TinyAgent : Appel de fonctions à la périphérie pour les petits modèles de langage
Sources: http://bair.berkeley.edu/blog/2024/05/29/tiny-agent, http://bair.berkeley.edu/blog/2024/05/29/tiny-agent/, BAIR Blog
Aperçu
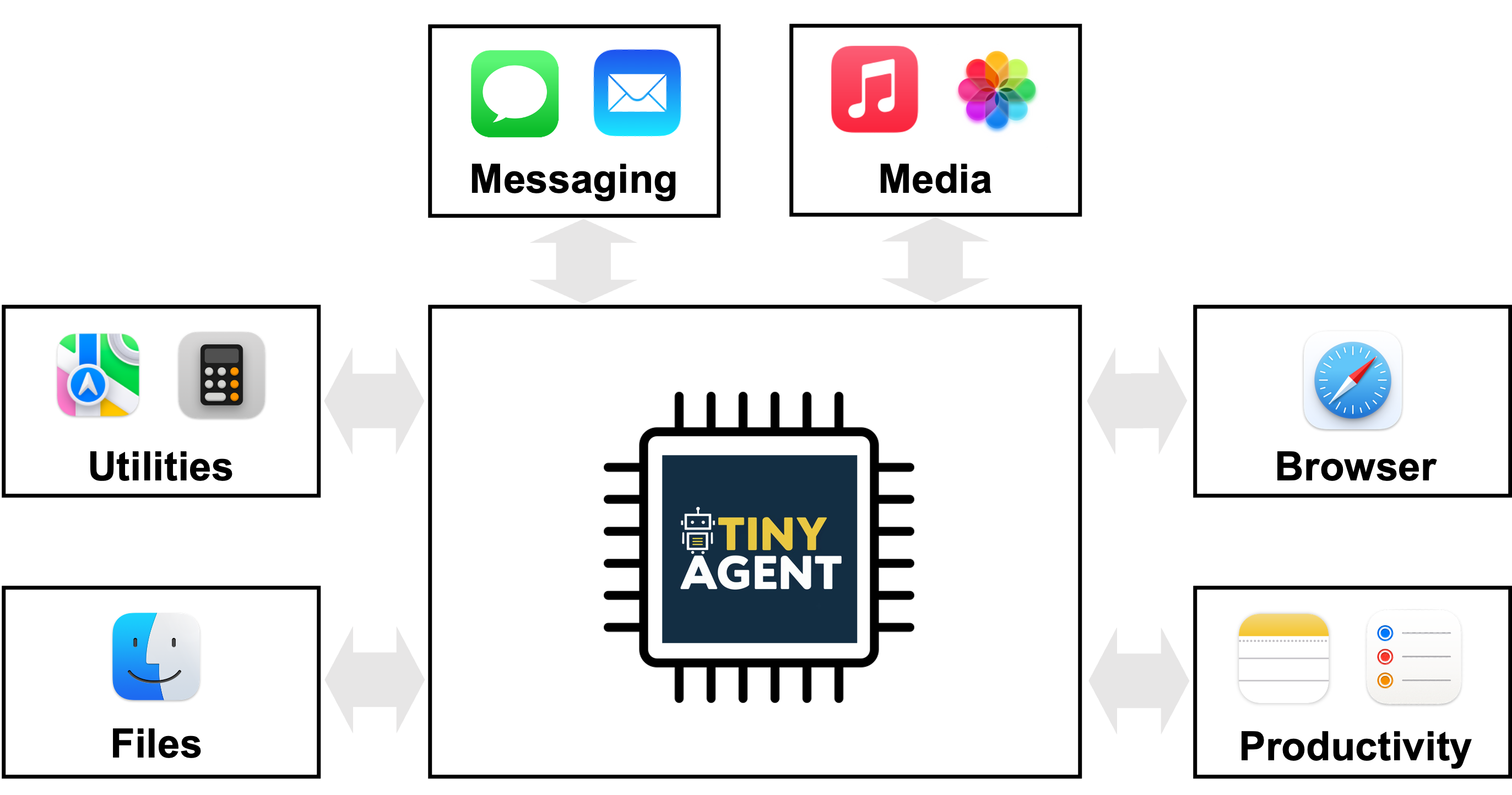
TinyAgent propose une voie pour déployer des agents alimentés par des modèles de langage sur des dispositifs de périphérie en mettant l’accent sur l’appel de fonctions plutôt que sur la mémorisation générale des connaissances. Des modèles volumineux comme GPT-4o ou Gemini-1.5 offrent de fortes capacités en nuage mais posent des défis de confidentialité, de connectivité et de latence à l’exécution locale. TinyAgent soutient qu’en entraînant des petits modèles de langage (SLMs) sur des données spécialisées et de haute qualité axées sur l’appel de fonctions et l’orchestration d’outils, il est possible d’obtenir des performances robustes en temps réel sur l’appareil sans dépendre d’une inference distante. Le projet se concentre sur l’idée que de nombreuses tâches d’agent se réduisent à sélectionner la bonne séquence de fonctions prédéfinies avec les entrées et l’ordre correct, plutôt que de rappeler des connaissances générales. Pour faciliter cela, le pipeline s’appuie sur un cadre appelé LLMCompiler qui va générer un plan d’appel de fonction – identifier quelles fonctions appeler, quelles entrées fournir et dans quel ordre – puis exécuter ces appels en tenant compte des dépendances. La question de recherche originale est de savoir si des modèles plus petits, open source, peuvent réaliser des appels de fonction fiables grâce à des données ciblées et un apprentissage adapté, atteignant des capacités de raisonnement et d’orchestration d’outils au niveau edge. L’étude TinyAgent illustre ces idées dans un contexte MacOS pour des applications drivers. La plateforme expose 16 fonctions prédéfinies qui interfacent avec des scripts Apple pour macOS. La tâche du modèle est de composer un plan d’appel de fonction correct qui utilise ces scripts pour accomplir les objectifs de l’utilisateur (par exemple, créer une invitation de calendrier sans fournir de réponses générales). Les auteurs explorent aussi la génération de données et les stratégies de fine-tuning pour réduire l’écart entre les petits modèles et des bases plus grandes basées sur le cloud. Les données synthétiques sont créées avec un modèle capable (par exemple GPT-4-Turbo) afin de produire des requêtes utilisateur réalistes, des plans d’appel et des arguments d’entrée, suivis de vérifications de sûreté pour assurer que les plans résultants forment des graphes valides. L’étude rapporte la création de 80k exemples d’entraînement, 1k exemples de validation et 1k exemples de test, avec un coût total de génération de données d’environ 500 $. Une métrique DAG évalue l’isomorphie entre le plan généré et le plan de référence. TinyAgent-1B, associé à Whisper-v3 pour la voix sur appareil, est démontré sur un MacBook M3 Pro. Le cadre est open source et disponible dans le dépôt GitHub officiel. En résumé, TinyAgent avance une voie pratique pour des agents d’edge : privilégier l’appel de fonctions correct plutôt que la mémorisation du savoir général, utilise un planificateur explicite d’orchestration des outils et démontre une mise en œuvre de bout en bout sur périphérique avec un cas d’utilisation macOS.
Fonctionnalités clés
- Modèles de langage petits et open source capables d’appels de fonction lorsque formés sur des données ciblées
- Cadre LLMCompiler qui produit un plan d’appel de fonctions avec les fonctions, les arguments et les dépendances
- Flux de génération de données de haute qualité (80k entraînement, 1k validation, 1k test) avec un LLM capable, permettant un planage spécifique à la tâche
- Voie de fine-tuning pour améliorer les performances d’appels de fonction des SLM, potentiellement supérieures à des bases plus grandes
- Méthode Tool RAG proposée pour améliorer l’efficacité et la performance
- Déploiement en périphérie : inférence locale sur l’appareil pour la confidentialité et la réactivité
- 16 fonctions prédéfinies pour macOS connectées à des scripts Apple
- Démonstration avec TinyAgent-1B et Whisper-v3 fonctionnant localement sur un MacBook M3 Pro
- Open source : disponible dans le dépôt officiel
Cas d’utilisation courants
- Assistants sémantiques en périphérie qui interprètent des requêtes en langage naturel et orchestrent une suite d’appels d’outils locaux (calendrier, contacts, e-mails) sans exposer les données au nuage
- Flux de travail de type Siri où l’agent traduit des commandes en appels précis d’APIs ou de scripts (par exemple, créer des invitations de calendrier avec des participants spécifiques) en utilisant des scripts prédéfinis
- Automatisation privée sur l’appareil où minimiser l’exposition des données est critique
- Agents fonctionnant en bordure qui opèrent dans des environnements avec connectivité intermittente ou inexistante tout en préservant la réactivité
Setup & installation
Les détails de configuration et d’installation ne sont pas fournis dans la source. Le cadre est annoncé comme open source; les instructions spécifiques ne sont pas données dans le texte.
Setup et installation non précisés dans la source fournie.
Consultez le dépôt : https://github.com/SqueezeAILab/TinyAgentDémarrage rapide (exemple minimal exécutable)
Le flux décrit se centre sur la conversion d’une requête en langage naturel en un plan d’appels de fonctions, puis sur l’exécution dans l’ordre correct. Un démarrage rapide conceptuel basé sur l’approche décrit pourrait ressembler à ceci (workflow pseudo):
- Un utilisateur fournit une commande en langage naturel (par exemple, « Créez une invitation de calendrier avec les participants A et B pour mardi prochain à 15h »).
- Le planner basé sur LLMCompiler produit un plan d’appel de fonction listant quelles fonctions appeler, leurs arguments (par exemple, courriels des participants, titre de l’événement, date/heure) et les dépendances entre les appels.
- Le système exécute chaque fonction dans l’ordre, en remplaçant les valeurs réelles pour les espaces réservés (par ex. $1, $2) lorsque les résultats des appels précédents deviennent disponibles.
- Le résultat final est la création de l’invitation de calendrier, avec les entrées validées par les scripts prédéfinis de macOS. Note : le flux ci-dessus décrit le fonctionnement prévu dans la source. Ce n’est pas un script exécutable fourni dans le matériel ; reportez-vous au dépôt TinyAgent pour les détails d’implémentation, les définitions de fonctions et les points d’intégration avec macOS.
Avantages et inconvénients
- Avantages
- Déploiement privé sur périphérie en conservant l’inférence sur l’appareil
- Potentiel de réduire la dépendance à la connectivité cloud et d’obtenir une latence plus faible
- Apprentissage guidé par des données curées de haute qualité pour l’appel de fonction
- Démonstration de la capacité à dépasser une baseline robuste en appel de fonction pour des petits modèles
- Voie claire pour étendre les agents sur périphérie via une approche explicite d’orchestration d’outils
- Inconvénients (dérivés de l’étude)
- Les petits modèles open source nécessitent un ajustement fin spécifique et des données ciblées pour des résultats fiables
- Requiert une génération et une vérification de données soignée et coûteuse à mettre en place
- Les résultats portent sur un cas d’utilisation MacOS avec 16 fonctions prédéfinies et peuvent ne pas être immédiatement généralisables à d’autres domaines
- Le coût et le processus de génération des données et l’évaluation de plans (sanité, vérification de l’isomorphie) représentent une charge pratique
Alternatives (courtes comparaisons)
- LLMs volumineux avec inférence cloud (par ex., GPT-4/GPT-4o) : forte capacité d’appel de fonction, mais questions de confidentialité et de connectivité; dépendance à une mémoire paramétrique massive et à l’accès cloud
- ToolFormer et Gorilla : exemples cités comme approches liées pour activer l’utilisation d’outils par les LLMs
- Approches basées sur LLaMA-2 70B : travaux précédents sur les appels de fonction avec de gros modèles; TinyAgent explore si des modèles plus petits peuvent atteindre des capacités similaires avec des données soignées et du fine-tuning
- Tool RAG : optimisation proposée pour améliorer l’efficacité et les performances du flux d’appels de fonction
Prix ou Licence
- Le cadre est décrit comme open source; les termes de licence explicites ne sont pas fournis dans la source. Le coût d’utilisation n’est pas spécifié.
Références
- Article du blog TinyAgent : http://bair.berkeley.edu/blog/2024/05/29/tiny-agent/
- Dépôt GitHub de TinyAgent : https://github.com/SqueezeAILab/TinyAgent
More resources

OpenAI GPT OSS : modèles MoE open-source (120B/20B) avec MXFP4 sous Apache 2.0
Deux modèles à poids ouverts (gpt-oss-120b et gpt-oss-20b) utilisant des Mixture-of-Experts et une quantification MXFP4 pour une inférence rapide et économe en mémoire. Licenciés Apache 2.0, adaptés aux déploiements privés/local et à l’exécution sur périphérique, avec intégration via Hugging Face In

Defending against Prompt Injection with Structured Queries (StruQ) and Preference Optimization (SecAlign)
Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks against them. Prompt injection attack is listed as the #1 threat by OWASP to LLM-integrated applications, where an LLM input contains a trusted prompt (ins

PLAID : Génération multimodale de protéines par diffusion latente
PLAID génère simultanément les séquences protéiques 1D et les structures 3D en apprenant l’espace latent des modèles de pliage protéique. Prompts de fonction et d’organisme, décodage avec des poids gelés ESMFold.

Élargissement de l’Apprentissage par Renforcement pour l’Aplanissement du Trafic : Déploiement sur une Autoroute avec 100 VAs
100 véhicules autonomes contrôlés par RL déployés sur l’I-24 pendant les heures de pointe pour atténuer les ondes d’arrêt-démarrage, améliorer le flux et réduire la consommation de carburant pour tous les usagers. Contrôle décentralisé via capteurs radar de base.

Anthology : Conditionnement des LLMs par des Backstories Riches pour des Personas Virtuelles
Une méthode pour guider les LLMs vers des personas virtuelles représentatifs et cohérents en générant des backstories détaillées et en les utilisant comme contexte de conditionnement, permettant des simulations individualisées et des études utilisateur à grande échelle.
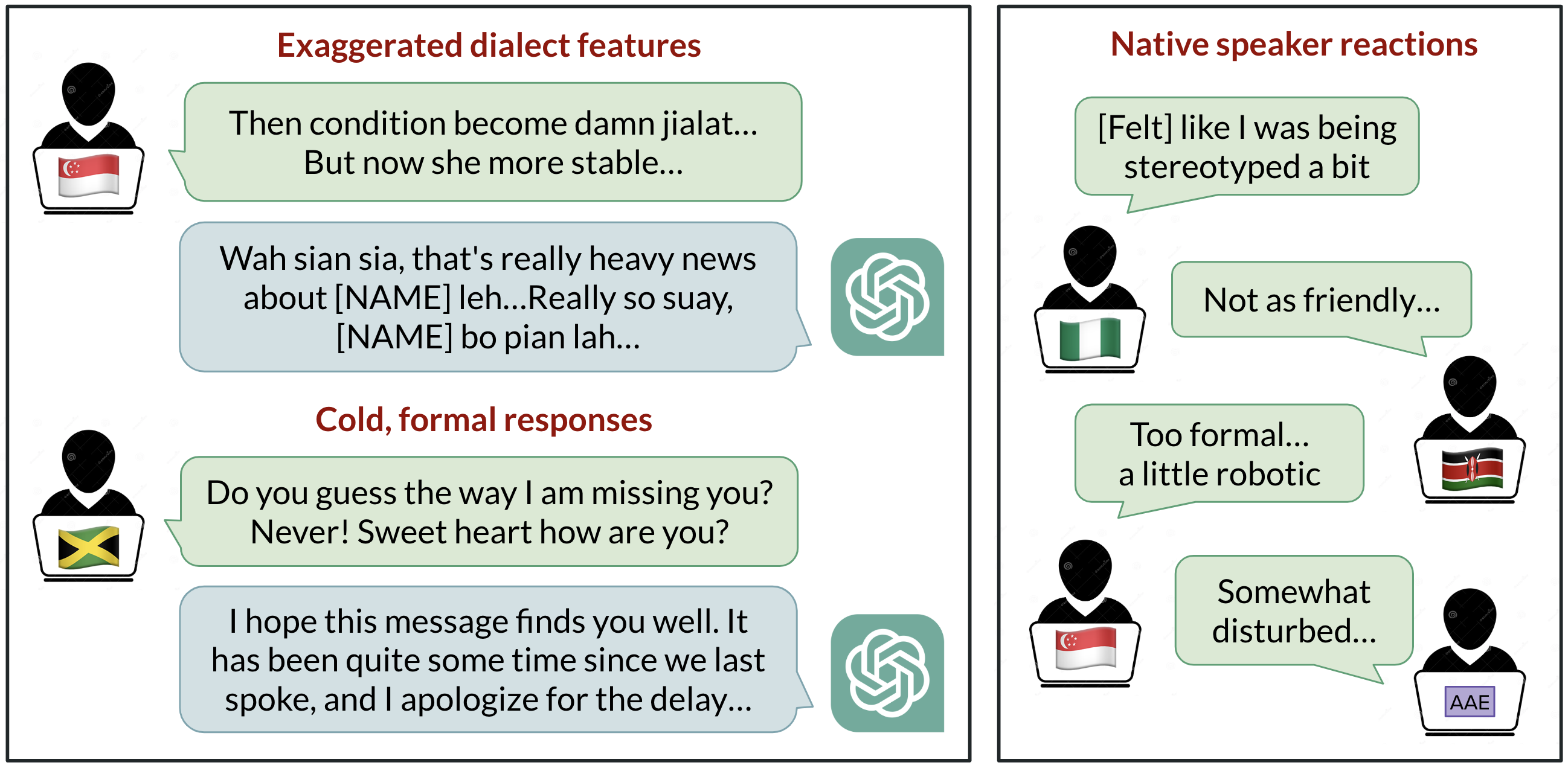
Biais linguistiques dans ChatGPT : discrimination selon les dialectes de l’anglais
Analyse de la manière dont ChatGPT réagit à divers dialectes de l’anglais, démontrant des biais contre les variantes non standard et leurs implications.