
PLAID: Generación multimodal de proteínas con difusión latente
Sources: http://bair.berkeley.edu/blog/2025/04/08/plaid, http://bair.berkeley.edu/blog/2025/04/08/plaid/, BAIR Blog
Visión general
PLAID es un modelo generativo multimodal que genera simultáneamente la secuencia 1D de proteínas y la estructura 3D, aprendiendo el espacio latente de modelos de plegamiento de proteínas. En contexto de reconocimiento del papel de la IA en biología, PLAID aborda qué sigue después del plegamiento. PLAID aprende a muestrear desde el espacio latente de modelos de plegamiento para generar nuevas proteínas y puede responder a indicaciones compuestas que especifican función y organismo. El entrenamiento puede realizarse con datos de secuencias solamente, ya que las bases de datos de secuencias son mucho más grandes que las de estructuras. La idea central es hacer difusión en el espacio latente de un modelo de plegamiento en lugar de difundir directamente en el espacio de secuencias o estructuras. Tras muestrear el embedding, se decodifica tanto la secuencia como la estructura usando pesos congelados de un modelo de plegamiento. En la práctica, PLAID utiliza ESMFold — sucesor de AlphaFold2 — que reemplaza una etapa de recuperación por un modelo de lenguaje proteico, durante la inferencia. Este enfoque aprovecha priors aprendidos por modelos de plegamiento preentrenados para tareas de diseño proteico, mientras que el entrenamiento se apoya en datos de secuencias. Un aspecto clave es la gestión de la alta dimensionalidad de los espacios latentes en modelos basados en transformadores. Para ello se propone CHEAP (Compressed Hourglass Embedding Adaptations of Proteins), que aprende un modelo de compresión para la incrustación conjunta de secuencia y estructura. El espacio latente resulta ser altamente comprensible y, mediante interpretabilidad, se ha logrado generar modelos autorreconstruidos a nivel all-atom en ciertos casos. Aunque el estudio se centra en generación secuencia–estructura, señalan que el método podría adaptarse a generación multimodal para otros dominios cuando existe un predictor entre modalidades. PLAID también ofrece una interfaz de control mediante prompts, inspirada en cómo la generación de imágenes se guía con restricciones textuales. El objetivo final es el control total por texto, pero actualmente se pueden imponer restricciones compuestas en dos ejes: función y organismo. Los autores muestran capacidades como aprender patrones de coordinación tetraédrica en metaloproteínas (por ejemplo, coordinación de cysteína-Fe2+/Fe3+) mientras mantienen diversidad a nivel de secuencia. En comparaciones con baselines de estructuras atómicas, PLAID muestra mejor diversidad y captura patrones beta que han sido difíciles para otros enfoques. Si está interesado en colaborar para ampliar el método o probarlo en laboratorio, los autores invitan a contactarlos. También señalan preprints y bases de código para PLAID y CHEAP.
Características clave
- Generación multimodal: secuencias y coordenadas estructurales atómicas
- Diffusion latente: muestrea desde el espacio latente de un modelo de plegamiento y luego decodifica
- Entrenamiento en secuencias solamente: aprovecha grandes bases de datos de secuencias
- Decodificación con pesos congelados: la estructura se decodifica a partir del embedding muestreado usando ESMFold
- Compresión CHEAP: aprende una incrustación conjunta comprimida
- Prompts de función y organismo: control por entradas compuestas
- Interpretabilidad y motivos: análisis de canales latentes y patrones emergentes
- Diversidad: las muestras de PLAID muestran mayor diversidad y mejor recaptura de motivos que algunos baselines
- Extensibilidad: el enfoque podría adaptarse a generación multimodal en dominios donde haya un predictor entre modalidades
- Integración con priors existentes: aprovecha modelos de plegamiento preentrenados
Casos de uso comunes
- Diseño de proteínas con función y organismo deseados
- Exploración de espacios de diseño multimodal mediante prompts de función u organización taxonómica
- Generar candidatos con secuencias y estructuras diversas que respeten la relación función–estructura aprendida
- Extender la generación multimodal a sistemas más complejos (p. ej., complejos proteicos o interacciones con ligandos o ácidos nucleicos)
- Aprovechar grandes bases de datos de secuencias para entrenar modelos capaces de generar estructuras a partir de embeddings latentes
Configuración e instalación
No se proporciona en la fuente.
# Configuración e instalación no proporcionadas en la fuente.Inicio rápido
Nota: este es un ejemplo ilustrativo basado en los principios de PLAID; las APIs y entornos reales dependerán de los códigos publicados.
# PLAID quick-start (ilustrativo)
# Flujo conceptual, no código listo para ejecutar
# 1) Muestrear un embedding latente desde el modelo de difusión
z = sample_latent_embedding()
# 2) Decodificar secuencia y estructura usando pesos congelados de ESMFold
sequence = decode_sequence_from_embedding(z)
structure = decode_structure_from_embedding(z, frozen_weights="ESMFold")
print(sequence)
print(structure)Pros y contras
- Pros
- Generación conjunta de secuencia y estructura guiada por prompts
- Aprovecha grandes bases de datos de secuencias para el entrenamiento
- Decodificación de estructura mediante pesos congelados, reduciendo la necesidad de entrenar un modelo de plegamiento completo
- CHEAP aborda la compresión del embedding conjunto y mejora la factibilidad
- Demuestra control por prompts y promete control textual total en el futuro
- Diversidad y capacidad de capturar motivos estructurales complejos en comparación con baselines
- Contras
- Espacios latentes grandes requieren regularización y manejo cuidadoso
- El éxito depende de la calidad de los priors de plegamiento y la coherencia entre secuencia y estructura
- La utilidad real depende de prompts variados y de una decodificación robusta para estructuras complejas
- La ampliación multimodal aún está en desarrollo y depende de avances en predictores entre modalidades
Alternativas (breve comparación)
| Enfoque | Modalidad | Ventajas | Limitaciones |---|---|---|---| | PLAID | Secuencia + estructura | Generación multimodal con difusión latente; entrenamiento en secuencias | Requiere un modelo de plegamiento como backbone; la calidad depende de la regularización |Generadores tradicionales de estructura | Estructura únicamente | Alta plausibilidad estructural gracias a priors de plegamiento | No genera secuencia ni ofrece control multimodal explícito |Modelos centrados en secuencias | Secuencia solamente | Amplia cobertura de datos de secuencia | No proporciona coordenadas estructurales sin un predictor adicional |
Licencia o precio
Los detalles de licencia o precios no se especifican en la fuente.
Referencias
- PLAID: Repurposing Protein Folding Models for Generation with Latent Diffusion — BAIR Blog, http://bair.berkeley.edu/blog/2025/04/08/plaid/
- Preprints y bases de código mencionados en la fuente; no se proporcionan URL explícitas aquí.
More resources

Defending against Prompt Injection with Structured Queries (StruQ) and Preference Optimization (SecAlign)
Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks against them. Prompt injection attack is listed as the #1 threat by OWASP to LLM-integrated applications, where an LLM input contains a trusted prompt (ins

Escalando el RL para Suavizar el Tráfico: Despliegue de 100 VEs en una Autopista
100 coches controlados por RL desplegados en la I-24 durante la hora punta para atenuar las ondas de parada y arranque, mejorar el flujo y reducir el consumo de combustible para todos los usuarios. Control descentralizado con sensores radar básicos.

Anthology: Condicionando LLMs con Backstories Ricas para Personas Virtuales
Un método para guiar a los LLMs hacia personas virtuales representativas y consistentes generando narrativas de vida detalladas y utilizándolas como contexto de condicionamiento, para simulaciones individualizadas y estudios de usuario escalables.
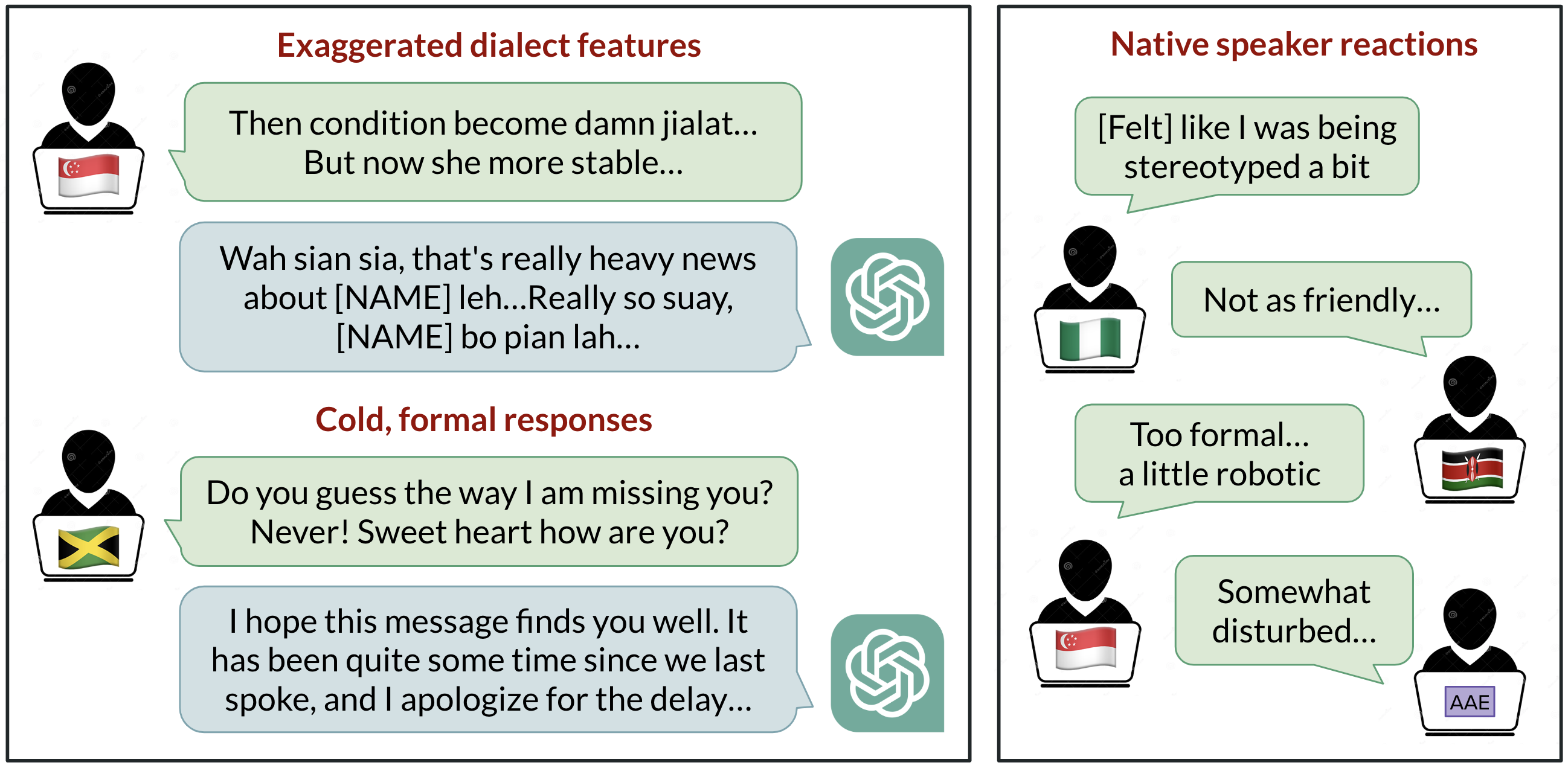
Sesgo lingüístico en ChatGPT: discriminación por dialectos en las variedades del inglés
Análisis de cómo ChatGPT responde a diferentes dialectos del inglés, destacando sesgos contra variedades no estándar y sus implicaciones.

StrongREJECT: Benchmark sólido para evaluar jailbreaks en LLMs
Visión general de un benchmark de jailbreak de alta calidad con dos evaluadores automatizados, un conjunto de 313 prompts prohibidos y hallazgos sobre la brecha entre resultados publicados y evaluaciones rigurosas.

Visual Haystacks (VHs): Benchmark de razonamiento visual multi-imagen
Benchmark de razonamiento visual de contexto largo en grandes conjuntos de imágenes no correlacionadas; presenta MIRAGE para ampliar LMMs más allá del VQA de una imagen.