developer.nvidia.com
Reduciendo la latencia en frío para la inferencia de LLM con NVIDIA Run:ai Model Streamer
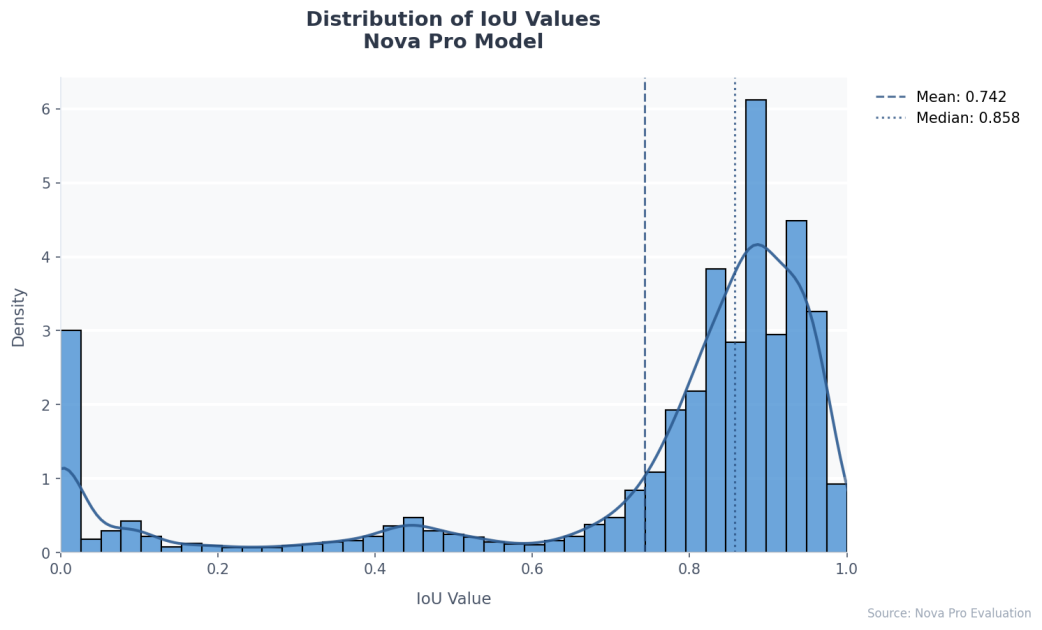
Análisis detallado de cómo NVIDIA Run:ai Model Streamer disminuye los tiempos de arranque en frío al transmitir pesos a la memoria GPU, con benchmarks en GP3, IO2 y S3.