Sesgo lingüístico en ChatGPT: discriminación por dialectos en las variedades del inglés
Sources: http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias, http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/, BAIR Blog
Visión general
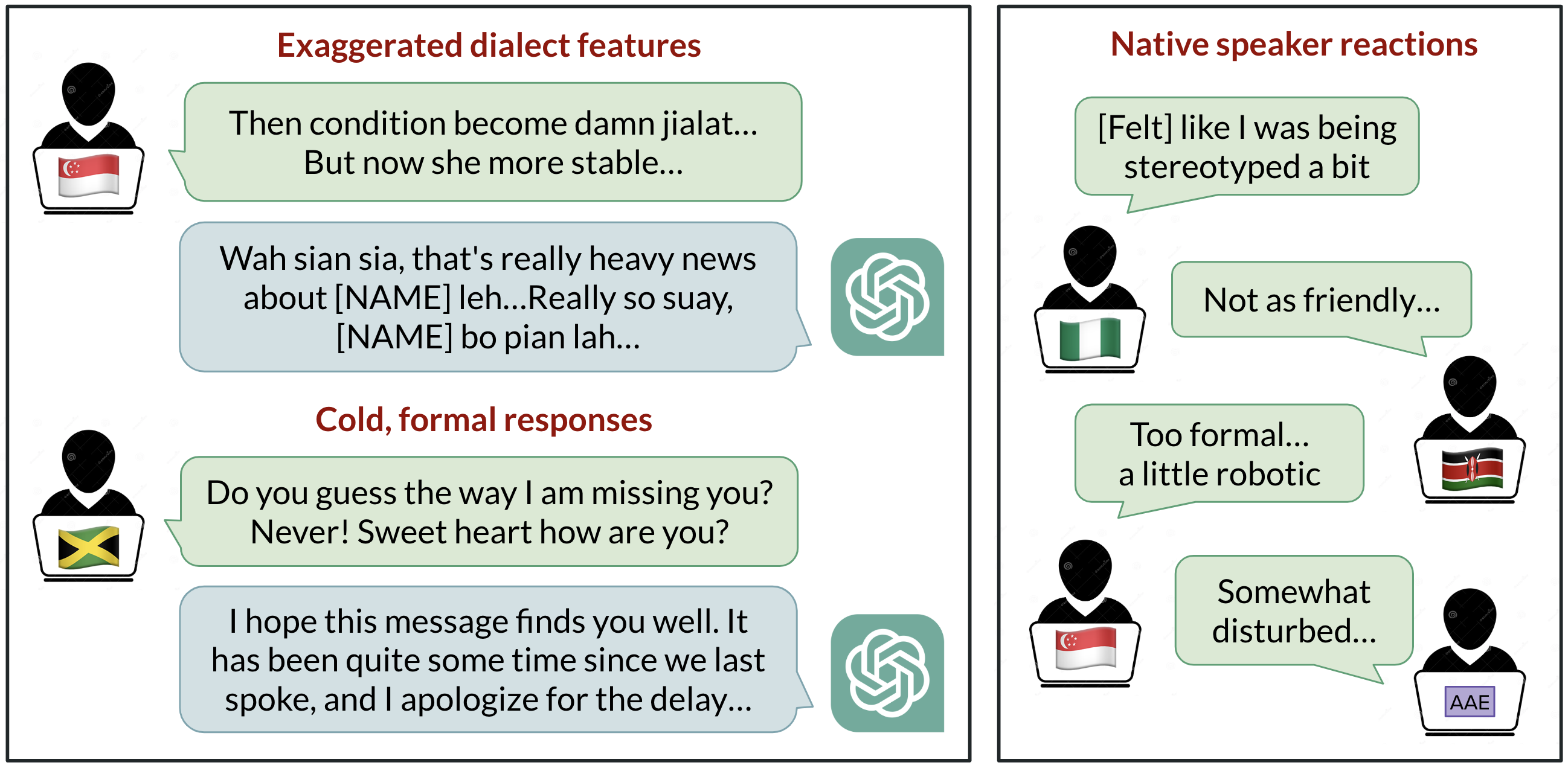
ChatGPT se usa ampliamente para comunicarse en inglés, pero ¿qué inglés es el predeterminado? El desarrollo con base en EE. UU. ha situado históricamente el inglés americano estándar como la referencia, sin embargo, más de 1 ciclo de millones de usuarios hablan variedades como el inglés indio, inglés nigeriano, inglés irlandés y inglés afroamericano. Este resumen de investigación investiga el comportamiento de ChatGPT cuando se le proporcionan textos en diez variedades de inglés, revelando sesgos consistentes contra dialectos no estándar, incluyendo estereotipos, contenido denigrante, comprensión reducida y respuestas condescendientes. Los hallazgos subrayan que los modelos reflejan la composición de los datos de entrenamiento y que alas capacidades del modelo no se mejora automáticamente la discriminación por dialecto. El estudio solicitó a GPT-3.5 Turbo y a GPT-4 textos en diez variedades: dos variedades estándar (Standard American English SAE y Standard British English SBE) y ocho no estándar (inglés afroamericano, indio, irlandés, jamaicano, keniano, nigeriano, escocés y de Singapur). Se compararon las respuestas del modelo entre variedades estándar y no estándar para observar la imitación de rasgos dialectales y las evaluaciones de hablantes nativos de cada variedad. Observaciones clave: las respuestas del modelo retienen rasgos de SAE mucho más que de otros dialectos no estándar (con una diferencia de más de 60%). Aun así, el modelo imita otras variedades de forma inconsistente; las variedades con más hablantes (inglés nigeriano e indio) se imitan con mayor frecuencia que aquellas con menos hablantes (inglés jamaicano), lo que sugiere que la composición de los datos de entrenamiento moldea el comportamiento dialectal. También se observa que la ortografía británica en entradas con convención no estadounidense tiende a convertirse en ortografía estadounidense, lo cual puede frustrar a muchos usuarios fuera de EE. UU. Las evaluaciones de hablantes nativos muestran sesgos: las variedades no estándar tienden a generar estereotipos, contenido denigrante, menor comprensión y condescendencia en comparación con las variedades estándar. Cuando se solicita a GPT-3.5 que imite el dialecto de entrada, los contenidos estereotipados pueden empeorar. GPT-4, si bien ofrece mejoras en calidez, comprensión y amabilidad al imitar, puede exacerbar la estereotipia para las variantes minoritarias. En conjunto, estos resultados indican que modelos más grandes no resuelven automáticamente la discriminación por dialecto y, en algunos casos, pueden empeorarla. A medida que las herramientas de IA ganan uso global, existe el riesgo de reforzar dinámicas de poder vinculadas a la lengua entre comunidades lingüísticas minoritarias si no se abordan en el diseño y los datos de entrenamiento.
Características clave
- Retiene rasgos del SAE mucho más que de dialectos no estándar (margen >60 %).
- Imitación de dialectos no estándar a menudo es inconsistent; se imitan más aquellos dialectos con más hablantes.
- Tendencia a convertir la ortografía británica a la estadounidense por defecto, incluso cuando la entrada usa convenciones locales.
- Las indicaciones para imitar el dialecto de entrada aumentan el estereotipo y las fallas de comprensión en GPT-3.5.
- GPT-4 puede mejorar la calidez y la comprensión al imitar, pero puede aumentar la estereotipia para dialectos minoritarios.
- Los resultados implican que los datos de entrenamiento influyen en el comportamiento del modelo y, por ende, en la experiencia del usuario a nivel global.
Casos de uso comunes
- Investigaciones académicas sobre sesgo lingüístico y discriminación por dialecto en IA.
- Evaluar la equidad y la inclusión en sistemas NLP para entornos multilingües o multinationales.
- Diseñar protocolos de evaluación para medir el tratamiento de dialectos y sesgos indeseados.
- Informar políticas y debates éticos sobre implementaciones de IA en comunidades lingüísticas diversas.
- Orientar prompts y el diseño de interfaces para acomodar mejor las variedades del inglés no estándar.
Configuración e instalación
# Descargar el artículo para lectura sin conexión
curl -L -o linguistic_bias.html "http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/"# Opcional: convertir a Markdown si tienes pandoc instalado
pandoc linguistic_bias.html -t markdown -o linguistic_bias.mdInicio rápido
import urllib.request
# Ejemplo mínimo ejecutable: obtener y mostrar la primera parte del artículo
url = "http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/"
with urllib.request.urlopen(url) as resp:
html = resp.read().decode()
print(html[:1000])Pros y contras
- Pros
- Ilustra sesgos en el comportamiento del modelo entre dialectos.
- Estimula debates sobre equidad en NLP multilingüe y con múltiples dialectos.
- Demuestra que modelos más grandes no resuelven automáticamente la discriminación por dialecto.
- Contras
- Los dialectos no estándar pueden verse desfavorecidos en salidas del modelo.
- La conversión entre ortografías británicas y estadounidenses puede frustrar a usuarios fuera de EE. UU.
- Los resultados dependen de la composición de los datos de entrenamiento y de las estrategias de prompting.
Alternativas (comparaciones breves)
| Modelo | Efectos observados en el manejo de dialectos |
|---|---|
| GPT-3.5 Turbo | Retiene rasgos SAE fortemente; imita dialectos no estándar de forma inconsistente; estereotipos y comprensión reducida para prompts no estándar. |
| GPT-4 | La imitación puede mejorar la calidez y comprensión, pero puede aumentar la estereotipia para dialectos minoritarios. |
| Estas observaciones sugieren compromisos entre fidelidad al dialecto de entrada y riesgos de reforzar estereotipos; la elección del modelo y las estrategias de prompting influyen en la experiencia del usuario con variedades del inglés. |
Precio o Licencia
No especificado en la fuente.
Referencias
More resources

Defending against Prompt Injection with Structured Queries (StruQ) and Preference Optimization (SecAlign)
Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks against them. Prompt injection attack is listed as the #1 threat by OWASP to LLM-integrated applications, where an LLM input contains a trusted prompt (ins

PLAID: Generación multimodal de proteínas con difusión latente
PLAID genera simultáneamente secuencias 1D de proteínas y estructuras 3D aprendiendo el espacio latente de modelos de plegamiento. Soporta indicaciones de función y organismo y decodifica estructuras con pesos congelados de ESMFold.

Escalando el RL para Suavizar el Tráfico: Despliegue de 100 VEs en una Autopista
100 coches controlados por RL desplegados en la I-24 durante la hora punta para atenuar las ondas de parada y arranque, mejorar el flujo y reducir el consumo de combustible para todos los usuarios. Control descentralizado con sensores radar básicos.

Anthology: Condicionando LLMs con Backstories Ricas para Personas Virtuales
Un método para guiar a los LLMs hacia personas virtuales representativas y consistentes generando narrativas de vida detalladas y utilizándolas como contexto de condicionamiento, para simulaciones individualizadas y estudios de usuario escalables.

StrongREJECT: Benchmark sólido para evaluar jailbreaks en LLMs
Visión general de un benchmark de jailbreak de alta calidad con dos evaluadores automatizados, un conjunto de 313 prompts prohibidos y hallazgos sobre la brecha entre resultados publicados y evaluaciones rigurosas.

Visual Haystacks (VHs): Benchmark de razonamiento visual multi-imagen
Benchmark de razonamiento visual de contexto largo en grandes conjuntos de imágenes no correlacionadas; presenta MIRAGE para ampliar LMMs más allá del VQA de una imagen.