developer.nvidia.com
Réduire la latence de démarrage à froid pour l’inférence LLM avec NVIDIA Run:ai Model Streamer
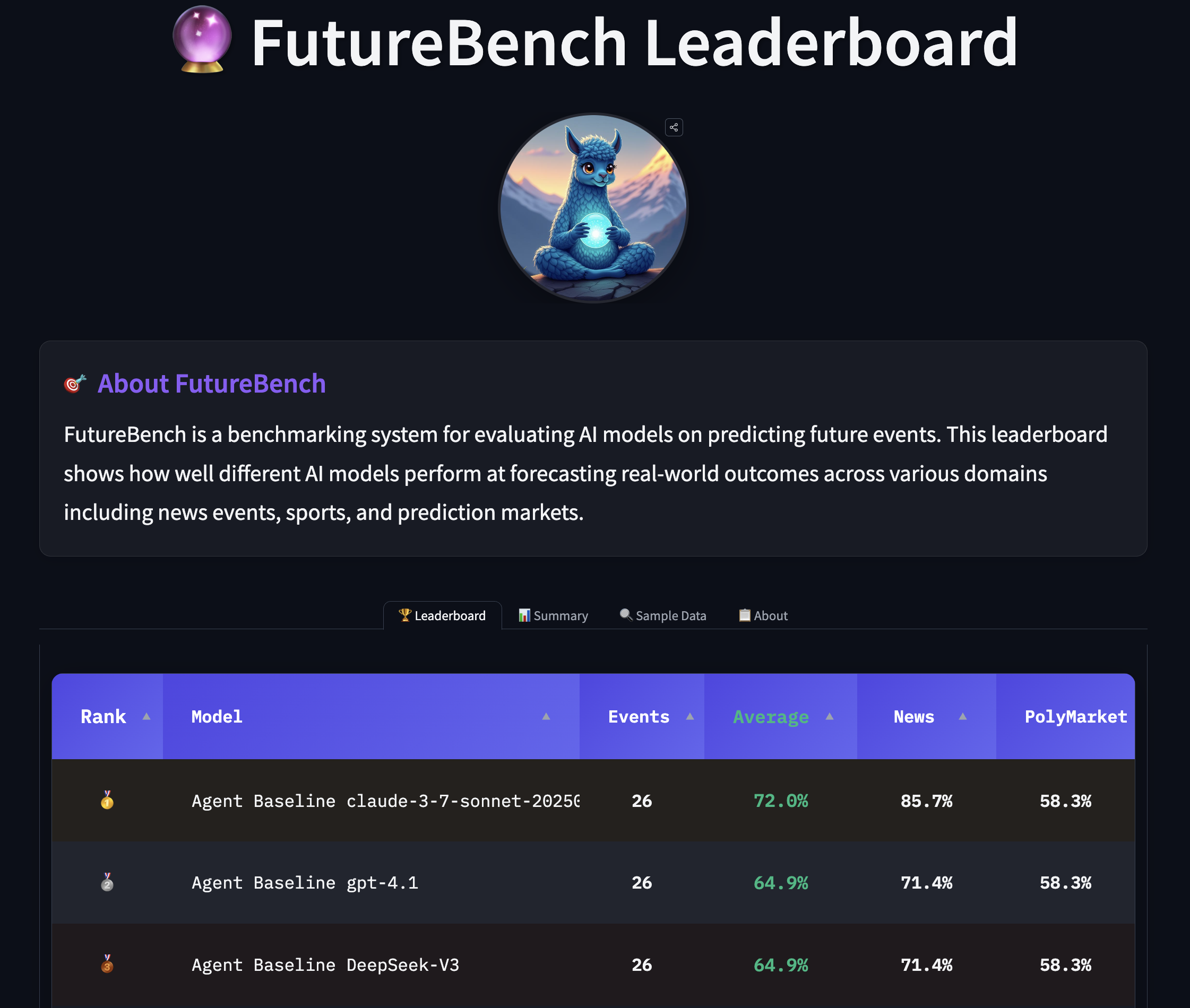
Analyse approfondie sur la façon dont NVIDIA Run:ai Model Streamer abaisse les temps de démarrage à froid pour l’inférence des LLM en diffusant les poids vers la mémoire GPU, avec des benchmarks sur GP3, IO2 et S3.