TinyAgent: Llamadas a funciones en el borde para modelos de lenguaje pequeños
Sources: http://bair.berkeley.edu/blog/2024/05/29/tiny-agent, http://bair.berkeley.edu/blog/2024/05/29/tiny-agent/, BAIR Blog
Visión general
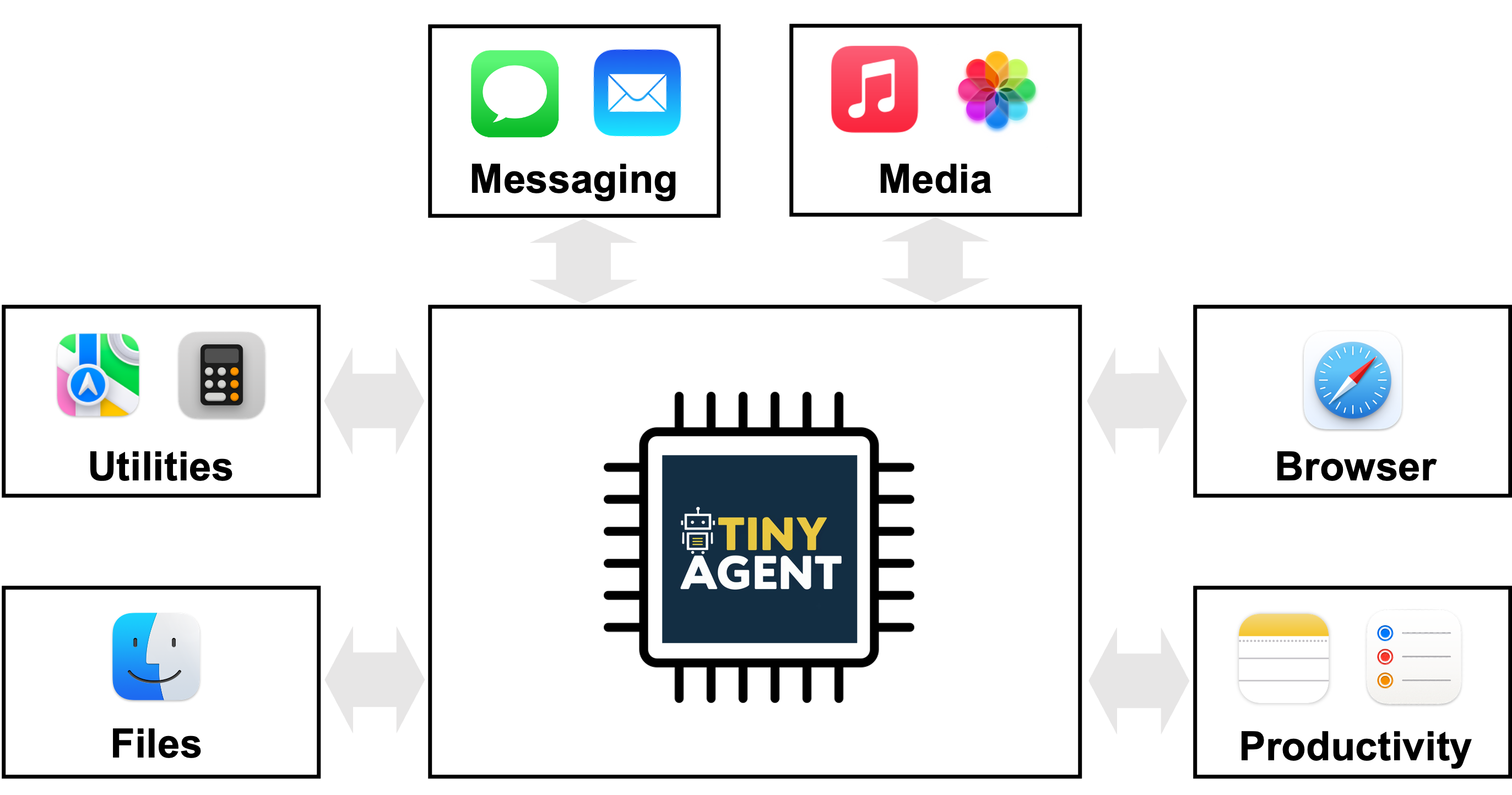
TinyAgent propone una vía para desplegar agentes basados en modelos de lenguaje en dispositivos de borde, enfocándose en la llamada de funciones en lugar de la memorización de conocimientos generales. Modelos grandes como GPT-4o o Gemini-1.5 ofrecen capacidades fuertes en la nube, pero plantean desafíos de privacidad, conectividad y latencia cuando se ejecutan en el borde. TinyAgent sostiene que, entrenando modelos de lenguaje pequeños (SLMs) con datos especializados y de alta calidad centrados en la llamada de funciones y la orquestación de herramientas, es posible lograr un rendimiento robusto y en tiempo real sin depender de la inferencia remota. El proyecto se centra en la idea de que muchas tareas de agentes se reducen a seleccionar la secuencia correcta de funciones predefinidas con las entradas adecuadas y en el orden correcto, en lugar de recordar conocimientos generales. Para lograrlo, el pipeline se apoya en un marco llamado LLMCompiler que genera un plan de llamada de función: qué funciones llamar, qué entradas requieren y qué dependencias hay entre las llamadas, para luego ejecutarlas respetando esas dependencias. La pregunta de investigación original es si modelos pequeños, de código abierto, pueden realizar llamadas a funciones fiables con datos supervisados y una formación específica, alcanzando capacidades de razonamiento y orquestación de herramientas a nivel edge. El estudio TinyAgent ilustra estas ideas en un contexto de aplicación con macOS. La plataforma expone 16 funciones predefinidas que se integran con las aplicaciones de macOS mediante scripts de Apple. La tarea del modelo es componer un plan de llamadas de función correcto que utilice estos scripts para lograr los objetivos del usuario (por ejemplo, crear una invitación de calendario sin dar respuestas tipo pregunta-respuesta). Los autores también exploran la generación de datos y estrategias de ajuste fino para reducir la brecha entre modelos pequeños y grandes basados en la nube. Los datos sintéticos se generan con un modelo capaz (por ejemplo, GPT-4-Turbo) para producir consultas de usuario realistas, planes de llamadas y argumentos de entrada, seguidos de verificaciones de sanidad para asegurar que los planes resultantes formen grafos válidos. El estudio reporta la creación de 80k ejemplos de entrenamiento, 1k de validación y 1k de prueba, con un costo total de generación de datos de aproximadamente 500 $. Una métrica DAG evalúa la isomorfía entre el plan generado y el plan de referencia. TinyAgent-1B, emparejado con Whisper-v3 para voz en el dispositivo, se demuestra en un MacBook M3 Pro. El marco es de código abierto y está disponible en el repositorio de GitHub oficial. En resumen, TinyAgent propone una vía práctica para agentes en el borde: priorizar la llamada de funciones correcta en lugar de la memorización de conocimientos generales, usar un planificador explícito de orquestación de herramientas y demostrar una implementación de extremo a extremo en el borde con un caso de uso práctico en macOS.
Características clave
- Modelos de lenguaje pequeños y de código abierto capaces de realizar llamadas a funciones cuando se entrenan con datos dirigidos
- Marco LLMCompiler que genera un plan de llamadas de funciones con las funciones, entradas y dependencias
- Flujo de generación de datos de alta calidad (80k de entrenamiento, 1k de validación, 1k de pruebas) con un LLM capaz, para permitir planificación específica de tareas
- Ruta de ajuste fino para mejorar el rendimiento de llamadas de funciones de los SLM, potencialmente superando a bases más grandes
- Método propuesto Tool RAG para mejorar la eficiencia y el rendimiento
- Despliegue en borde: inferencia local en el dispositivo para la privacidad y la reactividad
- 16 funciones predefinidas para macOS conectadas a scripts de Apple
- Demostración con TinyAgent-1B y Whisper-v3 funcionando localmente en un MacBook M3 Pro
- Open source disponible en el repositorio oficial
Casos de uso comunes
- Asistentes semánticos en borde que interpretan consultas en lenguaje natural y orquestan una secuencia de llamadas a herramientas locales (calendario, contactos, correo) sin exponer datos a la nube
- Flujo de trabajo al estilo Siri donde el agente traduce comandos en invocaciones precisas de APIs o scripts (por ejemplo, crear invitaciones de calendario con participantes específicos) usando scripts predefinidos
- Automatización privada en el dispositivo donde la exposición de datos se minimiza
- Agentes habilitados para borde que operan en entornos con conectividad intermitente o nula manteniendo la capacidad de respuesta
Setup e instalación
Los detalles de configuración e instalación no se proporcionan en la fuente. El marco se describe como código abierto; el repositorio está disponible en:
- https://github.com/SqueezeAILab/TinyAgent Para los lectores interesados en pasos prácticos, consulte el repositorio para instrucciones de instalación, dependencias y ejemplos de uso. El material fuente enfatiza la arquitectura, el flujo de generación de datos y el caso de uso de despliegue en borde, más que una guía paso a paso.
Setup e instalación no especificados en la fuente.
Consulte el repositorio: https://github.com/SqueezeAILab/TinyAgentInicio rápido (ejemplo mínimo ejecutable)
El flujo descrito se centra en traducir una consulta en lenguaje natural a un plan de llamadas de función y luego ejecutarlas en el orden correcto. Un inicio rápido conceptualmente podría ser:
- El usuario proporciona una orden en lenguaje natural (por ejemplo, “Crea una invitación de calendario con los participantes A y B para la próxima martes a las 15:00”).
- El planificador basado en LLMCompiler genera un plan de llamadas de función que enumera qué funciones llamar, sus argumentos de entrada (por ejemplo, correos de los participantes, título del evento, fecha y hora) y las dependencias entre llamadas.
- El sistema ejecuta cada función en orden, sustituyendo valores reales en marcadores de posición (p. ej., $1, $2) a medida que los resultados de llamadas anteriores se vuelven disponibles.
- El resultado final es la creación del ítem de calendario, con las entradas validadas por los scripts predefinidos de macOS. Nota: el flujo anterior describe el funcionamiento previsto en la fuente. No es un script ejecutable proporcionado en el material; consulte el repositorio TinyAgent para detalles de implementación, definiciones de funciones y puntos de integración con macOS.
Pros y contras
- Pros
- Despliegue privado en borde manteniendo la inferencia en el dispositivo
- Potencial reducción de dependencia de conectividad en la nube y menor latencia
- Aprendizaje guiado por datos curados de alta calidad para llamadas de función
- Demuestra capacidad de superar una referencia sólida en llamadas de función para modelos pequeños
- Caminos claros para ampliar agentes en borde mediante una aproximación explícita de orquestación de herramientas
- Contras (según el estudio)
- Modelos pequeños fuera de la caja requieren ajuste fino específico y datos dirigidos
- Requiere generación y verificación cuidadosa de datos, con un costo asociado
- Los resultados están centrados en un caso de uso de macOS con 16 funciones y pueden no generalizar inmediatamente a otros dominios
- Los costos de generación de datos y la evaluación de planes (sanidad, isomorfía) no son triviales en la práctica
Alternativas (comparaciones breves)
- Modelos grandes con inferencia en la nube (p. ej., GPT-4/GPT-4o): ofrecen fuerte capacidad de llamada de función, pero plantean preocupaciones de privacidad y conectividad; dependen de una gran memoria paramétrica y acceso a la nube
- ToolFormer y Gorilla: ejemplos mencionados como enfoques relacionados para habilitar el uso de herramientas por LLMs en entornos de agente
- Enfoques basados en LLaMA-2 70B: trabajos previos que exploraron llamadas de función con modelos grandes; TinyAgent investiga si modelos más pequeños pueden igualar estas capacidades con datos curados y ajuste fino
- Tool RAG: optimización propuesta para mejorar la eficiencia y el rendimiento del flujo de llamadas de función
Precio o Licencia
- El marco es descrito como código abierto; los términos de licencia explícitos no se proporcionan en la fuente. El costo de uso no está especificado.
Referencias
- Blog de TinyAgent: http://bair.berkeley.edu/blog/2024/05/29/tiny-agent/
- Repositorio de TinyAgent en GitHub: https://github.com/SqueezeAILab/TinyAgent
More resources

Defending against Prompt Injection with Structured Queries (StruQ) and Preference Optimization (SecAlign)
Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks against them. Prompt injection attack is listed as the #1 threat by OWASP to LLM-integrated applications, where an LLM input contains a trusted prompt (ins

PLAID: Generación multimodal de proteínas con difusión latente
PLAID genera simultáneamente secuencias 1D de proteínas y estructuras 3D aprendiendo el espacio latente de modelos de plegamiento. Soporta indicaciones de función y organismo y decodifica estructuras con pesos congelados de ESMFold.

Escalando el RL para Suavizar el Tráfico: Despliegue de 100 VEs en una Autopista
100 coches controlados por RL desplegados en la I-24 durante la hora punta para atenuar las ondas de parada y arranque, mejorar el flujo y reducir el consumo de combustible para todos los usuarios. Control descentralizado con sensores radar básicos.

Anthology: Condicionando LLMs con Backstories Ricas para Personas Virtuales
Un método para guiar a los LLMs hacia personas virtuales representativas y consistentes generando narrativas de vida detalladas y utilizándolas como contexto de condicionamiento, para simulaciones individualizadas y estudios de usuario escalables.
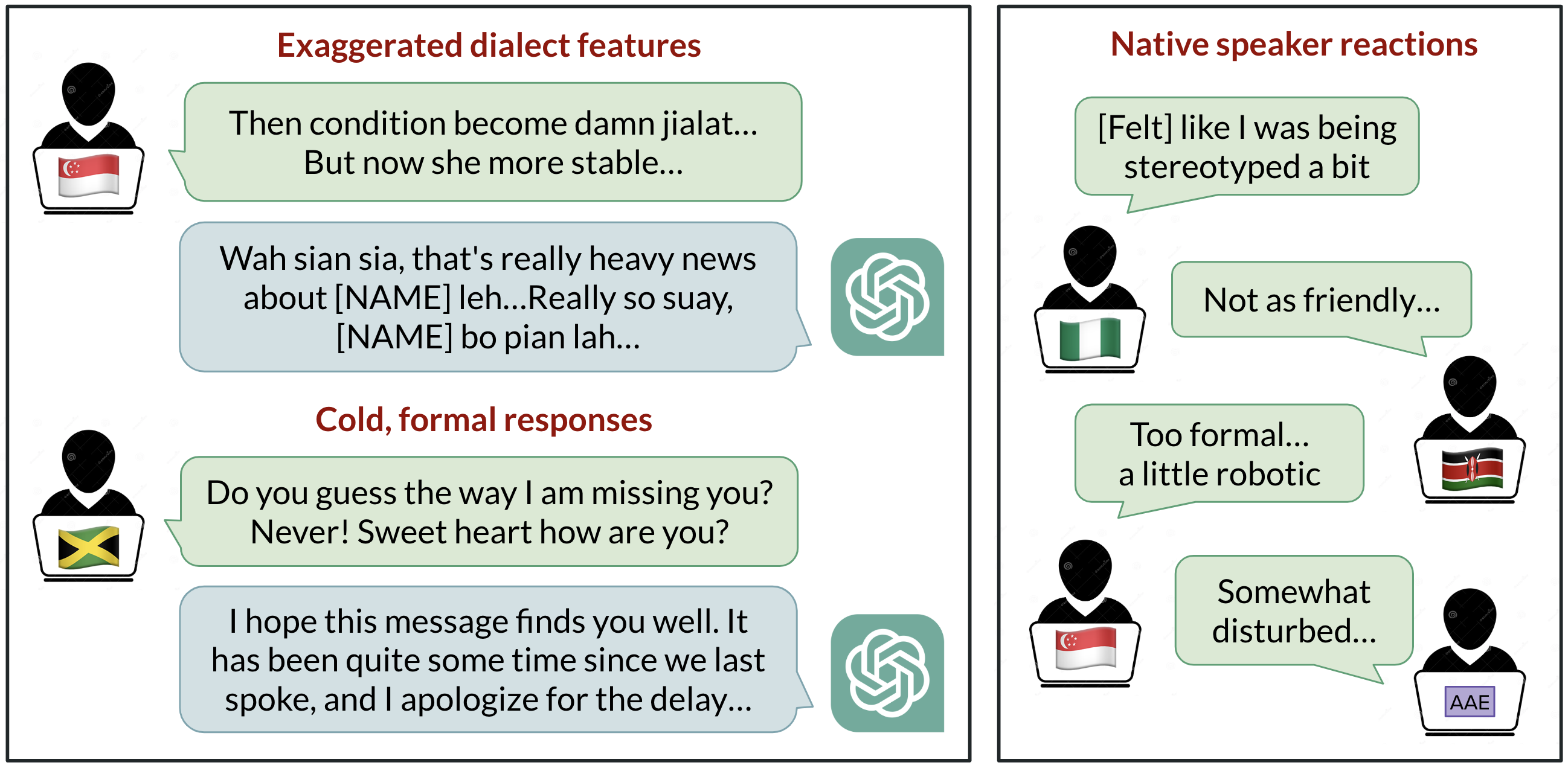
Sesgo lingüístico en ChatGPT: discriminación por dialectos en las variedades del inglés
Análisis de cómo ChatGPT responde a diferentes dialectos del inglés, destacando sesgos contra variedades no estándar y sus implicaciones.

StrongREJECT: Benchmark sólido para evaluar jailbreaks en LLMs
Visión general de un benchmark de jailbreak de alta calidad con dos evaluadores automatizados, un conjunto de 313 prompts prohibidos y hallazgos sobre la brecha entre resultados publicados y evaluaciones rigurosas.