xT : Modélisation de très grandes images de bout en bout sur GPUs
Sources: http://bair.berkeley.edu/blog/2024/03/21/xt, http://bair.berkeley.edu/blog/2024/03/21/xt/, BAIR Blog
Aperçu
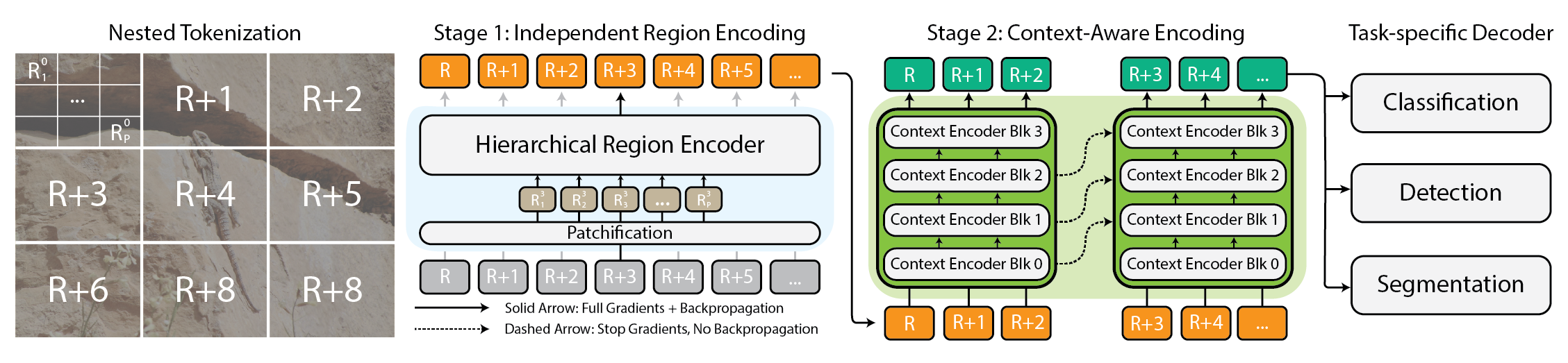
Modéliser des images extrêmement grandes est devenu une nécessité pratique à mesure que les caméras et capteurs génèrent des données gigapixel. Les approches traditionnelles peinent car l’usage mémoire croît de façon quadratique avec la taille de l’image, obligeant à sous-échantillonner ou recadrer, ce qui entraîne une perte d’informations et de contexte importants. xT propose un nouveau cadre permettant de modéliser des images énormes de bout en bout sur des GPUs modernes tout en agrégeant efficacement le contexte global avec des détails locaux. Au cœur, xT introduit une tokenisation imbriquée, une décomposition hiérarchique d’une image en régions et sous-régions traitées par des composants spécialisés avant d’être assemblés pour former une représentation globale. Dans xT, l’image est divisée en régions via la tokenisation imbriquée. Chaque région est traitée par un region encoder, qui peut être un backbone de vision de pointe tel que Swin, HierA, ConvNeXt, etc. Le region encoder agit comme un expert local et transforme les régions en représentations détaillées de manière isolée. Pour construire une image mondiale, le context encoder prend ces représentations régionales et modélise les dépendances à longue portée dans l’ensemble de l’image. Le context encoder est typiquement un modèle de séquences longues ; les auteurs testent Transformer-XL et une variante nommée Hyper, ainsi que Mamba, bien que Longformer et d’autres modèles de séquences longues soient également des options. La magie d xT réside dans sa combinaison tokenisation imbriquée, region encoders et context encoders. En divisant d’abord l’image en morceaux gérables, puis en les intégrant, xT préserve la fidélité des détails tout en incorporant des informations distantes. Cette approche end-to-end permet de traiter des images massives sur des GPUs modernes, évitant les goulets d’étranglement mémoire des méthodes traditionnelles. xT est évalué sur des benchmarks variés et exigeants, couvrant à la fois des tâches baselines et des tâches d’images à grande échelle. Il obtient une précision plus élevée sur les tâches en aval avec moins de paramètres et une mémoire par région significativement plus faible par rapport aux baselines de pointe. Les auteurs démontrent la capacité de modéliser des images aussi grandes que 29 000 × 25 000 pixels sur des GPUs A100 de 40 Go, alors que des baselines comparables atteignent leurs limites autour de 2 800 × 2 800. Les tâches couvrent la classification fines (iNaturalist 2018), la segmentation dépendante du contexte (xView3-SAR) et la détection (MS-COCO). Au-delà des aspects techniques, xT permet aux scientifiques et cliniciens de voir à la fois la forêt et les arbres : en surveillance environnementale, il aide à comprendre les changements à l’échelle du paysage tout en examinant les détails locaux; en santé, il peut aider au diagnostic en considérant le contexte global et les patches locaux. Bien que les auteurs ne prétendent pas avoir résolu tous les problèmes, ils présentent xT comme un pas important vers des modèles capables de concilier contexte à grande échelle et détails fins sur GPUs modernes. Un préprint est disponible sur arXiv et la page du projet fournit des liens vers le code et les poids libérés.
Caractéristiques clés
- Tokenisation imbriquée : décomposition hiérarchique en régions et sous-régions pour un traitement évolutif
- Encoders régionaux : backbones locaux spécialisés (Swin, HierA, ConvNeXt, etc.) qui transforment les régions en représentations détaillées
- Encoders de contexte : modèles de séquences longues (Transformer-XL, Hyper, Mamba ; Longformer et autres options possibles)
- End-to-end sur GPUs : images massives modélisées de bout en bout avec une empreinte mémoire gérable
- Contexte global et détail local : conserve les informations fines tout en intégrant le contexte de l’ensemble
- Révisions sur des tâches variées : précision accrue avec moins de paramètres et moins de mémoire par région sur iNaturalist 2018, xView3-SAR et MS-COCO
- Capacité d’images très grandes : démontrée jusqu’à 29k × 25k sur GPUs A100 de 40 Go; les baselines échouent plus tôt
- Code source ouvert : code et poids libérés sur la page du projet ; le papier sur arXiv est disponible
Cas d’utilisation
- Classification de espèces fines sur des images très grandes (iNaturalist 2018)
- Segmentation dépendante du contexte pour scènes grandes (xView3-SAR)
- Détection dans de grands ensembles de données (MS-COCO)
- Surveillance environnementale : voir les changements à l’échelle du paysage tout en examinant les détails locaux
- Imagerie en santé : aide au diagnostic en combinant contexte global et patches détaillés
Configuration et installation
Note : le texte ne fournit pas de commandes d’installation exactes. Consulter la page du projet pour le code et les poids.
# Setup & installation
# Commandes exactes non fournies dans la source.
# Veuillez consulter la page du projet pour le code et les poids.Démarrage rapide
Ce guide rapide est une esquisse conceptuelle illustrant le flux prévu ; il ne s’agit pas d’un exemple exécutable fourni par la source.
# Démarrage rapide (conceptuel)
# Charger une image grande (échelle gigapixel)
image = load_large_image('path/vers/image_gigante.png')
# Tokenisation imbriquée en régions et sous-régions
regions = nested_tokenize(image)
# Traitement local pour chaque région
local_features = [region_encoder(r) for r in regions]
# Fusionner les caractéristiques régionales avec le contexte global
global_context = context_encoder(local_features)
# Prédire avec la tâche spécifique
preds = head_classifier(global_context)
print(preds)Avantages et inconvénients
- Avantages
- Gestion end-to-end d’images massives sur des GPUs modernes
- Maintien des détails locaux tout en intégrant le contexte global
- Moindre mémoire par région avec potentiellement moins de paramètres que les baselines
- Démonstration de la capacité de traiter des images très grandes (29k × 25k) quand les méthodes traditionnelles échouent
- Flexibilité pour choisir les backbones régionaux et les modèles de contexte
- Applicabilité à des domaines variés, y compris l’écologie et la santé
- Inconvénients
- Requiert une configuration coordonnée des encodeurs régionaux et de contexte et potentiellement des modèles de séquence longue
- Les étapes exactes d’installation et d’entraînement ne sont pas détaillées dans la source
- C’est encore un cadre de recherche ; le déploiement pratique peut nécessiter une ingénierie soignée et du matériel adapté
Alternatives (brève comparaison)
- Sous-échantillonnage (down-sampling) : réduction de la taille de l’image avant traitement mais perte d’informations et de contexte
- Recadrage (cropping) : traite des patches locaux; risque de manquer le contexte global
- Autres backbones pour séquences longues (Longformer, Transformer-XL) : utilisés comme encodeurs de contexte dans xT; d’autres options peuvent être valables
- Traitement sur une seule résolution haute avec des optimisations mémoire : généralement non adapté aux images réellement gigantesques sans architectures spécialisées | Approche | Points forts | Limitations |---|---|---| | Down-sampling | Simple, faible mémoire | Perte de détails et de contexte |Cropping | Fokus local; modulaire | Contexte global fragmenté |xT (tokenisation imbriquée) | End-to-end, contexte global avec détails locaux | Mise en œuvre plus complexe |Autres backbones de séquences longues | Gère les dépendances à long terme | Coût potentiel élevé de mémoire/temps; intégration complexe |
Prix ou Licence
Les informations de licence ne sont pas fournies dans la source. La page du projet mentionne le code et les poids libérés, mais pas de licence explicite.
Références
More resources

CUDA Toolkit 13.0 pour Jetson Thor : Écosystème Arm Unifié et Plus
Kit CUDA unifié pour Arm sur Jetson Thor avec cohérence mémoire complète, partage du GPU entre processus, interop OpenRM/dmabuf, support NUMA et outils améliorés pour l’embarqué et le serveur.

Réduire les coûts de déploiement des modèles tout en conservant les performances grâce au swap de mémoire GPU
Exploitez le swap mémoire GPU (hot-swapping de modèles) pour partager les GPUs entre plusieurs LLM, réduire les coûts inoccupés et améliorer l’auto-Scaling tout en respectant les SLA.

Amélioration de l’auto-tuning GEMM avec nvMatmulHeuristics dans CUTLASS 4.2
Présente nvMatmulHeuristics pour sélectionner rapidement un petit ensemble de configurations de kernels GEMM à fort potentiel pour CUTLASS 4.2, réduisant considérablement le temps de tuning tout en approchant les performances d’une Recherche Exhaustive.

Accélérez ZeroGPU Spaces avec la compilation ahead-of-time (AoT) de PyTorch
Découvrez comment la compilation AoT de PyTorch accélère ZeroGPU Spaces en exportant un modèle compilé et en le rechargeant instantanément, avec quantification FP8, formes dynamiques et intégration au flux Spaces GPU.

Comment détecter et corriger 5 goulets d'étranglement pandas avec cudf.pandas
Ressource technique pour développeurs présentant cinq goulets d'étranglement courants, des solutions CPU et GPU, et l'accélération GPU en mode drop-in via cudf.pandas.

À l'intérieur du NVIDIA Blackwell Ultra : la puce qui propulse l'ère des usines d'IA
Profil détaillé du Blackwell Ultra, sa conception à double die NV‑HBI, sa précision NVFP4, ses 288 Go HBM3e par GPU et ses interconnexions système pour les usines IA et l'inférence à grande échelle.