
Visual Haystacks (VHs) : Benchmark pour le raisonnement visuel multi‑image
Sources: http://bair.berkeley.edu/blog/2024/07/20/visual-haystacks, http://bair.berkeley.edu/blog/2024/07/20/visual-haystacks/, BAIR Blog
Vue d’ensemble
Visual Haystacks (VHs) est le premier benchmark « Needle-In-A-Haystack » (NIAH) centré sur la vision, conçu pour évaluer rigoureusement les grands modèles multimodaux (LMM) dans le traitement d’informations visuelles en contexte long. Le but est d’aller au‑delà du VQA sur une seule image et de tester la récupération et le raisonnement sur de grandes collections d’images non corrélées. Le jeu de données se concentre sur l’identification de contenu visuel spécifique (par exemple, des objets) dans des images tirées du jeu COCO, avec environ 1K paires question‑réponse binaires insérées dans des « haystacks » contenant de 1 à 10K images. La tâche est divisée en deux défis: Single-Needle et Multi-Needle. Le benchmark met en évidence trois déficits majeurs des LMMs lorsque confrontés à de grandes entrées visuelles: les distracteurs visuels, les difficultés de raisonnement à travers plusieurs images, et la sensibilité à la position de l’aiguille dans la séquence d’entrée (effet « perdu au milieu »). En réponse, les auteurs présentent MIRAGE (Multi-Image Retrieval Augmented Generation), un paradigme d’entraînement open‑source en un seul stade qui étend LLaVA pour gérer les tâches MIQA. MIRAGE applique une compression des encodages, utilise un récupérateur intégré pour filtrer les images non pertinentes et ajoute des données d’entraînement avec du raisonnement multi-image. Le résultat est un modèle capable de gérer 1K ou 10K images et qui démontre une forte capacité de rappel et de précision sur les tâches à multi-images, surpassant plusieurs baselines sur de nombreux scénarios Single‑Needle. Ce travail compare également une baseline à deux étapes (légender avec LLaVA suivie d’une réponse en texte via Llama3) à des modèles visuellement conscients et montre que l’intégration de légendes dans un contexte long par les LLMs peut être efficace, alors que les LMMs existants ont souvent du mal à intégrer des informations entre plusieurs images. Le benchmark VHs et MIRAGE visent à faire progresser la récupération visuelle robuste et le raisonnement sur de grandes collections d’images. Pour plus de détails et données, consultez la source: https://bair.berkeley.edu/blog/2024/07/20/visual-haystacks/
Caractéristiques clés
- Raisonnement visuel en contexte long sur des ensembles importants et non corrélés d’images (environ 1K paires QA; haystacks de 1K à 10K images).
- Deux défis: Single-Needle (une aiguille) et Multi-Needle (2 à 5 aiguilles).
- Tâches d’identification d’objets basées sur des annotations COCO (par exemple, présence d’un objet cible).
- Paradigme MIRAGE open-source (Multi-Image Retrieval Augmented Generation) construit sur LLaVA pour MIQA.
- Compression des requêtes pour réduire les tokens d’encodage, permettant des haystacks plus importants dans les limites de contexte.
- Récupérateur intégré entraîné avec le pipeline d’ajustement du LLM pour filtrer dynamiquement les images irrélevantes.
- Données d’entraînement multi-image (augmentation avec des données de raisonnement multi-image et données synthétiques).
- MIRAGE obtient des performances de pointe sur la plupart des tâches à aiguille unique et démontre une recall et une précision élevées sur les tâches multi-image, surpassant des baselines comme GPT‑4, Gemini‑v1.5 et LWM dans de nombreux scénarios.
- Récupérateur co‑entraîné surpasse CLIP dans ce cadre MIQA spécifique, montrant que les récupérateurs génériques peuvent sous‑performer lorsque la tâche dépend d’un texte de type question et de la pertinence visuelle.
- Paradigme d’entraînement simple et open‑source, en un seul stade, conçu pour adresser les défis clefs de MIQA: distracteurs, contexte long et raisonnement inter‑image.
- Identification de phénomènes tels que l’effet de position de l’aiguille, où les performances du modèle varient de manière significative selon la position de l’image‑Aiguillon dans la séquence (par exemple des chutes allant jusqu’à ~26,5% pour certains LMM lorsque non placée juste avant la question; les modèles propriétaires montrent des baisses jusqu’à ~28,5% lorsque non au début).
Cas d’usage courants
- Analyser des motifs dans de grandes collections d’images médicales (par exemple repérer des observations dans de multiples images).
- Suivre le déboisement ou les changements écologiques via des images satellites sur une période.
- Cartographier des changements urbains via des données de navigation autonome et capteurs.
- Examiner de grandes collections d’art à la recherche de motifs ou objets visuels spécifiques.
- Comprendre le comportement des consommateurs à partir d’images de surveillance retail à grande échelle.
Setup et installation
Les détails de mise en place et les commandes d’installation ne sont pas fournis dans la source.
# Setup details not provided in sourceDémarrage rapide
Note: la source décrit un flux conceptuel plutôt qu’un guide prêt à l’emploi. Un aperçu de haut niveau basé sur l’approche décrite:
- Constituer un haystack: rassembler un grand ensemble d’images non corrélées (1K–10K) avec annotations COCO pour les objets cibles.
- Préparer une requête: définir l’objet ancre et l’objet cible pour la tâche aiguille.
- Utiliser MIRAGE comme pipeline monoposte: appliquer une compression des encodages pour réduire les tokens, exécuter le récupérateur en ligne pour filtrer les images non pertinentes et tirer parti des données d’entraînement multi-image.
- Évaluer: mesurer les tâches à aiguille unique et à aiguille multiple, en comparaison avec des baselines comme une légende + LLM ou d’autres LMMs.
# Flux conceptuel (illustratif; pas un script exécutable)
images = charger_dataset("COCO", count=1000_a_10000)
qa = creer_qa_binaria(objet_iller, objet_cible)
modele = MIRAGE()
reponse = modele.repondre(images, qa)
print(reponse)Avantages et inconvénients
- Avantages:
- Permet le raisonnement en contexte long sur des milliers d’images potentiellement non liées.
- Encodages compressés permettent d’étendre les haystacks au-delà des limites de contexte.
- Récupérateur intégré réduit les données non pertinentes, améliorant la récupération.
- Données d’entraînement multi‑image améliorent la généralisation pour les tâches MIQA.
- MIRAGE offre de solides performances sur les tâches à aiguille unique et des résultats compétitifs sur les tâches multi‑image; le récupérateur peut surpasser CLIP dans ce cadre.
- Inconvénients:
- La précision diminue lorsque les haystacks s’allongent pour de nombreux modèles en raison des distrateurs visuels.
- Dans des scénarios 5+ images et Multi-Needle, de nombreux LMMs sous‑performant par rapport à une baseline de légende+LLM dans certains cas.
- Des effets de position de l’aiguille peuvent influencer fortement les performances (jusqu’à ~26,5% de variation selon le modèle et la position).
Alternatives (brève comparaison)
- VQA traditionnel sur une seule image: limité à une image; ne gère pas la récupération entre plusieurs images ni le raisonnement en contexte long.
- Benchmarks NIAH textuels Gemini-style: focalisés sur la récupération textuelle ou le raisonnement; VHs étend cela au domaine visuel multi-image et au raisonnement inter‑image.
- Baseline de légende (LLaVA + Llama3): utilise une légende des images suivie d’un QA en texte; peut surperformer dans certains scénarios multi‑image mais peut être insuffisant lorsque des indices visuels précis sont essentiels. | Approche | Focus | Points forts | Limites |---|---|---|---| | MIRAGE (baseline VHs) | QA multi-image et récupération | Fort recall/ précision en MIQA; open-source; dépasse plusieurs baselines sur de nombreuses tâches à aiguille unique | Nécessite préparation des données et ajustements MIQA; effets de position de l’aiguille peuvent modifier le rendement |Légende + LLM (2 étapes) | QA basé sur texte à partir de légendes | Robuste lorsque les légendes capturent l’information clé | Peut sous-utiliser les détails visuels; cruciales nuances visuelles peuvent être manquées |LMMs avancés (GPT-4o, Gemini-v1.5) | VQA visuel directe sur plusieurs images | Potentiellement forts dans certains contextes | Faibles dans les scénarios 5+ images et multi-aiguille selon cette étude; limites de contexte et de payload |
Prix ou Licence
Aucun détail de tarification n’est fourni dans la source. MIRAGE est décrit comme open-source dans le cadre du benchmark et de l’approche, mais les termes de licence ne sont pas spécifiés ici.
Références
- Visual Haystacks: Are We Ready for Multi-Image Reasoning? Launching VHs: The Visual Haystacks Benchmark!. BAIR Blog. https://bair.berkeley.edu/blog/2024/07/20/visual-haystacks/
More resources

TextQuests : Évaluer les LLM dans des jeux d’aventure textuels
TextQuests est un benchmark qui évalue les agents LLM sur 25 jeux classiques d’infocom, mettant l’accent sur le raisonnement en contexte long et l’exploration autonome.

Defending against Prompt Injection with Structured Queries (StruQ) and Preference Optimization (SecAlign)
Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks against them. Prompt injection attack is listed as the #1 threat by OWASP to LLM-integrated applications, where an LLM input contains a trusted prompt (ins

PLAID : Génération multimodale de protéines par diffusion latente
PLAID génère simultanément les séquences protéiques 1D et les structures 3D en apprenant l’espace latent des modèles de pliage protéique. Prompts de fonction et d’organisme, décodage avec des poids gelés ESMFold.

Élargissement de l’Apprentissage par Renforcement pour l’Aplanissement du Trafic : Déploiement sur une Autoroute avec 100 VAs
100 véhicules autonomes contrôlés par RL déployés sur l’I-24 pendant les heures de pointe pour atténuer les ondes d’arrêt-démarrage, améliorer le flux et réduire la consommation de carburant pour tous les usagers. Contrôle décentralisé via capteurs radar de base.

Anthology : Conditionnement des LLMs par des Backstories Riches pour des Personas Virtuelles
Une méthode pour guider les LLMs vers des personas virtuelles représentatifs et cohérents en générant des backstories détaillées et en les utilisant comme contexte de conditionnement, permettant des simulations individualisées et des études utilisateur à grande échelle.
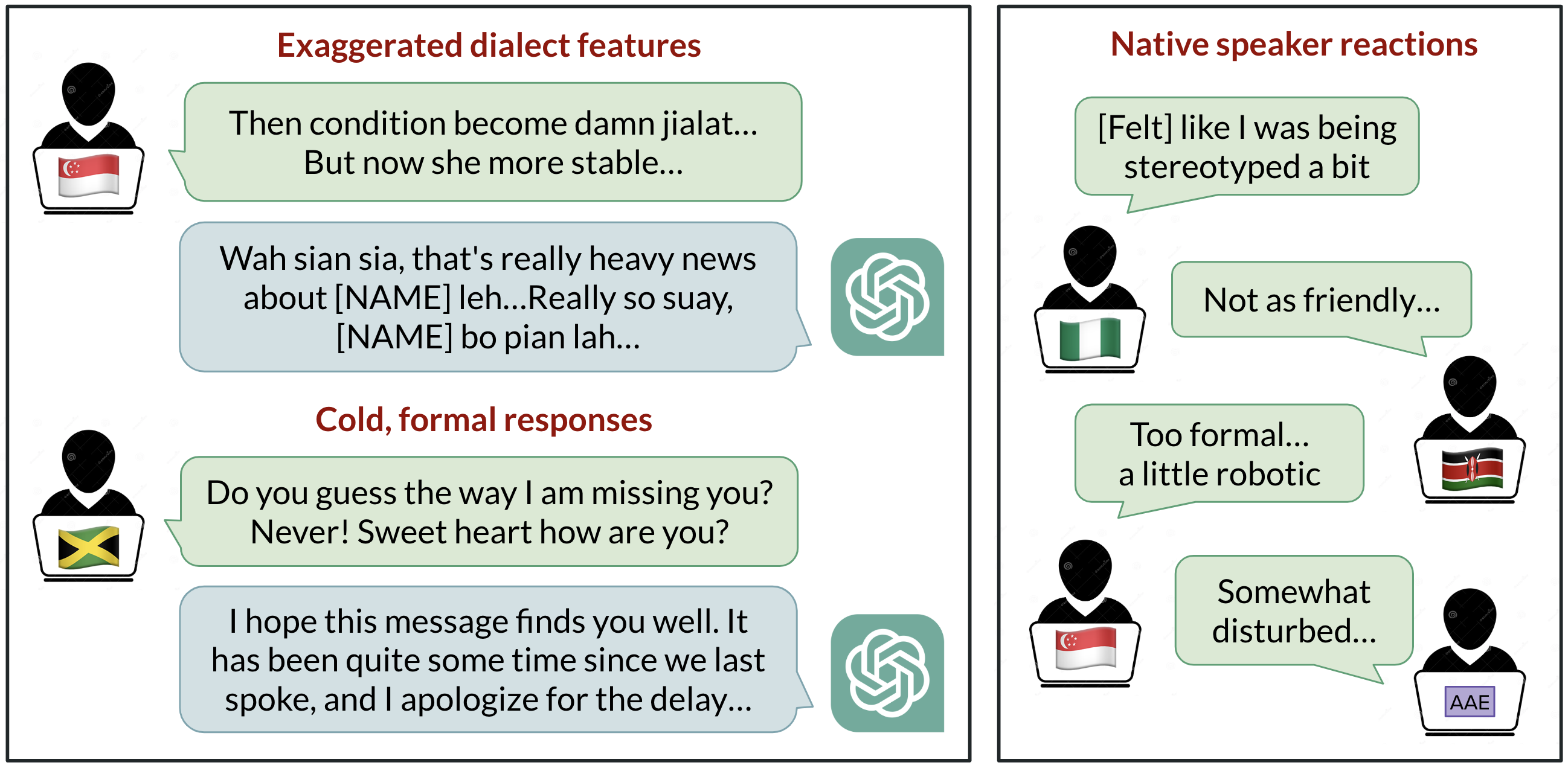
Biais linguistiques dans ChatGPT : discrimination selon les dialectes de l’anglais
Analyse de la manière dont ChatGPT réagit à divers dialectes de l’anglais, démontrant des biais contre les variantes non standard et leurs implications.