
PLAID: Geração multimodal de proteínas por difusão latente
Sources: http://bair.berkeley.edu/blog/2025/04/08/plaid, http://bair.berkeley.edu/blog/2025/04/08/plaid/, BAIR Blog
Visão Geral
PLAID é um modelo gerativo multimodal que gera simultaneamente a sequência 1D de proteínas e a estrutura 3D, aprendendo o espaço latente de modelos de dobramento de proteínas. O trabalho contextualiza o papel cada vez maior da IA na biologia, citando o reconhecimento do AlphaFold2; pergunta o que vem depois da dobragem. PLAID aprende a amostrar do espaço latente de modelos de dobramento para gerar novas proteínas e pode responder a prompts compostos que especificam função e organismo. Importante: o treinamento pode ocorrer apenas com dados de sequência, uma vez que bases de dados de sequências são muito maiores que as de estruturas. A ideia central é fazer difusão no espaço latente de um modelo de dobramento em vez de difusão diretamente em espaço de sequências ou estruturas. Após amostrar esse espaço de proteínas válidas, o modelo decodifica sequência e estrutura usando pesos congelados de um modelo de dobramento. Na prática, PLAID utiliza o ESMFold — sucessor do AlphaFold2 que substitui uma etapa de recuperação por um modelo de linguagem de proteínas — como decodificador estrutural durante a inferência. Essa configuração aproveita priors aprendidos pelos modelos de dobramento pré-treinados para tarefas de design proteico, enquanto o treinamento utiliza apenas sequências. Um aspecto notável da abordagem é lidar com a alta dimensionalidade dos espaços latentes de modelos baseados em transformadores. Para lidar com isso, é proposto o CHEAP (Compressed Hourglass Embedding Adaptations of Proteins), que aprende um modelo de compressão para a incorporação conjunta de sequência e estrutura. Os autores encontram esse espaço latente fortemente compressível e, por meio de interpretabilidade, demonstram geração atômica completa em certos casos. Embora o foco seja geração sequência-estrutura, o método pode ser adaptado para geração multimodal em outros domínios onde exista um preditor de uma modalidade mais abundante para uma menos abundante. PLAID também oferece uma interface de controle por prompts, inspirada em como a geração de imagens é guiada por constraints textuais. O objetivo final é controle total por texto, mas a interface atual suporta restrições compostas em dois eixos: função e organismo. Os autores demonstram capacidades como aprender padrões de coordenação tetraédricos de metaloproteínas (por exemplo, ligação de cysteína-Fe2+/Fe3+) mantendo diversidade em nível de sequência. Comparações com baselines de estruturas atômicas mostram que PLAID tende a oferecer maior diversidade e capturar padrões de beta-helix com mais facilidade. Caso se tenha interesse em colaborar ou testar o método no wet-lab, os autores convidam contato. Eles também disponibilizam preprints e bases de código para PLAID e CHEAP, citando as referências.
Principais características
- Geração multimodal: co-criação de sequências e coordenadas estruturais atômicas
- Fluxo de difusão latente: amostra do espaço latente de um modelo de dobramento, depois decodifica
- Treinamento em sequências apenas: aproveita grandes bases de dados de sequências (2–4 ordens de magnitude maiores que as de estruturas)
- Decodificação com pesos congelados: a estrutura é decodificada a partir da embedding amostrada usando pesos congelados do ESMFold
- Compressão CHEAP: aprende uma compressão do embedding conjunto sequência-estrutura
- Prompts de função e organismo: controle por entradas compostas
- Interpretabilidade e motifização: análise de canais latentes e padrões emergentes (ex.: motivos de coordenação)
- Diversidade: amostras de PLAID mostram diversidade maior e melhor recaptura de motivos em comparação a alguns baselines
- Extensibilidade: abordagem pode ser adaptada para geração multimodal em domínios com preditor entre modalidades
- Integração com priors existentes: tira proveito de priors de modelos de dobramento pré-treinados
Casos de uso comuns
- Design de proteínas com função e organismo desejados (por exemplo, metalo proteínas com motivos ativos específicos)
- Exploração de espaços de design multimodais solicitando função ou espécie para direcionar a amostragem
- Geração de candidatos com sequência e estrutura diversificados que respeitem a relação função-estrutura aprendida pelo espaço latente
- Estender a geração multimodal para sistemas mais complexos (como complexos proteicos ou interações com ligantes ou ácidos nucleicos), aproveitando avanços em preditores de dobra
- Aproveitar grandes dados de sequência para treinar modelos que generalizam para geração de estruturas por meio de representações latentes
Configuração & Instalação
Não fornecido na fonte.
# Configuração e instalação não fornecidas na fonte.Quick start
Observação: este é um exemplo ilustrativo baseado nos princípios de PLAID; APIs e runtimes exatos dependem dos códigos liberados.
# PLAID quick-start (ilustrativo)
# Este exemplo mostra o fluxo pretendido, não é um código de execução pronto.
# 1) Amostra um embedding latente a partir do difusor
z = sample_latent_embedding()
# 2) Decode sequence e estrutura usando pesos congelados do ESMFold
sequence = decode_sequence_from_embedding(z)
structure = decode_structure_from_embedding(z, frozen_weights="ESMFold")
print(sequence)
print(structure)Prós e contras
- Prós
- Geração conjunta de sequência e estrutura com prompts funcionais/organizacionais
- Leva em conta bases de dados de sequência em grande escala, aproveitando dados abundantes
- Decodificação de estrutura com pesos congelados de dobramento, reduzindo necessidade de treinar módulos de estrutura
- CHEAP aborda compressão de representações conjuntas, tornando o modelo mais viável
- Demonstra controle por prompts compostos, com potencial para controle textual completo no futuro
- Evidencia diversidade e recaptura de motivos que alguns baselines têm dificuldade em capturar
- Contras
- Espaços latentes de transformadores podem ser grandes e exigir regularização
- O sucesso depende da qualidade dos priors de dobramento subjacentes e da compatibilidade entre sequências e estruturas
- A aplicabilidade prática depende de exposição a prompts funcionais/organismos variados e decodificação robusta de estruturas complexas
- A extensão para modalidades adicionais ainda é uma área ativa de desenvolvimento
Alternativas (comparação breve)
| Abordagem | Modalidade | Pontos fortes | Limitações |---|---|---|---| | PLAID | Sequência + estrutura | Geração multimodal com difusão latente; treino em sequências | Depende de um modelo de dobramento como backbone; qualidade depende da regularização latente |Geradores tradicionais de estrutura | Estrutura apenas | Realismo estrutural forte com priors de dobramento | Não gera sequência nem oferece controle multimodal explicitamente |Modelos apenas de sequência | Sequência apenas | Ampla cobertura de dados de sequência | Sem geração direta de coordenadas estruturais sem preditor adicional |
Licença ou Preços
Detalhes de licenciamento ou preços não são especificados na fonte.
Referências
- PLAID: Repurposing Protein Folding Models for Generation with Latent Diffusion — BAIR Blog, http://bair.berkeley.edu/blog/2025/04/08/plaid/
- Preprints e bases de código para PLAID e CHEAP são mencionados na fonte; URLs explícitos não foram fornecidos aqui.
More resources

Defending against Prompt Injection with Structured Queries (StruQ) and Preference Optimization (SecAlign)
Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks against them. Prompt injection attack is listed as the #1 threat by OWASP to LLM-integrated applications, where an LLM input contains a trusted prompt (ins

Dimensionando o RL para Suavização do Tráfego: Implantação de 100 VEs na Estrada
100 carros controlados por RL foram implantados na I-24 durante o horário de pico para diminuir ondas de paradas e arranques, melhorar o fluxo e reduzir o consumo de combustível para todos. Controle descentralizado com sensores de radar básicos.

Anthology: Condicionando LLMs com Backstories Ricas para Personas Virtuais
Um método para guiar LLMs rumo a personas virtuais representativas, consistentes e diversas, gerando narrativas de vida detalhadas usadas como contexto de condicionamento, com aplicações em simulações e pesquisas escaláveis.
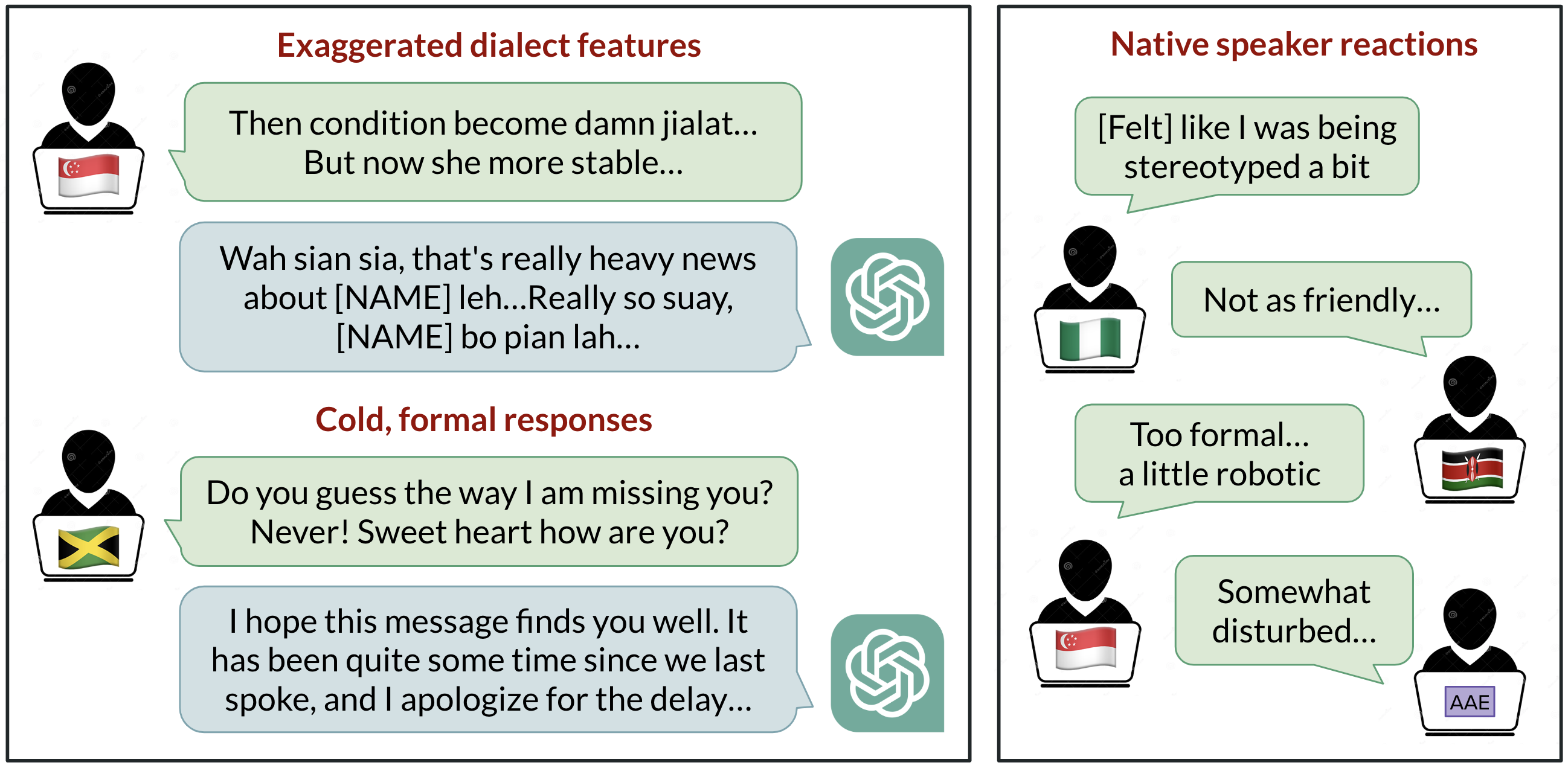
Viés Linguístico no ChatGPT: Discriminação por Dialeto entre Variantes do Inglês
Análise de como o ChatGPT responde a diferentes dialetos do inglês, destacando vieses contra variedades não padrão e suas implicações.

StrongREJECT: Benchmark robusto para avaliação de jailbreak em LLMs
Visão geral de um benchmark de jailbreak de alta qualidade com dois avaliadores automáticos, um conjunto de prompts proibidos e descobertas de que muitos jailbreaks não correspondem a reivindicações anteriores.

Visual Haystacks (VHs): Benchmark de Raciocínio Visual com Múltiplas Imagens
Benchmark de raciocínio visual em contexto longo entre grandes conjuntos de imagens não correlacionadas; introduz o MIRAGE para estender LMMs além de VQA com uma imagem.