Viés Linguístico no ChatGPT: Discriminação por Dialeto entre Variantes do Inglês
Sources: http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias, http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/, BAIR Blog
Visão geral
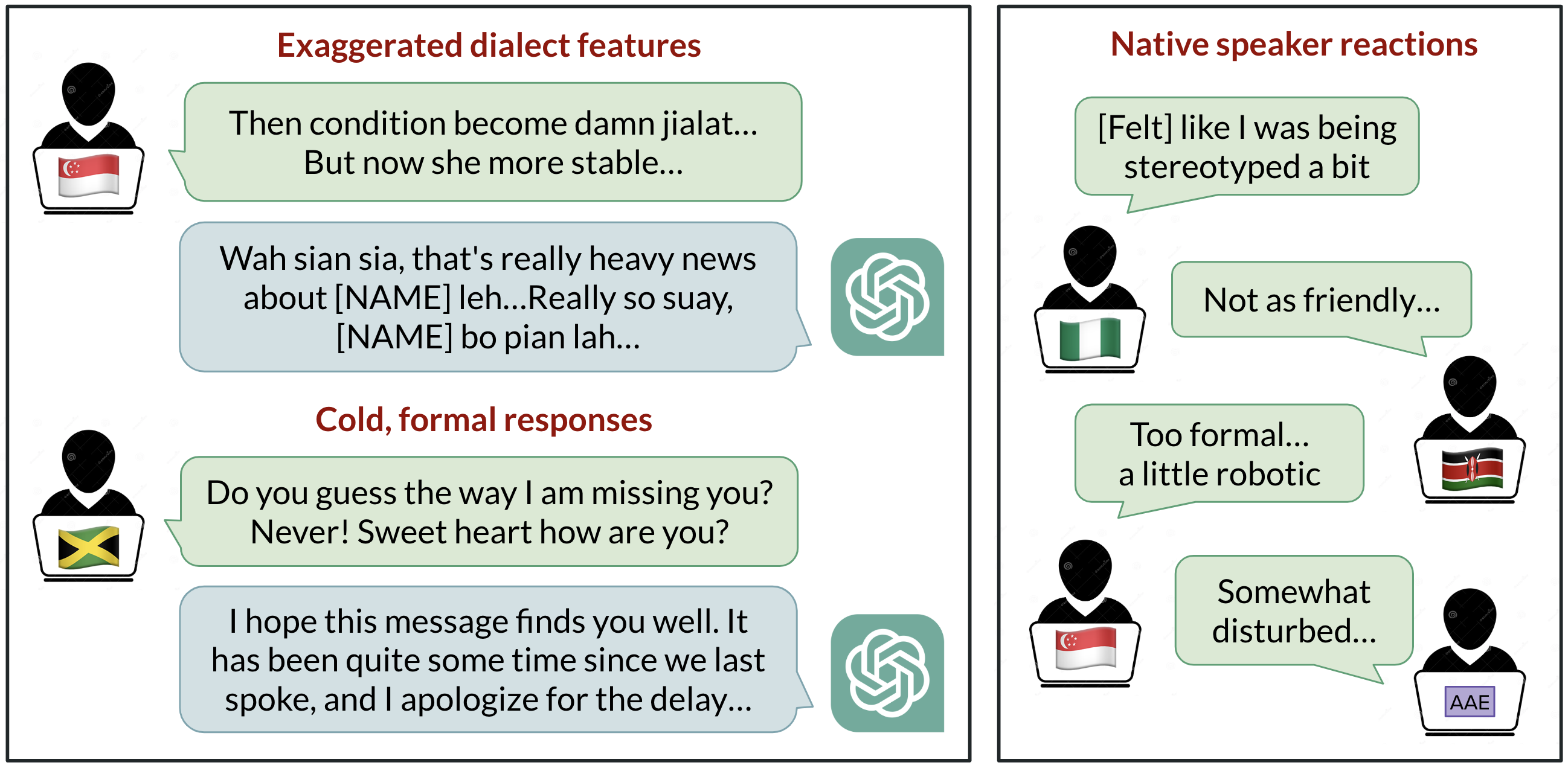
ChatGPT é amplamente utilizado para comunicação em inglês, mas de que inglês se trata como padrão? O desenvolvimento com foco nos EUA tradicionalmente posiciona o inglês americano padrão como o padrão, porém usuários ao redor do mundo falam mais de um bilhão de variedades, como inglês indiano, inglês nigeriano, inglês irlandês e inglês afro-americano. Esta síntese de pesquisa investiga como o ChatGPT se comporta quando recebe prompts em dez variedades de inglês, revelando vieses consistentes contra dialetos não padrão, incluindo estereótipos, conteúdo desdenhoso, compreensão inferior e respostas condescendentes. Os achados destacam que os modelos refletem a composição dos dados de treinamento e que apenas aumentar o tamanho ou a capacidade do modelo não resolve automaticamente a discriminação por dialetos. O estudo solicitou ao GPT-3.5 Turbo e ao GPT-4 textos de dez variedades: duas variedades padrão (Standard American English SAE e Standard British English SBE) e oito não padrão (inglês africano-americano, indiano, irlandês, jamaicano, queniano, nigeriano, escocês e de Cingapura). Comparamos saídas do modelo entre variedades padrão e não padrão para observar traços de imitação de dialeto e avaliações de falantes nativos. Observações-chave: as respostas do modelo retêm traços do SAE muito mais do que de dialetos não padrão (margem superior a 60%). Ainda assim, o modelo imita outras variedades de forma inconsistente; dialetos com mais falantes (inglês nigeriano e indiano) foram imitadas com maior frequência do que dialetos com menos falantes (inglês jamaicano), sugerindo que a composição dos dados de treino molda o comportamento de dialeto. Observa-se também que o chat revert o uso de grafias britânicas para o padrão americano, mesmo quando a entrada usa grafia inglesa de outros países. Avaliações de falantes nativos mostram vieses: dialetos não padrão costumam apresentar estereotipação, conteúdo desdenhoso, menor compreensão e condescendência em comparação com dialetos padrão. Quando o GPT-3.5 é instruído a imitar o dialeto de entrada, conteúdos estereotipados tendem a piorar. O GPT-4, apesar de oferecer melhorias de calor humano, compreensão e cordialidade ao imitar, pode piorar a estereotipia para dialetos minoritários. Em resumo, modelos maiores não resolvem automaticamente o problema de discriminação por dialeto e, em alguns casos, podem agravar a questão. À medida que ferramentas de IA ganham uso global, há risco de reforçar dinâmicas de poder associadas a comunidades linguísticas minoritárias, caso não haja abordagens explícitas de mitigação.
Principais recursos
- Retenção de recursos do SAE muito maior que de dialetos não padrão (margem >60%).
- Imitação de dialetos não padrão é inconsistente; dialetos com mais falantes são imitadas com maior frequência.
- Tendência de converter grafias britânicas para o padrão americano, causando atritos com convenções locais.
- Prompts para imitar dialeto não padrão aumentam estereotipação, desmerecimento e falhas de compreensão em GPT-3.5.
- GPT-4 pode melhorar calor humano e compreensão ao imitar, porém pode acentuar estereotipia para dialetos minoritários.
- Evidências de que dados de treino influenciam o comportamento do modelo e, por consequência, a experiência do usuário global.
Casos de uso comuns
- Pesquisas acadêmicas sobre viés linguístico e discriminação por dialeto em IA.
- Avaliação de justiça e inclusão em sistemas de NLP para uso multilíngue ou multinacional.
- Desenvolvimento de protocolos de avaliação para mensurar o tratamento de dialetos e vieses indesejados.
- Informar políticas e discussões éticas sobre implantações de IA em diferentes comunidades linguísticas.
- Orientar a elaboração de prompts e design de interfaces para melhor acomodar variedades do inglês não padrão.
Configuração e instalação
# Baixar o artigo para leitura off-line
curl -L -o linguistic_bias.html "http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/"# Opcional: transformar em Markdown se o pandoc estiver instalado
pandoc linguistic_bias.html -t markdown -o linguistic_bias.mdQuick start
import urllib.request
# Exemplo mínimo executável: buscar e imprimir a primeira porção do artigo
url = "http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/"
with urllib.request.urlopen(url) as resp:
html = resp.read().decode()
print(html[:1000])Prós e contras
- Prós
- Evidencia vieses de comportamento do modelo entre dialetos.
- Estimula discussão sobre justiça em NLP multilíngue e com várias variedades.
- Indica que modelos maiores não resolvem automaticamente discriminação por dialeto.
- Contras
- Dialetos não padrão podem ser prejudicados nos resultados do modelo.
- Fricção entre grafias britânicas e americanas pode frustrar usuários fora dos EUA.
- Resultados dependem da composição dos dados de treino e de estratégias de prompting.
Alternativas (comparações breves)
| Modelo | Efeitos observados no tratamento de dialetos |
|---|---|
| GPT-3.5 Turbo | Retém traços do SAE de forma acentuada; imita dialetos não padrão de forma inconsistente; estereotipia e compreensão menor são mais pronunciadas para prompts não padrão. |
| GPT-4 | Imitação pode melhorar calor humano e compreensão; porém pode aumentar a estereotipia para dialetos minoritários. |
| Essas observações sugerem trade-offs entre fidelidade ao dialeto de entrada e riscos de reforçar estereótipos; a escolha do modelo e as estratégias de prompting influenciam a experiência do usuário com variedades de inglês. |
Pricing ou Licença
Não especificado na fonte.
Referências
More resources

Defending against Prompt Injection with Structured Queries (StruQ) and Preference Optimization (SecAlign)
Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks against them. Prompt injection attack is listed as the #1 threat by OWASP to LLM-integrated applications, where an LLM input contains a trusted prompt (ins

PLAID: Geração multimodal de proteínas por difusão latente
PLAID gera simultaneamente sequência 1D de proteína e estrutura 3D aprendendo o espaço latente de modelos de dobramento de proteínas. Suporta prompts de função e organismo e decodifica a estrutura com pesos congelados do modelo de dobramento.

Dimensionando o RL para Suavização do Tráfego: Implantação de 100 VEs na Estrada
100 carros controlados por RL foram implantados na I-24 durante o horário de pico para diminuir ondas de paradas e arranques, melhorar o fluxo e reduzir o consumo de combustível para todos. Controle descentralizado com sensores de radar básicos.

Anthology: Condicionando LLMs com Backstories Ricas para Personas Virtuais
Um método para guiar LLMs rumo a personas virtuais representativas, consistentes e diversas, gerando narrativas de vida detalhadas usadas como contexto de condicionamento, com aplicações em simulações e pesquisas escaláveis.

StrongREJECT: Benchmark robusto para avaliação de jailbreak em LLMs
Visão geral de um benchmark de jailbreak de alta qualidade com dois avaliadores automáticos, um conjunto de prompts proibidos e descobertas de que muitos jailbreaks não correspondem a reivindicações anteriores.

Visual Haystacks (VHs): Benchmark de Raciocínio Visual com Múltiplas Imagens
Benchmark de raciocínio visual em contexto longo entre grandes conjuntos de imagens não correlacionadas; introduz o MIRAGE para estender LMMs além de VQA com uma imagem.