Hugging Face AI Sheets : outil sans code pour construire, transformer et enrichir des jeux de données
Sources: https://huggingface.co/blog/aisheets, Hugging Face Blog
Aperçu
Hugging Face AI Sheets est un outil sans code pour construire, transformer et enrichir des jeux de données avec des modèles d IA. Il est open-source, étroitement intégré au Hugging Face Hub et peut être déployé localement ou sur le Hub. L interface, semblable à une feuille de calcul, vise à permettre des expériences rapides avec de petits jeux de données avant de lancer des pipelines plus longs et plus coûteux. AI Sheets vous permet de créer de nouvelles colonnes en écrivant des prompts ; vous pouvez itérer autant que nécessaire et éditer ou valider des cellules pour enseigner au modèle ce que vous voulez. Vous pouvez comparer des modèles en créant des colonnes par modèle et en fournissant des prompts qui référencent des colonnes existantes. Vous pouvez aussi utiliser un prompt de jugement pour évaluer les réponses de différents modèles via des LLMs. Deux modes d utilisation principaux existent: importer un jeu de données existant ou en générer un à partir de zéro en le décrivant en langage naturel. Par exemple, vous pouvez demander les villes du monde avec leurs pays et une image, et AI Sheets générera un jeu de données automatiquement. L outil autorise des retours rapides en modifiant ou aimant des cellules, qui deviennent des exemples few-shot lors de la régénération. AI Sheets supporte les transformations, la classification, l extraction, l enrichissement et l analyse des données via des prompts d IA. Il peut enrichir les données manquantes en demandant de trouver le code postal d une adresse (la recherche sur le web doit être activée). Il peut même générer des données synthétiques en décrivant les données cibles et en générant des champs supplémentaires comme des e-mails professionnels réalistes. L export vers le Hub est pris en charge et, lors de l export, un fichier de configuration est généré et peut être réutilisé pour générer plus de données via des jobs HF ou pour réutiliser les prompts dans des applications en aval avec les exemples few-shot inclus. Pour ceux qui veulent évoluer, on peut utiliser cette configuration pour lancer des jeux de données plus importants via le Hub. AI Sheets offre une voie simple pour l expérimentation et les tests: commencez avec une idée ou un petit jeu de données, ajoutez des colonnes IA avec des prompts, comparez les sorties des modèles, affinez les prompts et régénérez au besoin. Le système est conçu pour faciliter l itération, l évaluation et la collaboration, et il est livré avec des jeux de données et des configurations d exemple qui illustrent comment combiner prompts de modèles, étapes de validation et prompts de jugement. Pour ceux qui s intéressent aux usages réels, le blog montre plusieurs flux de travail d exemple impliquant trois colonnes avec des modèles différents et une colonne juge pour comparer la qualité. Le projet supporte également le travail sur des jeux de données Hub existants pour ajouter des catégories ou employer un LLM en tant que juge afin de comparer les sorties des modèles. Vous pouvez démarrer sans installer quoi que ce soit via le déploiement Hugging Face Spaces ou installer localement depuis le dépôt GitHub. Pour un usage avancé, un plan PRO offre une utilisation d inference étendue. Lorsque vous êtes prêt, vous pouvez contacter la communauté via le Hub ou via les issues GitHub avec vos questions et retours.
Fonctionnalités clés
- Interface sans code, semblable à une feuille de calcul, pour construire, transformer et enrichir des jeux de données avec des modèles d IA.
- Intégration avec le Hugging Face Hub; accès à des milliers de modèles ouverts via Inference Providers ou des modèles locaux (y compris gpt-oss d OpenAI).
- Créer des colonnes IA par prompts; itérer et régénérer; les éditions manuelles et les likes servent d exemples few-shot.
- Comparer des modèles en créant plusieurs colonnes et en utilisant des prompts de jugement pour évaluer les résultats.
- Un ensemble flexible de tâches de données: transformation, classification, extraction, enrichissement et génération de données synthétiques.
- Support de l enrichissement par recherche web (activer la recherche) et la possibilité d exporter le jeu de données final vers le Hub avec un fichier de configuration.
- Deux modes de démarrage: importer des données existantes ou décrire un jeu de données pour le générer automatiquement.
- Déploiement local ou sur Hub; abonnement PRO avec utilisation accrue.
- Export vers le Hub et réutilisation des prompts via la configuration générée pour des tâches ultérieures et des usages futurs.
Cas d usage courants
- Tester les modèles les plus récents sur vos données: importer un jeu de données, créer une colonne par modèle et comparer les résultats en utilisant des prompts qui référencent les données dans chaque colonne.
- Améliorer rapidement les prompts: les edits ou les likes deviennent des exemples few-shot; régénérez pour propager les améliorations.
- Construire des applications qui répondent automatiquement aux demandes des clients: créer des colonnes avec des prompts pour générer des réponses et ajouter éventuellement une colonne juge pour comparer les sorties.
- Transformer des données avec des prompts: retirer la ponctuation, normaliser le texte ou restructurer le contenu dans une colonne.
- Classifier et extraire des idées: ajouter une colonne pour catégoriser ou extraire les idées principales.
- Enrichir des jeux de données: obtenir des informations manquantes comme les codes postaux via une requête, avec la recherche web activée lorsque nécessaire.
- Générer des données synthétiques: créer des descriptions et des e-mails réalistes à partir de prompts.
- Améliorer des jeux de données Hub existants: étiqueter et catégoriser des données existantes avec des prompts supplémentaires et valider les résultats.
- Évaluer les sorties des modèles: utiliser un LLM comme juge pour comparer différents modèles sur une tâche donnée.
- Exporter les résultats vers le Hub pour réutilisation et pour automatiser des tâches ultérieures grâce à la configuration générée.
Setup & installation
Essayez gratuitement sans installation via Space Hugging Face à l adresse https://huggingface.co/spaces/aisheets/sheets. Pour un déploiement local, consultez le dépôt GitHub https://github.com/huggingface/sheets. Les commandes exactes de configuration ne sont pas fournies dans la source; reportez-vous aux pages liées pour les instructions.
# Voir les instructions d’installation sur:
# - https://huggingface.co/spaces/aisheets/sheets
# - https://github.com/huggingface/sheetsQuick start
Exemple minimal du blog:
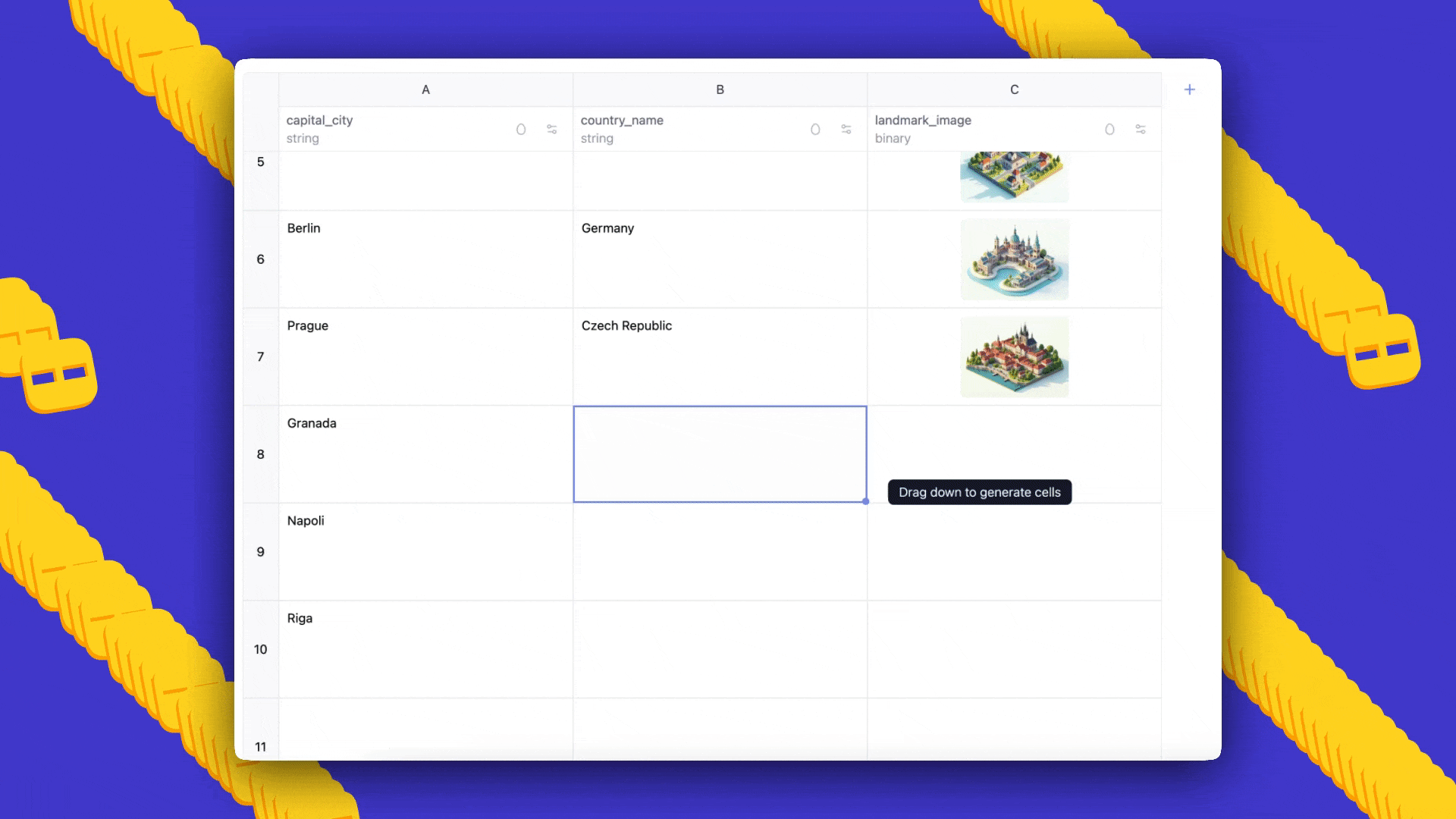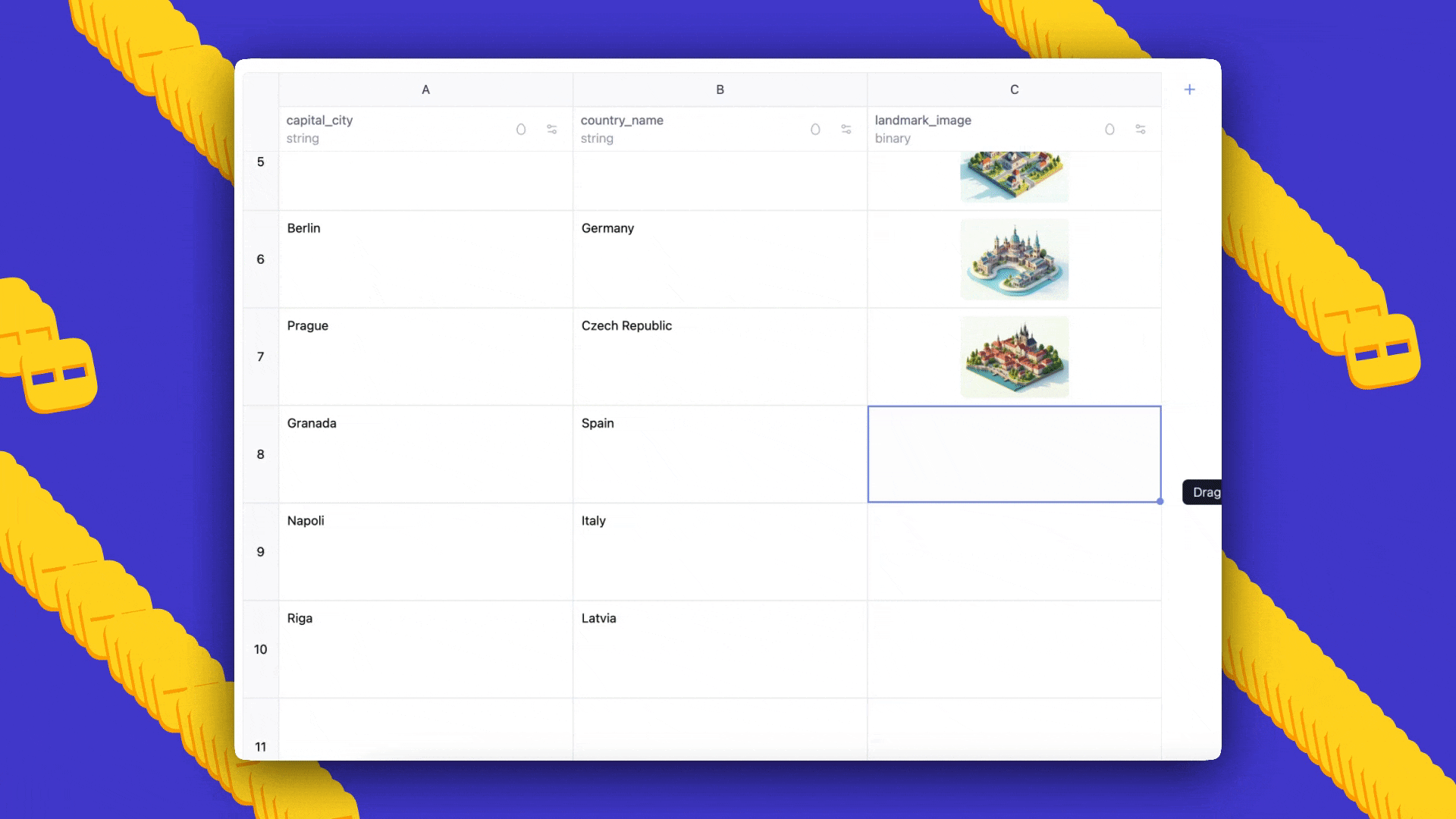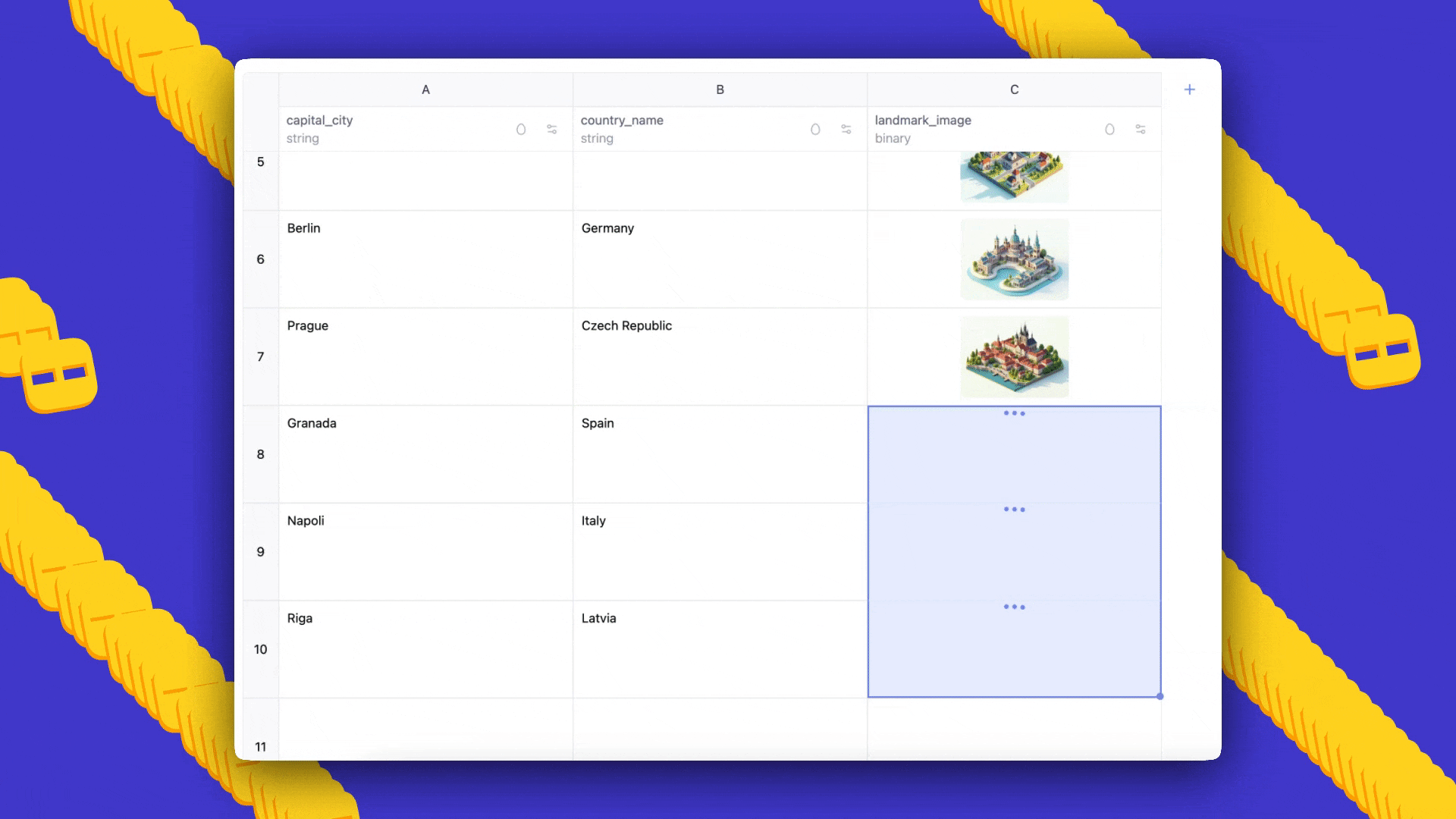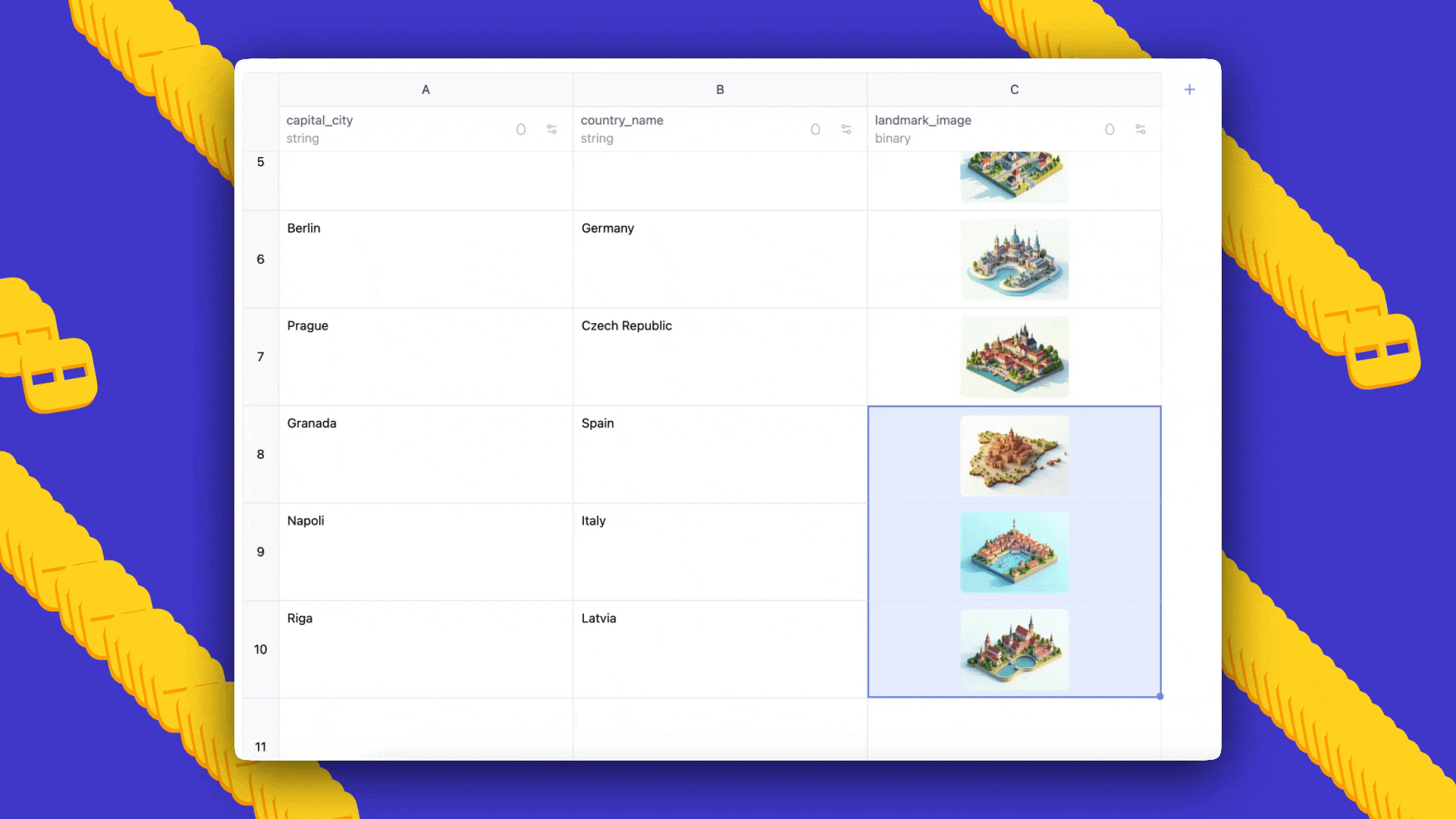
- Prompts: villes du monde, avec les pays auxquels elles appartiennent et une image de référence pour chaque ville, généré en style Ghibli.
- Résultat: AI Sheets génère automatiquement un ensemble de données avec trois colonnes; vous pouvez ajouter des lignes en faisant glisser, éditer les cellules pour lancer des exemples few-shot et régénérer pour propager prompts et feedback.
- Ensuite, vous pouvez exporter vers le Hub pour créer un fichier de configuration, réutilisable lors de prochaines exécutions ou alimenté dans des scripts pour générer des jeux de données plus importants avec des jobs HF. Cette approche permet de tester rapidement plusieurs modèles et d itérer sur les prompts et la structure des données avant l échelle.
Avantages et limites
Avantages:
- Outil no-code, open-source, étroitement intégré au Hub.
- Accès à des milliers de modèles ouverts via Inference Providers ou des modèles locaux (y compris gpt-oss).
- Itération rapide grâce à des prompts et des exemples few-shot intégrés issus des éditions manuelles et des likes.
- Comparaison de modèles et prompts de jugement pour évaluer les sorties.
- Deux modes de démarrage: importer des données ou générer à partir de zéro.
- Export vers le Hub et réutilisation des prompts via une configuration générée.
- Déploiement local ou sur Hub; accès gratuit via Spaces. Limites:
- Aucun inconvénient explicitement listé dans la source; dépend de l’usage et de la qualité des modèles.
Alternatives
Non décrit dans la source.
Tarification ou Licence
- Outil open-source avec plan PRO pour l’utilisation étendue (20x d’inférence mensuelle).
- Déploiement Spaces gratuit mentionné; pas d’installation nécessaire.
Références
More resources

Réduire les coûts de déploiement des modèles tout en conservant les performances grâce au swap de mémoire GPU
Exploitez le swap mémoire GPU (hot-swapping de modèles) pour partager les GPUs entre plusieurs LLM, réduire les coûts inoccupés et améliorer l’auto-Scaling tout en respectant les SLA.

Accélérez ZeroGPU Spaces avec la compilation ahead-of-time (AoT) de PyTorch
Découvrez comment la compilation AoT de PyTorch accélère ZeroGPU Spaces en exportant un modèle compilé et en le rechargeant instantanément, avec quantification FP8, formes dynamiques et intégration au flux Spaces GPU.

Fine-Tuning gpt-oss pour la précision et les performances avec l’entraînement par quantisation (QAT)
Guide du fine-tuning de gpt-oss utilisant SFT + QAT pour récupérer la précision FP4 tout en préservant l’efficacité, avec upcast vers BF16, MXFP4, NVFP4 et déploiement avec TensorRT-LLM.

Comment les petits modèles linguistiques contribuent à une IA agentique évolutive
Explique comment les petits modèles linguistiques permettent une IA agentique plus rentable et flexible, aux côtés des LLMs, via NVIDIA NeMo et Nemotron Nano 2.

Comment faire évoluer vos agents LangGraph en production d’un seul utilisateur à 1 000 collègues
Guide pour déployer et faire évoluer des agents LangGraph en production avec le NeMo Agent Toolkit, des tests de charge et une mise en œuvre par étapes pour des centaines à des milliers d’utilisateurs.

NVFP4 Entraîne avec une Précision de 16 Bits et une Vitesse et Efficacité de 4 Bits
NVFP4 est un format de données en 4 bits offrant une précision équivalente au FP16 avec la bande passante et l’efficacité mémoire du 4 bits, étendu au pré-entraînement pour les grands modèles de langage. Ce profil couvre des expériences en 12B, la stabilité et les collaborations industrielles.