vec2text: Invertendo Embeddings de Texto e Implicações de Segurança
Sources: https://thegradient.pub/text-embedding-inversion, https://thegradient.pub/text-embedding-inversion/, The Gradient
Visão geral
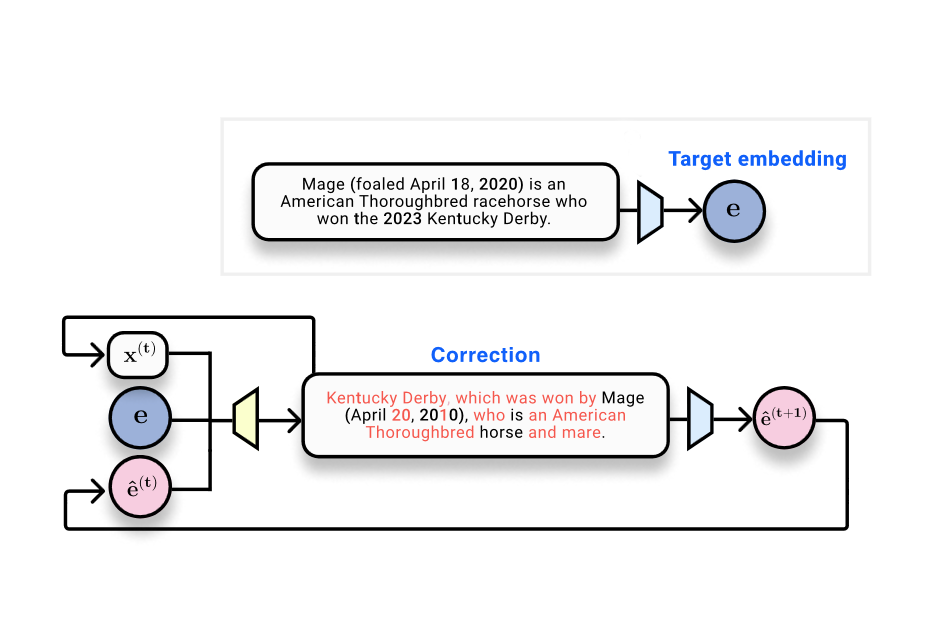
Sistemas de Recuperação Aumentada por Geração (RAG) armazenam e pesquisam documentos usando embeddings — representações vetoriais do texto produzidas por modelos de embedding. O artigo do The Gradient explora uma questão central: é possível recuperar o texto de entrada a partir de seus embeddings? A discussão situa os embeddings no contexto de bancos de dados vetoriais e das implicações de privacidade ao armazenar embeddings em vez do texto cru. Os autores citam o estudo Text Embeddings Reveal As Much as Text (EMNLP 2023), que aborda diretamente a inversão: é possível reconstruir o texto de entrada a partir de embeddings de saída? Do ponto de vista técnico, embeddings são o resultado de redes neurais: o texto é tokenizado, processado por camadas não lineares e, por fim, reduzido a um vetor fixo de tamanho. Resultados da literatura de processamento de dados indicam que mapeamentos assim não podem aumentar a informação do input; eles podem preservar ou descartar informação. No domínio da visão, existem resultados de que entradas de imagens podem ser recuperadas a partir de representações profundas, o que motiva a investigação no domínio do texto. Um cenário de toy no artigo considera 32 tokens mapeados para embeddings de 768 dimensões (32 × 768 = 24.576 bits, cerca de 3 kB). Isso estabelece as bases para avaliações mensuráveis: quão bem o texto original pode ser recuperado? O artigo apresenta uma progressão de métodos e métricas para responder a essa pergunta. Uma abordagem inicial trata a inversão como um problema de aprendizado de máquina tradicional: coletar pares embedding–texto e treinar um modelo para gerar texto a partir do embedding. Nesse arranjo, um transformador treinado para gerar texto a partir do embedding obtém BLEU por volta de 30/100 e uma taxa de correspondência exata próxima de zero, ilustrando a dificuldade de reversão perfeita em uma única passada. Uma observação-chave é que, quando o texto gerado é re-embedado, o embedding resultante fica muito próximo do embedding de referência: similaridade coseno em torno de 0,97. Isso confirma que o texto hipótese está próximo no espaço de embeddings, mesmo quando o texto superficial difere. A ideia central é evoluir de uma inversão de uma única passagem para um processo de otimização aprendida que opera no espaço de embeddings. Dado um embedding de referência (alvo), um texto que é hipótese e seu embedding, um modelo corretor é treinado para fornecer um texto que aproxime o alvo. Esse é o cerne do vec2text: um otimizador aprendido que atualiza o texto em passos discretos para alinhar-se com o embedding alvo. Depois de implementar essa abordagem, os autores relatam melhora drástica: um único passo de correção eleva o BLEU de cerca de 30 para ~50. Importante: vec2text pode ser usado de forma recursiva, gerando hipóteses, re-embedando-as e alimentando-as de volta para novas atualizações. Com cerca de 50 iterações, o método recupera 92% de sequências de 32 tokens exatamente, e alcança um BLEU de cerca de 97. Em outras palavras, para esse cenário limitado, o vetor de embedding contém informações suficientes para reconstruir quase perfeitamente o texto de superfície original, não apenas seu sentido semântico. A conclusão é clara: embeddigns podem ser invertidos com alta fidelidade na prática, o que levanta questões de privacidade e segurança para armazenamento e comunicação baseados em embeddings. A mensagem também aponta algumas ressalvas. Em primeiro lugar, o vetor de embedding tem uma capacidade fixa, então existem limites teóricos para a quantidade de informação que pode ser armazenada e recuperada. Em segundo lugar, os autores discutem a possibilidade de que a função de embedding seja perdedora (mapeando várias entradas para o mesmo embedding), o que limitaria a identificabilidade; em seus experimentos, não observaram colisões. Por fim, o texto situa o resultado em um contexto mais amplo: se o texto pode ser reconstruído quase perfeitamente a partir de embeddings, então existem considerações de segurança para bancos de dados vetoriais e provedores que lidam com embeddings. Para leitores que queiram o ferramental técnico, o artigo aponta o trabalho de inversão de embeddings em visão computacional e o estudo EMNLP 2023 que motiva a inversão do lado do texto. Consulte o link citado para um tratamento detalhado e especificações experimentais: Text Embeddings Reveal As Much as Text.
Principais características
- vec2text: um modelo de otimização aprendido que usa um embedding de referência, um texto da hipótese e a posição da hipótese no espaço de embeddings para prever a sequência de texto correta.
- Iteração no espaço de embeddings: o método suporta refinamento recursivo ao re-embedar o texto gerado e fornecê-lo de volta para atualizações adicionais.
- Ganhos de desempenho demonstrados: um passo de correção aumenta o BLEU de ~30 para ~50; com ~50 passos, é possível recuperar 92% das sequências de 32 tokens exatamente, e alcançar BLEU próximo de 97.
- Proximidade de espaço de embeddings: o texto gerado frequentemente produz embeddings muito próximos do embedding original (similaridade coseno ~0,97), mesmo quando o texto de superfície difere.
- Implicações de segurança e privacidade: a capacidade de inverter embeddings levanta preocupações para armazenamento e compartilhamento de dados baseados em embeddings.
- Enquadramento teórico: conecta-se à desigualdade de processamento de dados e à ideia de que embeddings são representações losses com informação potencialmente recuperável.
- Contexto trans-dominio: paralelos com trabalhos de inversão de imagens, onde representações profundas podem ser invertidas para reconstrução de entradas.
Casos de uso comuns
- Fluxos de trabalho RAG que dependem de busca baseada em embeddings: vetores em um banco de dados vetorial representam documentos e a similaridade orienta a recuperação. Se embeddings puderem ser invertidos para recuperar texto, isso levanta um risco de privacidade para dados armazenados como vetores.
- Cenários de vazamento de embeddings: exposição acidental de vetores de embedding ou acesso de um provedor de serviços aos embeddings poderia, em teoria, possibilitar a reconstrução de conteúdo de texto protegido, dependendo da capacidade do modelo e dos padrões de acesso.
- Planejamento de segurança para bancos de dados vetoriais: organizações podem precisar reavaliar retenção de dados, controles de acesso e modelos de risco à luz de potenciais capacidades de inversão.
- Direção de pesquisa: o marco vec2text mostra que a inversão não é apenas possível, mas pode ser aprimorada por meio de correção iterativa, informando futuras abordagens sensíveis à segurança no design de embeddings.
Setup & instalação
Não fornecido no material de origem. Se estiver avaliando a segurança de embeddings em seu stack, considere ações de alto nível:
# Não fornecido no textoQuick start
- Parta de um embedding de referência E e de uma hipótese de texto H. Calcule o embedding de H, compare com E e aplique o modelo de correção vec2text para prever um texto mais próximo do alvo.
- Re-embed o texto corrigido, compare os embeddings e repita o processo. Esse loop recursivo é o cerne da abordagem vec2text e foi mostrado gerar ganhos substanciais de fidelidade de superfície.
- No cenário de toy descrito (32 tokens, embedding de 768 dimensões), tentativas iniciais produzem BLEU por volta de 30; iterações intensivas podem levar o BLEU próximo de 97 com passos suficientes, com recuperação exata em grande parte das sequências.
Prós e contras
- Prós
- Inversão de alta fidelidade: demonstrada recuperação quase perfeita para um setting restrito de 32 tokens após várias iterações.
- Iteração conceitualmente simples: aproveita re-embedding e correções para convergir para o texto de referência.
- Define um caminho mensurável de inversão a partir de embeddings, com métricas claras (BLEU, correspondência exata, similaridade coseno).
- Capacidade de iteração recursiva: pode ser usada para refinamento progressivo e cenários de decoding iterativo.
- Contras
- Risco de privacidade: a capacidade de inverter embeddings destaca potenciais vazamentos de dados em armazenamento e compartilhamento baseados em embeddings.
- Nem sempre universal: a fidelidade de recuperação é demonstrada para um ambiente de toy específico; textos reais mais longos e com vocabulário diverso podem apresentar desafios adicionais.
- Limites de capacidade de embedding: há uma capacidade de bits fixa em um vetor de embedding, implicando limites fundamentais de quanta informação pode ser armazenada/reconstruída.
- Ambiguidades ocasionais: embora alcance alta fidelidade, correspondências exatas não são garantidas em todos os casos; colisões (mapear várias entradas para o mesmo embedding) são uma preocupação teórica, mas não foram observadas nesses experimentos.
Alternativas (comparações rápidas)
- Inversão direta com um transformer treinado para mapear embeddings para texto: a linha de base mostrou BLEU ~30 e correspondência exata próxima de zero, ilustrando a dificuldade de reversão sem refinamento iterativo.
- Inversão de embeddings de imagem: na visão computacional, trabalhos mostram que imagens podem ser recuperadas a partir de representações profundas, motivando preocupações de inversão em cross-domain. Um exemplo antigo é Dosovitskiy (2016), que demonstrou reconstrução a partir de features de CNN.
- Visão mais ampla: representações de embeddings são propositalmente lossy, equilibrando utilidade semântica com compressão de dados; no entanto, os resultados de inversão demonstrados desafiam suposições em cenários específicos.
Pricing ou Licença
Não especificado no material.
Referências
More resources

IA Geral Não é Multimodal: Inteligência com Ênfase no Encarnamento
Recursos concisos expondo por que abordagens multimodais baseadas em escala não devem produzir AGI; enfatiza inteligência enraizada em mundo físico.

Forma, Simetrias e Estrutura: O Papel da Matemática na Pesquisa de ML em Transformação
Explora como a matemática continua central no ML, mas seu papel está evoluindo da garantia teórica para geometria, simetrias e explicações pós-hoc em IA de escala.

O que falta nos chatbots de LLM: um senso de propósito
Explora o diálogo intencional em chatbots LLM, argumentando que interações de várias voltas alinham melhor a IA com os objetivos do usuário e permitem colaboração, especialmente em casos de uso de código e assistentes pessoais.

Visões positivas de IA fundamentadas no bem-estar
Propõe fundamentar os benefícios de IA no bem-estar humano e na saúde institucional, integrando ciência do bem-estar à IA e delineando visões práticas para desenvolvimento e implantação que promovam o florescimento individual e social.

Aplicações de LLMs no Mercado Financeiro — Visão geral e casos de uso
Visão geral de como LLMs podem ser aplicados a mercados financeiros, incluindo modelagem autoregressiva de dados de preços, entradas multimodais, residualização, dados sintéticos e previsões em múltiplos horizontes, com ressalvas sobre eficiência de mercado.

Recursos: Medindo e Mitigando Viés de Gênero em IA
Panorama de trabalhos influentes que medem viés de gênero em IA, abrangendo embeddings, co-referência, reconhecimento facial, benchmarks de QA e geração de imagens; discute mitigação, lacunas e auditoria robusta.