TinyAgent: Chamadas de Função na Borda para Modelos de Linguagem Pequenos
Sources: http://bair.berkeley.edu/blog/2024/05/29/tiny-agent, http://bair.berkeley.edu/blog/2024/05/29/tiny-agent/, BAIR Blog
Visão geral
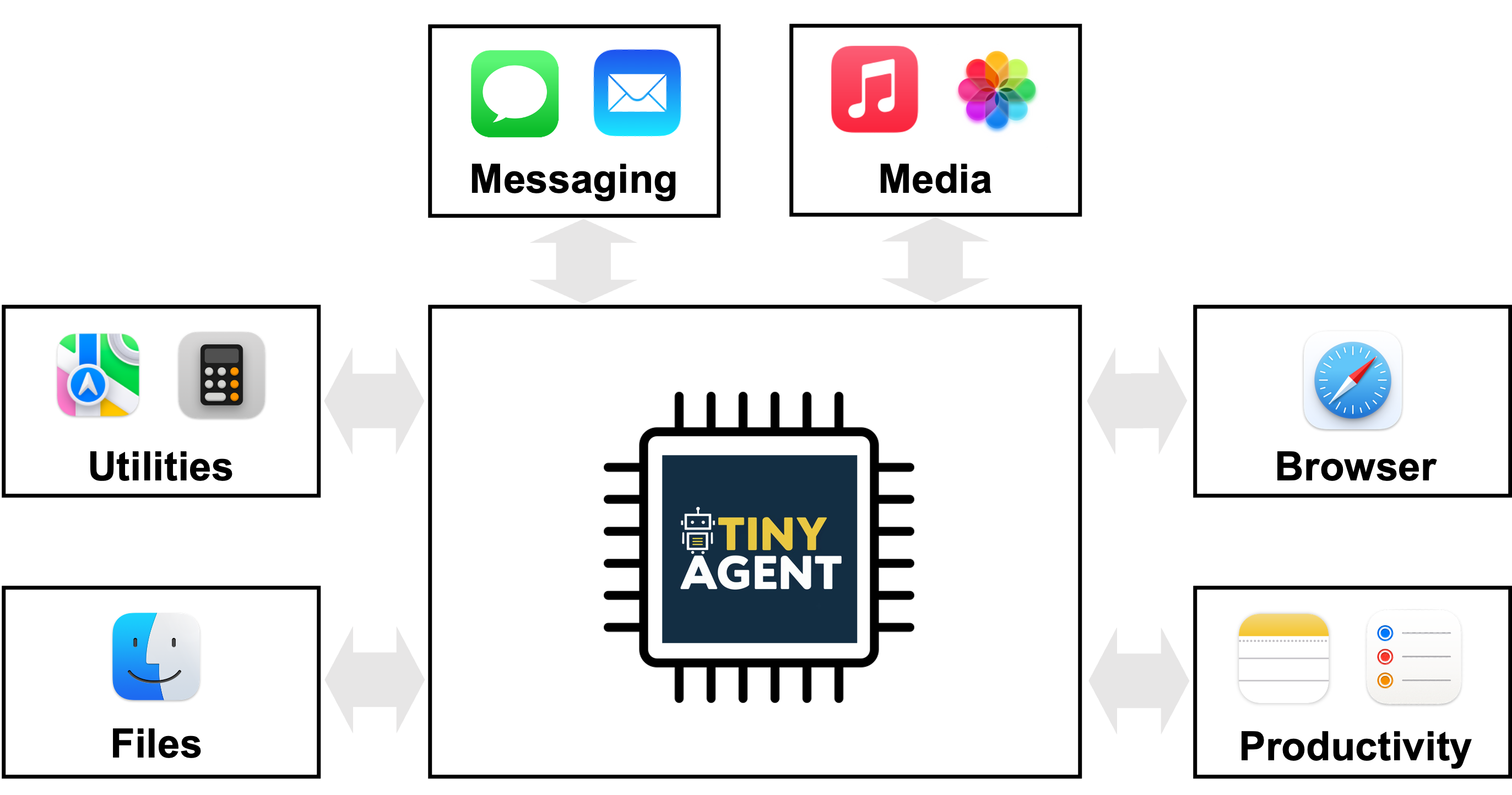
TinyAgent apresenta um caminho para implantar agentes com modelos de linguagem capazes em dispositivos de borda, ao enfatizar a chamada de funções em vez da memorização de conhecimento geral. Modelos grandes como GPT-4o ou Gemini-1.5 oferecem capacidades fortes via nuvem, mas apresentam desafios de privacidade, conectividade e latência quando implantados na borda. TinyAgent sustenta que, treinando modelos de linguagem pequenos (SLMs) com dados especializados e de alta qualidade que enfatizam chamada de funções e orquestração de ferramentas, é possível alcançar desempenho robusto em tempo real na borda sem depender de inferência remota. O projeto foca na ideia de que muitas tarefas de agente envolvem simplesmente selecionar a sequência correta de funções predefinidas com as entradas certas e a ordem correta, em vez de recordar informações do mundo. Para viabilizar isso, a equipe introduz um pipeline baseado em um planejador de chamadas de funções e um conjunto de dados de alta qualidade que orienta os SLMs a gerar planos executáveis, em vez de texto livre. A chave da abordagem é o framework LLMCompiler, que orienta o modelo a emitir um plano de chamada de função—identificando quais funções chamar, quais entradas são necessárias e as dependências entre as chamadas. Após gerar o plano, o sistema o analisa e executa as funções na ordem de dependência. A pergunta de pesquisa original questiona se modelos menores, de código aberto, podem aprender a realizar chamadas de função confiáveis com dados direcionados, alcançando capacidades de raciocínio e orquestração de ferramentas a nível de edge. O estudo TinyAgent demonstra essas ideias em um contexto de aplicação de MacOS. A plataforma expõe 16 funções predefinidas que interfaceiam com aplicações do macOS por meio de scripts Apple. A tarefa do modelo é compor um plano de chamada de função correto que utilize esses scripts para realizar os objetivos do usuário (por exemplo, criar um convite de calendário sem expor o usuário a respostas genéricas tipo Q&A). Os autores também exploram a geração de dados e estratégias de ajuste fino para reduzir a lacuna entre modelos pequenos e baselines maiores baseados na nuvem. Dados sintéticos são criados com um modelo capaz (por exemplo, GPT-4-Turbo) para produzir consultas realistas de usuário, planos de chamada de função e argumentos de entrada, seguidos por verificações de sanidade para garantir que os planos resultantes formem grafos válidos. O estudo reporta a construção de 80 mil exemplos de treinamento, 1 mil de validação e 1 mil de teste, com um custo total de geração de dados de cerca de US$ 500. Uma métrica baseada em DAG avalia a isomorfia entre o plano gerado e o plano de referência. O TinyAgent-1B, emparelhado com Whisper-v3 para voz no dispositivo, é demonstrado em um MacBook M3 Pro. O framework é de código aberto e está disponível no repositório oficial do projeto. Em síntese, o TinyAgent avança um caminho prático para agentes de borda: prioriza a chamada de funções correta em vez de memorização de conhecimento geral, usa um planejador explícito de orquestração de ferramentas e demonstra implantação de ponta a ponta no edge com um caso de uso prático em macOS.
Principais características
- Modelos de linguagem pequenos, de código aberto, capazes de realizar chamadas de função com treino adequado
- Framework LLMCompiler que produz um plano de chamada de função com funções, entradas e dependências
- Fluxo de geração de dados de alta qualidade (80k de treino, 1k de validação, 1k de teste) usando um LLM capaz, permitindo planejamento específico de tarefas
- Caminho de fine-tuning para melhorar o desempenho de chamadas de função por SLMs, potencialmente superando baselines maiores
- Método Tool RAG proposto para melhorar eficiência e desempenho
- Foco em implantação na borda: inferência local no dispositivo para privacidade e baixo atraso
- 16 funções pré-definidas para macOS que se conectam a scripts Apple
- Demonstração com TinyAgent-1B e Whisper-v3 rodando localmente em um MacBook M3 Pro
- Disponibilidade de código-fonte aberto no repositório oficial
Casos de uso comuns
- Assistentes semânticos na borda que interpretam comandos em linguagem natural e orquestram uma sequência de chamadas de ferramentas locais (por exemplo, calendário, contatos, e-mail) sem expor dados para a nuvem
- Fluxos de trabalho tipo Siri onde o agente converte comandos em invocações precisas de APIs ou scripts (por exemplo, criar convites de calendário com participantes específicos) usando scripts pré-definidos
- Cenários de automação privada no dispositivo, com minimização da exposição de dados
- Agentes habilitados para borda que operam em ambientes com conectividade intermitente ou inexistente, mantendo reatividade
Setup & instalação
Os detalhes de configuração e instalação não são fornecidos na fonte. O trabalho é apresentado como código aberto, e o repositório está disponível em:
- https://github.com/SqueezeAILab/TinyAgent Para leitores que buscam passos práticos, consulte o repositório para instruções de instalação, dependências e exemplos de uso. O material de origem enfatiza a arquitetura, o fluxo de geração de dados e o caso de uso de implantação na borda, em vez de um guia de configuração passo a passo.
Setup e instalação não são especificados na fonte fornecida.
Consulte o repositório para instruções: https://github.com/SqueezeAILab/TinyAgentQuick start (exemplo mínimo executável)
O fluxo descrito centra-se em traduzir uma solicitação em linguagem natural para um plano de chamadas de função e, em seguida, executá-las na ordem correta. Um quick start de alto nível com base na abordagem descrita pode ser assim (fluxo pseudo):
- O usuário fornece um comando em linguagem natural (por exemplo, “Crie um convite de calendário com os participantes A e B para a próxima terça-feira às 15h”).
- O planejador baseado em LLMCompiler produz um plano de chamada de função que lista quais funções chamar, quais argumentos de entrada (por exemplo, e-mails dos participantes, título do evento, data/hora) e as dependências entre as chamadas.
- O sistema executa cada função na ordem, substituindo valores reais nos espaços reservados (ex.: $1, $2) conforme os resultados de chamadas anteriores ficam disponíveis.
- O resultado final é a criação do item de calendário, com as entradas validadas pelos scripts pré-definidos do macOS. Observação: o fluxo acima descreve o funcionamento pretendido na fonte. Não é um script executável fornecido no material; consulte o repositório TinyAgent para detalhes de implementação, definições de funções e pontos de integração com o macOS.
Prós e contras
- Prós
- Implantação em borda com privacidade, mantendo a inferência no dispositivo
- Potencial redução da dependência de conectividade com a nuvem e latência mais baixa
- Aprendizado direcionado por dados curados de alta qualidade para chamadas de função
- Demonstra a capacidade de superar uma referência forte em chamadas de função para modelos pequenos
- Caminho claro para escalabilidade de agentes na borda por meio de uma abordagem explícita de orquestração de ferramentas
- Contras (conforme estudo)
- Modelos pequenos fora da caixa exibem desempenho limitado em chamadas de função sem ajuste fino específico
- Requer dados curados de alta qualidade e um processo cuidadoso de geração de dados para alcançar resultados robustos
- Os resultados se concentram num caso de uso específico com 16 funções pré-definidas, o que pode limitar a generalização para domínios diferentes
- Custos de geração de dados e avaliação de planos (sanidade, verificação de grafos) não são triviais na prática
Alternativas (comparações breves)
- Modelos grandes com inferência na nuvem (ex.: GPT-4/GPT-4o): oferecem forte capacidade de chamada de função, mas levantam questões de privacidade e conectividade; geralmente dependem de grande memória paramétrica e acesso à nuvem
- ToolFormer e Gorilla: exemplos citados como abordagens relacionadas para habilitar o uso de ferramentas por LLMs em cenários de agentes
- Abordagens baseadas em LLaMA-2 70B: trabalhos anteriores que consideraram chamadas de função com modelos grandes; TinyAgent investiga se modelos menores podem alcançar capacidades similares com dados curados e ajuste fino
- Tool RAG: otimização proposta para melhorar a eficiência e o desempenho no fluxo de chamadas de função
Pricing ou Licença
- O framework é descrito como código aberto; termos de licenciamento explícitos não são fornecidos na fonte. O custo de uso não é especificado.
Referências
- TinyAgent blog post: http://bair.berkeley.edu/blog/2024/05/29/tiny-agent/
- TinyAgent GitHub repository: https://github.com/SqueezeAILab/TinyAgent
More resources

Defending against Prompt Injection with Structured Queries (StruQ) and Preference Optimization (SecAlign)
Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks against them. Prompt injection attack is listed as the #1 threat by OWASP to LLM-integrated applications, where an LLM input contains a trusted prompt (ins

PLAID: Geração multimodal de proteínas por difusão latente
PLAID gera simultaneamente sequência 1D de proteína e estrutura 3D aprendendo o espaço latente de modelos de dobramento de proteínas. Suporta prompts de função e organismo e decodifica a estrutura com pesos congelados do modelo de dobramento.

Dimensionando o RL para Suavização do Tráfego: Implantação de 100 VEs na Estrada
100 carros controlados por RL foram implantados na I-24 durante o horário de pico para diminuir ondas de paradas e arranques, melhorar o fluxo e reduzir o consumo de combustível para todos. Controle descentralizado com sensores de radar básicos.

Anthology: Condicionando LLMs com Backstories Ricas para Personas Virtuais
Um método para guiar LLMs rumo a personas virtuais representativas, consistentes e diversas, gerando narrativas de vida detalhadas usadas como contexto de condicionamento, com aplicações em simulações e pesquisas escaláveis.
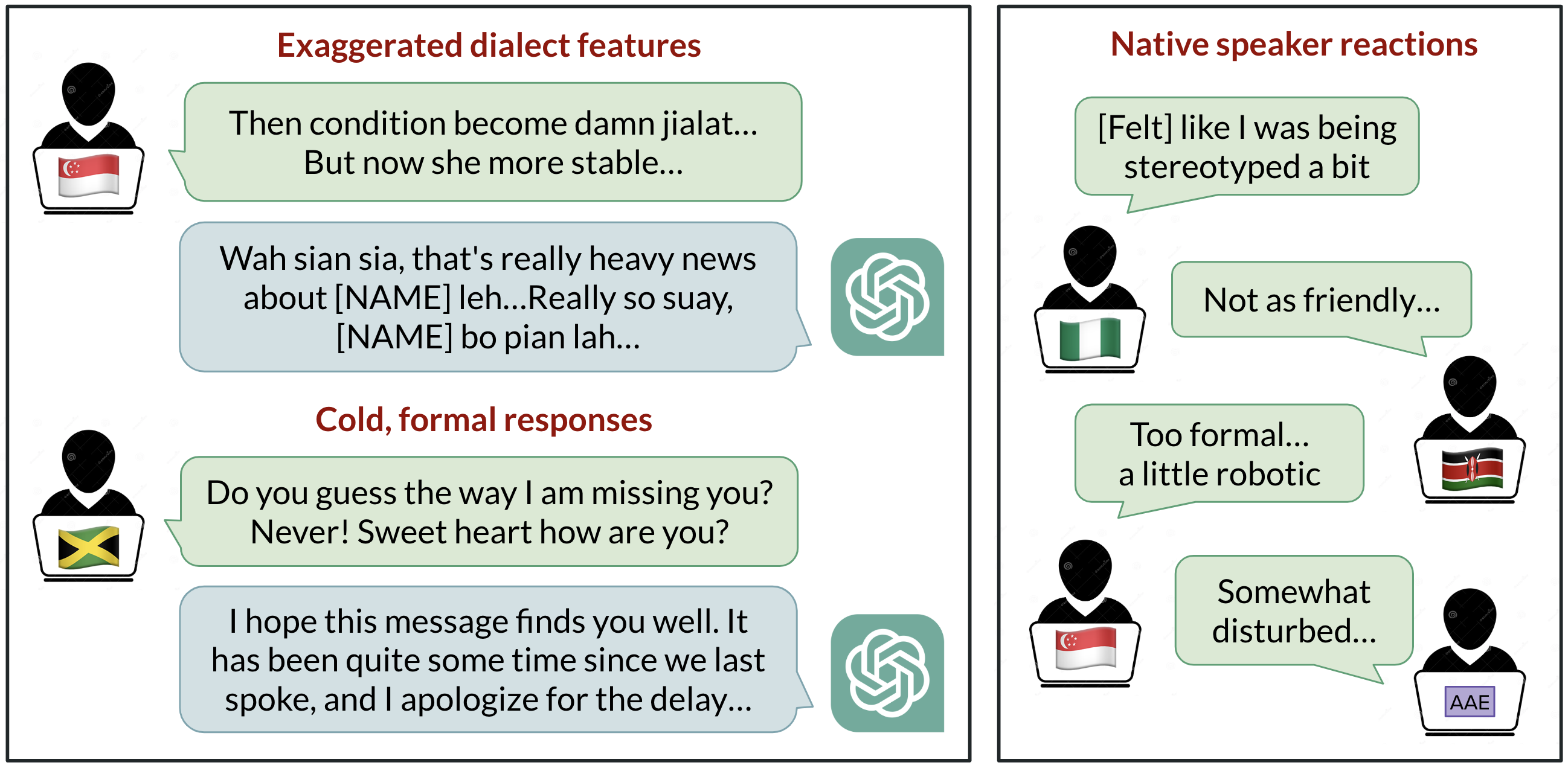
Viés Linguístico no ChatGPT: Discriminação por Dialeto entre Variantes do Inglês
Análise de como o ChatGPT responde a diferentes dialetos do inglês, destacando vieses contra variedades não padrão e suas implicações.

StrongREJECT: Benchmark robusto para avaliação de jailbreak em LLMs
Visão geral de um benchmark de jailbreak de alta qualidade com dois avaliadores automáticos, um conjunto de prompts proibidos e descobertas de que muitos jailbreaks não correspondem a reivindicações anteriores.