xT: Modelagem de Imagens Extremamente Grandes de Ponta a Ponta em GPUs
Sources: http://bair.berkeley.edu/blog/2024/03/21/xt, http://bair.berkeley.edu/blog/2024/03/21/xt/, BAIR Blog
Visão geral
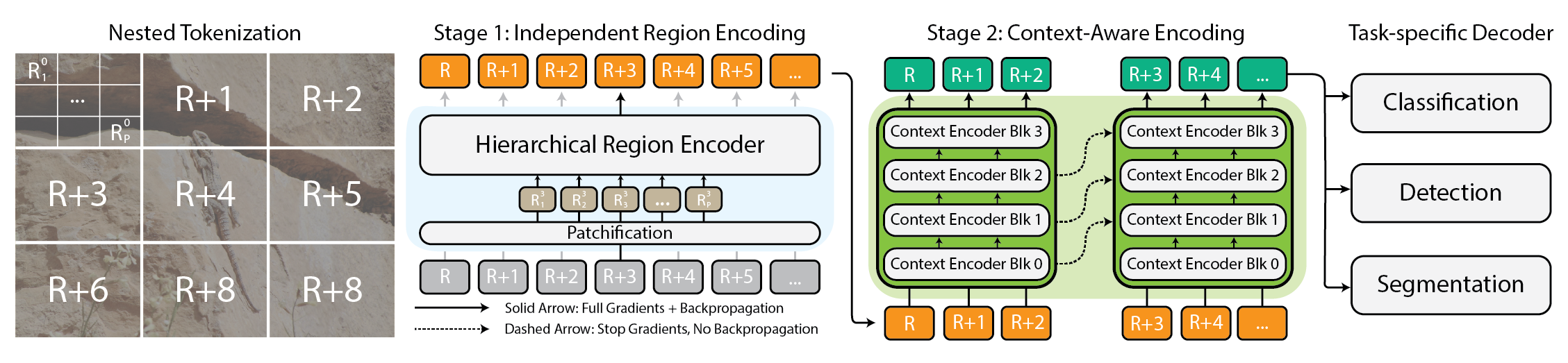
Modelar imagens extremamente grandes tornou-se uma necessidade prática à medida que câmeras e sensores geram dados em escala gigapixel. Abordagens tradicionais enfrentam problemas porque o uso de memória cresce de forma quadrática com o tamanho da imagem, forçando redução de resolução ou recorte, o que perde informações e contexto importantes. xT oferece uma nova estrutura para modelar imagens grandes de ponta a ponta em GPUs contemporâneas, agregando efetivamente contexto global com detalhes locais. No núcleo, xT introduz a tokenização aninhada, uma divisão hierárquica de uma imagem em regiões e sub-regiões que são processadas por componentes especializados antes de serem integrados para formar uma representação global. Em xT, a imagem é dividida em regiões por meio da tokenização aninhada. Cada região é tratada por um region encoder, que pode ser um backbone de visão de ponta como Swin, HierA, ConvNeXt, entre outros. O region encoder funciona como um especialista local e transforma as regiões em representações detalhadas de forma isolada. Para montar uma imagem global, o context encoder pega essas representações regionais e modela dependências de longo alcance em toda a imagem. O context encoder costuma ser um modelo de sequência longa; os autores testam Transformer-XL e uma variante chamada Hyper, além do Mamba, embora Longformer e outros modelos de sequência longa também sejam opções viáveis. A essência do xT está na combinação de tokenização aninhada, region encoders e context encoders. Ao primeiro dividir a imagem em peças gerenciáveis e, em seguida, integrá-las, o xT mantém a fidelidade dos detalhes enquanto incorpora informações distantes. Esse funcionamento end-to-end permite processar imagens massivas em GPUs modernas, evitando os gargalos de memória que dificultam métodos tradicionais. O xT é avaliado em benchmarks desafiadores, abrangendo tarefas de baselines padrão e análises com imagens em grande escala. Ele obtém maior precisão em tarefas descendentes com menos parâmetros e memória por região em comparação com baselines de ponta. Os autores demonstram a capacidade de modelar imagens com até 29.000 × 25.000 pixels em GPUs A100 de 40 GB, enquanto baselines comparáveis esgotam a memória a cerca de 2.800 × 2.800. As tarefas incluem classificação de espécies finas (iNaturalist 2018), segmentação dependente de contexto (xView3-SAR) e detecção (MS-COCO). Além dos aspectos técnicos, o xT permite que cientistas e clínicos vejam tanto a floresta quanto as árvores: em monitoramento ambiental, ele facilita entender mudanças amplas de paisagem junto com detalhes locais; na saúde, pode ajudar no diagnóstico considerando contexto amplo e informações em patches. Embora os autores não afirmem ter resolvido todos os problemas, apresentam o xT como um passo significativo para modelos que conciliam contexto em grande escala com detalhes finos em GPUs modernas. Um artigo completo está disponível como preprint no arXiv, e a página do projeto fornece links para o código e pesos liberados.
Principais características
- Tokenização em cadeia hierárquica: divisão em regiões e sub-regiões para processamento escalável
- Encoders regionais: backbones especializados locais (Swin, HierA, ConvNeXt, etc.) que transformam regiões em representações detalhadas
- Encoders de contexto: modelos de sequência longa (Transformer-XL, Hyper, Mamba; Longformer e outros são opções viáveis) que unem as representações regionais
- End-to-end em GPUs: imagens grandes modeladas de ponta a ponta com pegada de memória gerenciável
- Contexto global com detalhe local: preserva informações finas ao integrar o contexto de toda a imagem
- Base de avaliação competitiva: maior precisão com menos parâmetros e menor memória por região em tarefas como iNaturalist 2018, xView3-SAR e MS-COCO
- Capacidade de imagens grandes: demonstrado suporte para imagens até 29k × 25k em GPUs A100 de 40 GB, onde baselines tradicionais falham
- Código aberto: código e pesos liberados na página do projeto; o artigo no arXiv está disponível
Casos de uso comuns
- Classificação de espécies com grãos finos em imagens muito grandes (iNaturalist 2018)
- Segmentação dependente de contexto para cenas grandes (xView3-SAR)
- Detecção em grandes conjuntos de dados (MS-COCO)
- Monitoramento ambiental: permite ver mudanças amplas de paisagem e detalhes locais
- Imaging na saúde: ajuda no diagnóstico considerando contexto amplo e patches finos
Configuração e instalação
Observação: o texto não fornece comandos exatos de configuração ou instalação. Consulte a página do projeto para código e pesos.
# Setup & instalação
# Comandos exatos não são fornecidos na fonte.
# Consulte a página do projeto para código e pesos.Início rápido
Este guia rápido é um esboço conceitual que ilustra o fluxo pretendido; não é uma receita executável fornecida pela fonte.
# Início rápido (conceitual)
# Carregar uma imagem grande (escala gigapixel)
image = load_large_image('path/para/imagem_gigante.png')
# Tokenização aninhada em regiões e sub-regiões
regions = nested_tokenize(image)
# Processamento local para cada região
local_features = [region_encoder(r) for r in regions]
# Combinar características regionais com o contexto global
global_context = context_encoder(local_features)
# Fazer previsões específicas da tarefa
preds = head_classifier(global_context)
print(preds)Prós e contras
- Prós
- Processamento end-to-end de imagens massivas em GPUs modernas
- Mantém detalhes locais enquanto integra contexto global
- Menor memória por região com potencial para menos parâmetros que baselines
- Demonstração de suporte a imagens muito grandes (29k × 25k) onde baselines tradicionais esgotam a memória
- Flexibilidade de escolher backbones para regiões e modelos de contexto
- Aplicável a domínios diversos, incluindo ecologia e saúde
- Contras
- Requer configuração coordenada de encoders regionais e de contexto e possivelmente modelos de sequência longa
- Os passos exatos de instalação e treinamento não estão especificados na fonte
- Ainda é um quadro de pesquisa; a implantação prática pode exigir engenharia cuidadosa e considerações de hardware
Alternativas (breve comparação)
- Amostragem para baixo (down-sampling): reduz o tamanho da imagem antes do processamento, mas perde detalhes e contexto
- Recorte (cropping): processa patches menores, porém pode quebrar o contexto global
- Outras backbone de sequência longa (Longformer, Transformer-XL): usadas como encoders de contexto em xT; outras opções podem ser viáveis
- Processamento com apenas um backbone em alta resolução com otimizações de memória: não se aplica a imagens realmente gigantes sem arquiteturas especializadas | Abordagem | Pontos fortes | Limitações |---|---|---| | Down-sampling | Simples, baixa memória | Perde detalhes e contexto |Cropping | Foco local; modular | Conecta contexto global ausente |xT (tokenização aninhada) | End-to-end, contexto global com detalhe local | Maior complexidade de implementação |Outras backbones de sequência longa | Gerencia dependências de longo alcance | Potencialmente alto custo de memória/tempo; integração complexa |
Preços ou Licença
Informações de licença não são fornecidas na fonte. A página do projeto menciona código e pesos liberados, mas sem licença explícita.
Referências
More resources

CUDA Toolkit 13.0 para Jetson Thor: Ecossistema Unificado de Arm e Mais
Kit de ferramentas CUDA unificado para Arm no Jetson Thor com coerência total de memória, compartilhamento de GPU entre processos, interoperabilidade OpenRM/dmabuf, suporte NUMA e melhorias de ferramentas para embarcados e servidores.

Reduzir Custos de Implantação de Modelos Mantendo Desempenho com Swap de Memória de GPU
Utilize o swap de memória da GPU (hot-swapping de modelos) para compartilhar GPUs entre múltiplos LLMs, reduzir custos de ociosidade e melhorar o autoscaling mantendo os SLAs.

Aprimorando a auto-tunagem de GEMM com nvMatmulHeuristics no CUTLASS 4.2
Apresenta nvMatmulHeuristics para escolher rapidamente um conjunto pequeno de configurações de kernels GEMM com alto potencial para o CUTLASS 4.2, reduzindo drasticamente o tempo de tuning enquanto se aproxima do desempenho da busca exaustiva.

Deixe os ZeroGPU Spaces mais rápidos com compilação ahead-of-time (AoT) do PyTorch
Descubra como a AoT do PyTorch acelera ZeroGPU Spaces exportando um modelo compilado e recarregando-o instantaneamente, com quantização FP8, formas dinâmicas e integração cuidadosa com o fluxo Spaces GPU.

Como detectar (e resolver) 5 gargalos de pandas com cudf.pandas (aceleração GPU)
Recurso técnico para desenvolvedores que descreve cinco gargalos comuns do pandas, soluções práticas para CPU e GPU e aceleração por GPU com cudf.pandas.

Dentro do NVIDIA Blackwell Ultra: o chip que impulsiona a era da fábrica de IA
Perfil detalhado do Blackwell Ultra, com design de dois núcleos NV‑HBI, precisão NVFP4, 288 GB HBM3e por GPU e interconexões de sistema para fábricas de IA e inferência em grande escala.