
Élargissement de l’Apprentissage par Renforcement pour l’Aplanissement du Trafic : Déploiement sur une Autoroute avec 100 VAs
Sources: http://bair.berkeley.edu/blog/2025/03/25/rl-av-smoothing, http://bair.berkeley.edu/blog/2025/03/25/rl-av-smoothing/, BAIR Blog
Aperçu
Les ondes d’arrêt-démarrage sont fréquentes sur les autoroutes à haute densité et entraînent un gaspillage d’énergie et des émissions plus élevées. Des chercheurs ont déployé 100 voitures pilotées par apprentissage par renforcement (RL) sur une autoroute réelle (I-24 près de Nashville) afin d’apprendre des stratégies de conduite qui amortissent ces ondes, améliorent l’efficacité énergétique et maintiennent le débit autour des conducteurs humains. L’équipe a construit des simulations rapides et axées sur les données, tirées de données expérimentales d’autoroute, pour entraîner des agents RL à optimiser l’usage d’énergie tout en opérant en sécurité près des humains. Une conclusion clé est qu’une petite fraction de VAs bien contrôlés peut améliorer significativement le trafic et réduire la consommation de carburant pour tous les usagers. Les contrôleurs sont conçus pour être compatibles avec le matériel ACC standard et fonctionnent de manière décentralisée en utilisant uniquement des capteurs locaux disponibles sur les véhicules modernes. Le projet retrace le chemin de la simulation à l’expérimentation sur le terrain, en détaillant les étapes pour combler l’écart entre l’entraînement et le monde réel. Les chercheurs ont utilisé des données de trajectoires de la I-24 pour faire revivre un trafic instable dans la simulation, permettant aux VAs d’apprendre des stratégies de smoothing derrière le trafic humain. L’approche met l’accent sur l’observation locale: la vitesse du VA, la vitesse du véhicule devant et l’écart entre eux. Sur la base de ces signaux, l’agent recommande soit une accélération instantanée, soit une vitesse souhaitée pour le VA. La fonction de récompense est conçue pour équilibrer l’efficacité énergétique, le débit et la sécurité; des seuils dynamiques minimum et maximum de gap évitent des comportements dangereux. Le design pénalise également la consommation de carburant des conducteurs humains derrière le VA pour décourager l’optimisation égoïste par le RL. En simulation, le comportement appris maintient généralement des gaps légèrement plus grands que ceux des humains, permettant aux VAs d’absorber plus efficacement les ralentissements à venir. Dans les scénarios les plus congestionnés, les simulations indiquent des économies de carburant allant jusqu’à ~20% pour tous les usagers, avec moins de 5% de pénétration de VAs. Notamment, les contrôleurs RL ont été conçus pour fonctionner avec le système de contrôle de croisière adaptatif (ACC) existant et peuvent opérer de manière décentralisée sans infrastructure spéciale. Après validation en simulation, l’équipe a déployé les contrôleurs RL sur le terrain dans ce qu’ils ont appelé MegaVanderTest : une expérience à grande échelle avec 100 véhicules sur l’I-24 pendant les heures de pointe. La collecte de données a utilisé des caméras au-dessus de la route pour reconstruire des trajectoires de millions de véhicules, permettant une analyse détaillée de la dynamique du trafic et de l’usage d’énergie.
Caractéristiques clés
- Formation RL fondée sur des données dans des simulations rapides et réalistes, issues de données réelles d’autoroute.
- Observations locales : vitesse du VA, vitesse du véhicule en tête et espacement.
- Forme de récompense équilibrant efficacité énergétique, débit et sécurité; seuils dynamiques de gap pour éviter les comportements dangereux.
- Déploiement décentralisé compatible avec le hardware ACC standard et les capteurs radar; pas d’infrastructure nouvelle nécessaire.
- Validation à grande échelle (MegaVanderTest) : 100 véhicules pendant les heures de pointe du matin, avec des millions de trajectoires.
- Économies d’énergie rapportées d’environ 15–20% dans les scenarii congestionnés; réduction de la variance de vitesse et d’accélération indiquant une attenuation des ondes.
- Observé que suivre de près les VAs peut réduire la consommation d’énergie en aval et réduire l’empreinte de congestion.
- Preuves de gains potentiels avec des simulations plus rapides, des modèles humains améliorés et l’exploration d’une coordination via 5G.
- Le test sur le terrain s’est déroulé sans communication explicite entre VAs, en ligne avec les déploiements actuels.
- Intégration avec les systèmes ACC existants pour permettre l’échelle.
Cas d’usage courants
- Atténuer le trafic et réduire la consommation de carburant sur les autoroutes congestionnées avec peu de modifications d’infrastructure.
- Déployer des contrôleurs de smoothing basés sur RL sur des VAs existants équipés d’un ACC pour élargir les bénéfices énergétiques.
- Combiner les résultats de simulation et de terrain dans la recherche sur le trafic en autonomie, avec différents niveaux d’autonomie.
- Explorer des modèles humains de conduite et des données sensorielles pour améliorer la fidélité et la robustesse.
Configuration et installation
La source décrit l’entraînement des agents RL dans des simulations rapides à partir de données réelles, la validation sur hardware et le déploiement sur 100 véhicules, mais ne fournit pas de commandes de configuration spécifiques. Aucun pas de commande n’est donné.
# Configuration non fournie dans la sourceDémarrage rapide
La source donne une feuille de route de haut niveau sans code exécutable ni guide rapide prêt à l’emploi. Un aperçu minimal dérivé du contenu :
- Construire des simulations rapides basées sur des trajets réels.
- Entraîner des agents RL pour optimiser l’efficacité énergétique tout en conservant le débit et la sécurité.
- Valider en hardware, puis déployer sur une flotte de VAs.
- Collecter et analyser des données de terrain pour quantifier les économies d’énergie et l’atténuation des ondes.
# Démarrage rapide non fourni par la sourceAvantages et inconvénients
- Avantages
- Prouve un contrôle décentralisé pouvant être déployé sur des VAs standard sans infrastructure nouvelle.
- Preuves d’économies d’énergie significatives (15–20%) autour des VAs contrôlés dans le monde réel.
- MegaVanderTest est l’un des plus grands essais sur trafic mixte réalisés à ce jour.
- Compatibilité avec les systèmes ACC existants et utilisation de capteurs radar.
- Observations d’une réduction de la variance de vitesse et d’accélération, signe d’un amortissement des ondes.
- Inconvénients
- Le pont entre la simulation et le monde réel demeure un défi; besoin de simulations plus rapides et de modèles humains plus précis.
- Les gains futurs pourraient dépendre d’une communication explicite entre VAs (par exemple via 5G), non déployée dans le test.
- Le design de la récompense nécessite un équilibre prudent pour éviter des comportements dangereux; des seuils dynamiques aident à limiter cela.
Alternatives (comparaisons rapides)
| Approche | Traits clés | Avantages | Inconvénients |---|---|---|---| | Contrôle par rampes / infrastructure | Gestion centralisée par infrastructure | Peut modeler le trafic à l’échelle réseau sans dépendre de la pénétration des VAs | Nécessite infrastructure, coordination et investissement; dépendance élevée à l’adoption de VAs |Limites de vitesse variables | Contrôle de vitesse via l’infrastructure | Politique simple pour réduire les ondes | Dépend des capteurs/communications; adaptation limitée au trafic mixte |RL smoothing sur VAs (cette étude) | Contrôle décentralisé utilisant des observations locales | Scale avec l’adoption; pas d’infrastructure nouvelle | Défis de sim-to-real; les bénéfices dépendent de la pénétration; résultats de terrain sensibles au comportement des conducteurs derrière les VAs |
Licence ou prix
Non spécifié dans la source.
Références
More resources

NVIDIA NeMo-RL Megatron-Core : Débit d'entraînement optimisé
Vue d'ensemble de NeMo-RL v0.3 avec le backend Megatron-Core pour le post-entraînement de grands modèles, présentant le parallélisme 6D/4D, des noyaux GPU optimisés et une configuration simplifiée pour accroître le débit en apprentissage par renforcement.

Defending against Prompt Injection with Structured Queries (StruQ) and Preference Optimization (SecAlign)
Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks against them. Prompt injection attack is listed as the #1 threat by OWASP to LLM-integrated applications, where an LLM input contains a trusted prompt (ins

PLAID : Génération multimodale de protéines par diffusion latente
PLAID génère simultanément les séquences protéiques 1D et les structures 3D en apprenant l’espace latent des modèles de pliage protéique. Prompts de fonction et d’organisme, décodage avec des poids gelés ESMFold.

Anthology : Conditionnement des LLMs par des Backstories Riches pour des Personas Virtuelles
Une méthode pour guider les LLMs vers des personas virtuelles représentatifs et cohérents en générant des backstories détaillées et en les utilisant comme contexte de conditionnement, permettant des simulations individualisées et des études utilisateur à grande échelle.
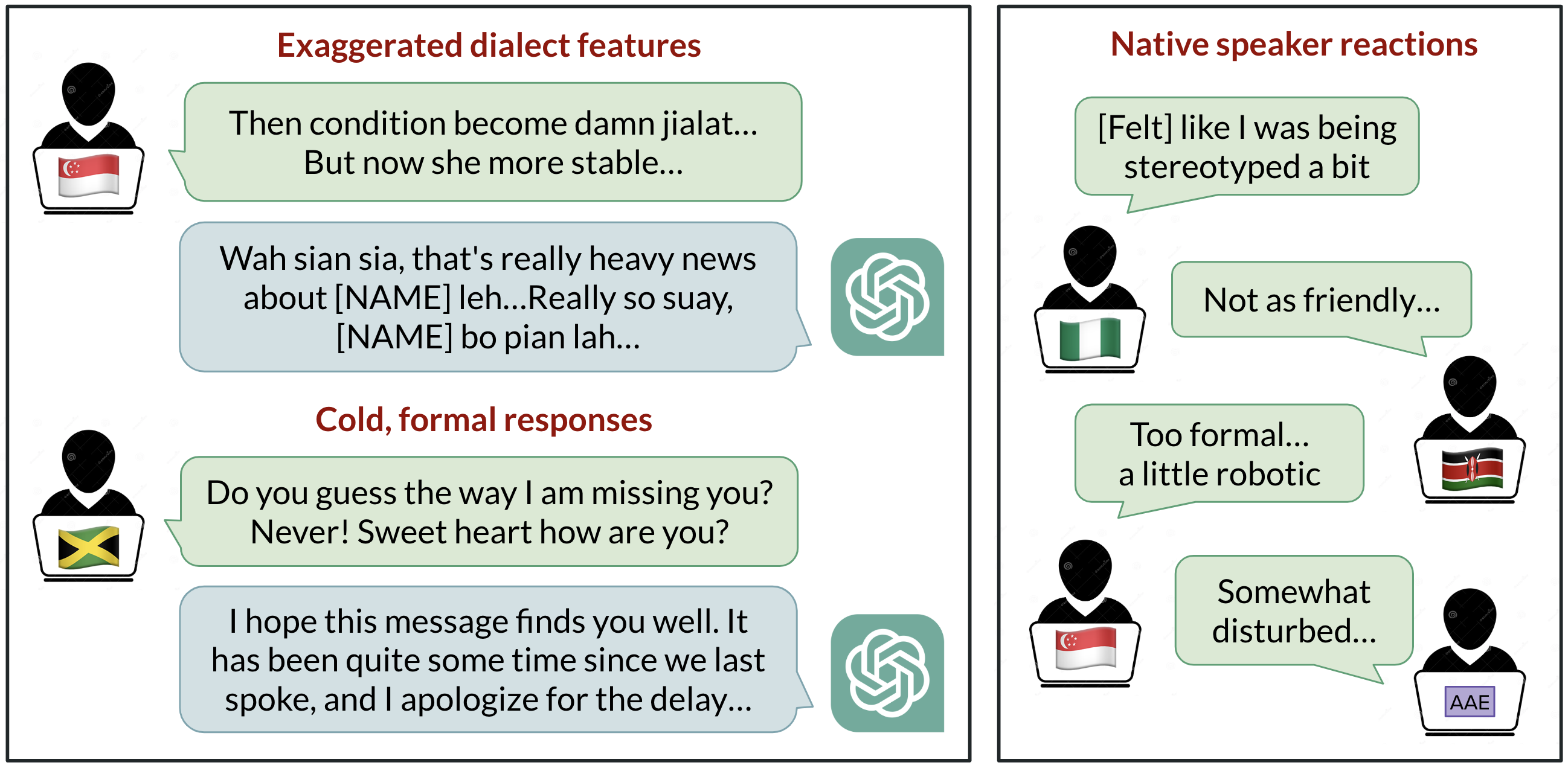
Biais linguistiques dans ChatGPT : discrimination selon les dialectes de l’anglais
Analyse de la manière dont ChatGPT réagit à divers dialectes de l’anglais, démontrant des biais contre les variantes non standard et leurs implications.

StrongREJECT : Benchmark robuste pour évaluer les jailbreaks des LLM
Aperçu d’un benchmark de jailbreak de haute qualité avec deux évaluateurs automatisés, un ensemble de 313 prompts interdits et des résultats montrant que de nombreux jailbreaks sont moins efficaces que les revendications passées.