
Dimensionando o RL para Suavização do Tráfego: Implantação de 100 VEs na Estrada
Sources: http://bair.berkeley.edu/blog/2025/03/25/rl-av-smoothing, http://bair.berkeley.edu/blog/2025/03/25/rl-av-smoothing/, BAIR Blog
Visão geral
Ondas de parada e vai-vém são comuns em tráfego de rodovias densas e levam ao desperdício de energia e a emissões mais altas. Pesquisadores implantaram 100 carros controlados por reforço (RL) em uma rodovia real (I-24 perto de Nashville) para aprender estratégias de condução que suavizem essas ondas, melhorando a eficiência energética e mantendo o fluxo próximo a motoristas humanos. A equipe construiu simulações rápidas e orientadas por dados, derivadas de dados experimentais de rodovias, para treinar agentes de RL a otimizar o uso de energia, mantendo a segurança. Uma descoberta-chave é que uma pequena fração de VEs bem controlados pode melhorar significativamente o fluxo de tráfego e reduzir o consumo de combustível para todos os motoristas. Os controladores são projetados para funcionar com hardware ACC padrão e operam de forma descentralizada usando apenas entrada de sensor básica disponível em veículos modernos. O projeto descreve o caminho do treinamento à implantação na prática, detalhando etapas para reduzir o gap entre simulação e mundo real. Os pesquisadores usaram dados de trajeto da I-24 para reproduzir tráfego instável na simulação, permitindo que os VEs aprendessem estratégias de suavização por trás do tráfego humano. A abordagem enfatiza a percepção local: as observações para o RL são a velocidade do VE, a velocidade do veículo à frente e o espaço entre eles. Com base nesses sinais, o agente prescreve uma aceleração instantânea ou uma velocidade desejada para o VE. A função de recompensa é criada para equilibrar eficiência energética, capacidade de fluxo e segurança, incluindo limiares dinâmicos mínimo e máximo de gap para evitar comportamentos inseguros. O design também penaliza o consumo de combustível dos motoristas humanos atrás do VE para desencorajar otimizações egoístas. Em simulação, o comportamento aprendido normalmente mantém gaps ligeiramente maiores que os humanos, permitindo que os VEs absorvam desacelerações futuras com mais eficácia. Nos cenários mais congestionados, as simulações indicaram economias de combustível de até ~20% para todos os usuários, com menos de 5% de penetração de VEs. Importante: os controladores RL foram projetados para funcionar com o ACC existente e podem operar de forma descentralizada, sem infraestrutura especial. Após a validação em simulação, a equipe implantou os controladores RL em campo no que chamaram de MegaVanderTest: um grande experimento com 100 veículos na I-24 durante horários de pico. A coleta de dados utilizou câmeras de مش overhead para reconstruir milhões de trajetórias de veículos, permitindo uma análise detalhada de dinâmica de tráfego e uso de energia.
Principais características
- Treinamento de RL com dados em simulações rápidas e realistas, baseadas em dados reais de rodovias.
- Observações locais: velocidade do VE, velocidade do veículo à frente e gap entre eles.
- Recompensa que equilibra eficiência energética, throughput e segurança; limiares dinâmicos de gap para evitar comportamentos inseguros.
- Implantação descentralizada compatível com hardware ACC padrão e sensores de radar; não requer infraestrutura nova.
- Validação em larga escala (MegaVanderTest): 100 veículos durante horários de pico da manhã com milhões de trajetórias.
- Economias de energia relatadas de ~15–20% em cenários congestionados; redução na variância de velocidade/aceleração como proxy de abrandamento de ondas.
- Observado que seguir de perto os VEs pode reduzir o consumo de energia em tráfego a jusante e diminuir o traço de congestionamento.
- Evidências de ganhos potenciais com simulações mais rápidas, modelos melhores de condutores humanos e exploração de coordenação via 5G.
- O teste de campo ocorreu sem comunicação explícita entre VEs, alinhado com implantações atuais de veículos autônomos.
- Implementação integrada com sistemas ACC existentes para viabilidade em escala.
Casos de uso comuns
- Suavizar tráfego e reduzir consumo de combustível em rodovias congestionadas com mudanças mínimas de infraestrutura.
- Implantar controladores de suavização baseados em RL em VEs existentes com ACC para ampliar os benefícios de energia.
- Compartilhar conhecimento entre simulação e mundo real em pesquisas de tráfego deautonomia com diferentes níveis de autonomia.
- Explorar modelos humanos de condução com dados para melhorar fidelidade e robustez.
Configuração e instalação
A fonte descreve o treinamento de agentes RL em simulações rápidas usando dados reais, validação em hardware e implantação em 100 veículos, mas não fornece comandos de configuração específicos. Não há passos de linha de comando apresentados.
# Configuração não fornecida na fonteQuick start
A fonte apresenta um roteiro de alto nível, sem código executável ou um quickstart pronto:
- Construir simulações rápidas baseadas em trajetórias reais.
- Treinar agentes RL para otimizar uso de energia mantendo throughput e segurança próximo a motoristas humanos.
- Validar em hardware e, em seguida, implantar em uma frota de VEs.
- Coletar e analisar dados de campo para quantificar economias de energia e suavização do tráfego.
# Quick start não fornecido pela fonteVantagens e desvantagens
- Vantagens
- Demonstra controle descentralizado que pode ser implantado em VEs padrão sem infraestrutura nova.
- Evidência de economias de energia significativas (15–20%) ao redor dos VEs controlados na prática.
- MegaVanderTest representa um dos maiores experimentos de tráfego misto já realizados.
- Compatível com sistemas ACC existentes; utiliza sensoriamento por radar.
- Observações de redução na variância de velocidade e aceleração indicam amortecimento das ondas de tráfego.
- Desvantagens
- O desafio de transitar do sim para a realidade continua; é necessário simulações mais rápidas, modelos humanos melhores e maior fidelidade.
- Ganhos futuros podem depender de comunicação explícita entre VEs (p. ex., 5G), o que não foi empregado no teste.
- O design da recompensa requer equilíbrio cuidadoso para evitar comportamentos inseguros; os limiares dinâmicos ajudam a mitigar isso.
Alternativas (comparações rápidas)
| Abordagem | Traços-chave | Prós | Contras |---|------|------|------| | Controle via ramp metering / infraestrutura | Gestão centralizada por infraestrutura de tráfego | Pode moldar o tráfego em escala de rede sem depender da penetração de AVs | Requer infraestrutura, coordenação e investimento; efeito limitado se a penetração de AVs for baixa |Limites de velocidade variáveis | Controle de velocidade na via por infraestrutura | Política simples que pode reduzir ondas de paradas | Precisa de sensores/comunicação; adaptação limitada a tráf. com aut. mista |Suavização com RL em VEs (este trabalho) | Controle descentralizado a nível de veículo com observações locais | Escala com adoção de veículos; não depende de infraestrutura nova; utiliza hardware ACC existente | Desafios de sim-to-real; benefícios dependem da penetração de VEs; resultados de campo dependem do comportamento de motoristas atrás dos VEs |
Licença ou preço
Não especificado na fonte.
Referências
More resources

NVIDIA NeMo-RL Megatron-Core: Aumento de Desempenho de Treinamento
Visão geral do NeMo-RL v0.3 com suporte ao Megatron-Core para pós-treinamento de grandes modelos, incluindo paralelismo 6D/4D, núcleos CUDA otimizados e configuração simplificada para aumentar a taxa de treinamento em RL.

Defending against Prompt Injection with Structured Queries (StruQ) and Preference Optimization (SecAlign)
Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks against them. Prompt injection attack is listed as the #1 threat by OWASP to LLM-integrated applications, where an LLM input contains a trusted prompt (ins

PLAID: Geração multimodal de proteínas por difusão latente
PLAID gera simultaneamente sequência 1D de proteína e estrutura 3D aprendendo o espaço latente de modelos de dobramento de proteínas. Suporta prompts de função e organismo e decodifica a estrutura com pesos congelados do modelo de dobramento.

Anthology: Condicionando LLMs com Backstories Ricas para Personas Virtuais
Um método para guiar LLMs rumo a personas virtuais representativas, consistentes e diversas, gerando narrativas de vida detalhadas usadas como contexto de condicionamento, com aplicações em simulações e pesquisas escaláveis.
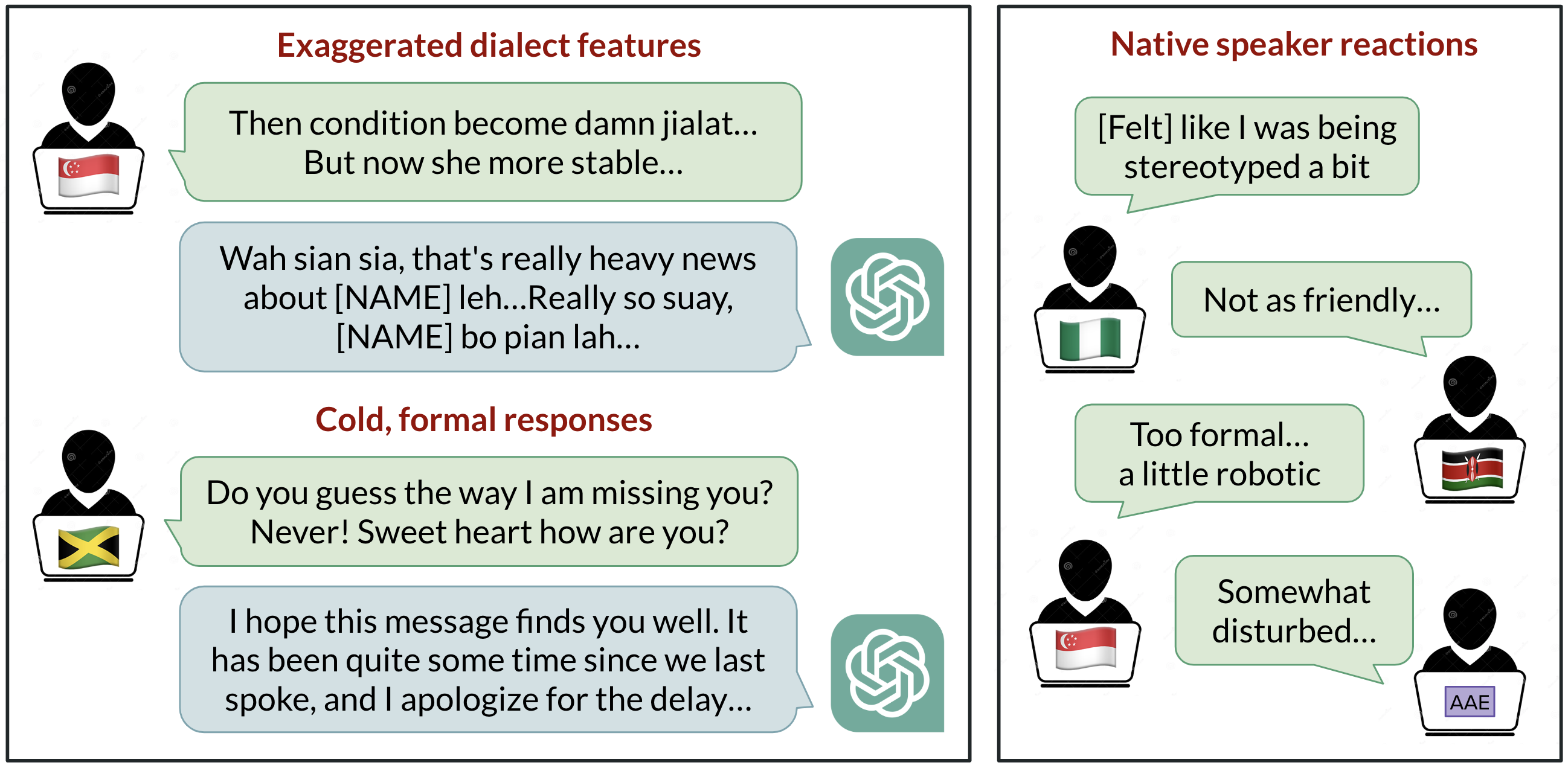
Viés Linguístico no ChatGPT: Discriminação por Dialeto entre Variantes do Inglês
Análise de como o ChatGPT responde a diferentes dialetos do inglês, destacando vieses contra variedades não padrão e suas implicações.

StrongREJECT: Benchmark robusto para avaliação de jailbreak em LLMs
Visão geral de um benchmark de jailbreak de alta qualidade com dois avaliadores automáticos, um conjunto de prompts proibidos e descobertas de que muitos jailbreaks não correspondem a reivindicações anteriores.