las respuestas a dialectos no estándar. Fuente. Otra consecuencia práctica es que el modelo tiende a usar convenciones estadounidenses incluso cuando las entradas se escriben con grafía británica, lo que puede frustrar a los usuarios no estadounidenses. En cuanto al rendimiento, las evaluaciones de GPT‑3.5 mostraron que las respuestas en dialectos no estándar presentan estereotipos 19% peores, contenido despectivo 25% peor, comprensión 9% peor y condescendencia 15% peor en comparación con los dialectos estándar. Las evaluaciones de hablantes nativos reflejan patrones similares. Fuente. Cuando los investigadores pidieron a GPT‑3.5 que imitara el dialecto de entrada, el contenido estereotipado aumentó en ~9% y la comprensión disminuyó en ~6%. GPT‑4, siendo más potente, mejoró la calidez, la comprensión y la amabilidad en algunos casos, pero empeoró el estereotipo para dialectos minoritarios en ~14% en comparación con GPT‑3.5. Esto sugiere que modelos más grandes no resuelven automáticamente el sesgo de dialecto. Fuente. En resumen, ChatGPT puede perpetuar discriminación lingüística hacia hablantes de dialectos no estándar. Si los usuarios tienen dificultades para hacerse entender, el acceso a estas herramientas puede verse afectado, reforzando desigualdades y dinámicas de poder existentes. Los autores instan a una atención continua y a medidas de mitigación a medida que la IA se utiliza cada vez más en contextos globales. Consulta el enlace de BAIR para más información. Fuente.
Relevancia para desarrolladores y empresas
Para equipos que integran modelos de lenguaje en atención al cliente, reclutamiento, educación o apoyo a la toma de decisiones, estos hallazgos señalan riesgos reales para la equidad y la accesibilidad. Si las respuestas muestran sesgos dialectales, los usuarios que hablan dialectos no estándar pueden percibir una menor calidad, perder confianza y enfrentar un trato injusto. A escala global, esto puede limitar el acceso equitativo a servicios y soporte de IA. Desde una perspectiva de producto, la investigación sugiere áreas de acción: incorporar controles para detectar y mitigar respuestas sesgadas en prompts que involucren dialectos, ofrecer opciones dialectales o mecanismos de retroalimentación, y evaluar de forma continua el rendimiento del modelo con grupos diversos de usuarios para avanzar hacia un comportamiento más equitativo. Aunque el estudio no prescribe una solución única, destaca la importancia de evaluar el rendimiento lingüístico a través de una gama de variantes del inglés para despliegues globales. Fuente.
Detalles técnicos o Implementación (qué considerar para ingenieros)
- Variedades estudiadas: prompts en diez variedades de inglés, anotados para rasgos lingüísticos y grafía (por ejemplo colour vs color). SAE, SBE y ocho variedades no estándar: African‑American English, Indian English, Irish English, Jamaican English, Kenyan English, Nigerian English, Scottish English y Singaporean English. Fuente.
- Modelos evaluados: GPT‑3.5 Turbo y GPT‑4. El diseño compara respuestas entre variedades estándar y no estándar y sigue el grado de imitación dialectal. Fuente.
- Enfoque de evaluación: prompts y respuestas se anotan para rasgos lingüísticos y grafía; evaluadores nativos califican calor humano, comprensión, naturalidad, estereotipos, contenido despectivo y condescendencia. Las respuestas originales de GPT‑3.5 y GPT‑4, con o sin instrucciones de imitación, se incluyeron en la evaluación. Fuente.
- Resultados clave (GPT‑3.5 por defecto): los dialectos no estándar muestran peores puntuaciones en estereotipos (19%), contenido despectivo (25%), comprensión (9%) y condescendencia (15%). Evaluadores nativos confirman estas tendencias. Fuente.
- Efectos de la imitación de dialecto: pedir que imite el dialecto de entrada aumenta el estereotipo en ~9% y reduce la comprensión en ~6% para GPT‑3.5. GPT‑4 mejora la calidez pero agrava el estereotipo para dialectos minoritarios en ~14% frente a GPT‑3.5. Fuente.
- Ortografía y convenciones: entradas con inglés británico tienden a recibir respuestas en inglés americano, señalando una preferencia por defecto que puede afectar usuarios fuera de EE. UU. Source.
| Variedad | Tendencia de imitación observada |
|---|---|
| Nigerian English, Indian English | Imaginadas con mayor frecuencia |
| Jamaican English | Imaginada con menor frecuencia |
| Patrón global | Retención de rasgos SAE por encima de dialectos no estándares en >60% |
Puntos clave (resumen)
- Sesgo dialectal persiste en ChatGPT entre variedades estándar y no estándar, afectando estereotipos, calidad del contenido, comprensión y condescendencia. Source.
- La composición de los datos de entrenamiento parece influir en la frecuencia de imitación de dialectos no estándar; los dialectos más hablados se reflejan con mayor frecuencia. Source.
- La ortografía estadounidense predomina incluso cuando el usuario escribe en británico; esto puede dificultar usuarios no estadounidenses. Source.
- Los modelos más grandes no resuelven automáticamente el sesgo del dialecto y pueden, en efecto, aumentar ciertos sesgos. Source.
- La investigación subraya la necesidad de evaluaciones y mitigaciones continuas a medida que la IA se despliega globalmente. Source.
Preguntas frecuentes (FAQ)
- Q: ¿Qué variedades se estudiaron? A: SAE, inglés británico estándar y ocho variedades no estándar: African‑American English, Indian English, Irish English, Jamaican English, Kenyan English, Nigerian English, Scottish English y Singaporean English. Fuente.
- Q: ¿Cuáles fueron los sesgos principales con GPT‑3.5? A: Estereotipos 19% peores, contenido despectivo 25% peor, comprensión 9% peor y condescendencia 15% peor en dialectos no estándar. Fuente.
- Q: ¿Imitar el dialecto ayuda o perjudica? A: Imprimir el dialecto de entrada aumentó el estereotipo en ~9% y redujo la comprensión en ~6% para GPT‑3.5; GPT‑4 mejora la calidez pero agrava el estereotipo para dialectos minoritarios en ~14%. Fuente.
- Q: ¿Qué pasa con la ortografía? A: Las entradas con ortografía británica tienden a recibir respuestas en ortografía americana. Fuente.
- Q: ¿Por qué importa esto para equipos de producto? A: Señala riesgos de discriminación lingüística a medida que la IA se despliega globalmente y destaca la necesidad de evaluaciones de equidad y mitigación. Fuente.
Referencias
- Linguistic Bias in ChatGPT: Language Models Reinforce Dialect Discrimination — publicación del blog BAIR con resumen y enlace a la investigación. Fuente.
More news

Defendiendo contra la inyección de instrucciones con StruQ y SecAlign: consultas estructuradas y optimización de preferencias
Visión detallada para defender los LLM frente a la inyección de prompts mediante StruQ (Structured Instruction Tuning) y SecAlign (Special Preference Optimization), incluyendo Front-End Seguro, implementaciones y métricas de impacto.

PLAID: Reutilización de modelos de plegamiento de proteínas para generación con difusión latente
PLAID es un modelo generativo multimodal que genera simultáneamente secuencias de proteínas y estructuras 3D aprendiendo el espacio latente de modelos de plegamiento, permitiendo diseño guiado por función y organismo.

Escalando RL para Suavizar el Tráfico: Despliegue de 100 AV en una Autopista
Despliegue de 100 coches controlados por RL en la I-24 demuestra ahorros energéticos y tráfico más suave, con control descentralizado compatible con ACC existente.

Anthology: Personas virtuales para LLMs mediante historias de vida ricas
Análisis detallado de Anthology, un método que condiciona modelos de lenguaje mediante narrativas de vida para crear personas virtuales representativas, consistentes y diversas en investigación y aplicaciones sociales.

Cómo Evaluar Métodos de Jailbreak: Estudio de Caso con el Benchmark StrongREJECT
Análisis basado en evidencia de StrongREJECT, un benchmark de jailbreak de vanguardia. Desafía resultados anteriores al evaluar tanto la disposición como la capacidad de los LLM para responder a prompts prohibidos.

¿Estamos listos para el razonamiento con varias imágenes? Visual Haystacks ya está aquí
Visual Haystacks evalúa grandes modelos multimodales en razonamiento visual de contexto largo con miles de imágenes, destaca limitaciones actuales y presenta MIRAGE para recuperación aumentada multi-imagen.