xT: Modelado de imágenes extremadamente grandes de extremo a extremo en GPUs
Sources: http://bair.berkeley.edu/blog/2024/03/21/xt, http://bair.berkeley.edu/blog/2024/03/21/xt/, BAIR Blog
Visión general
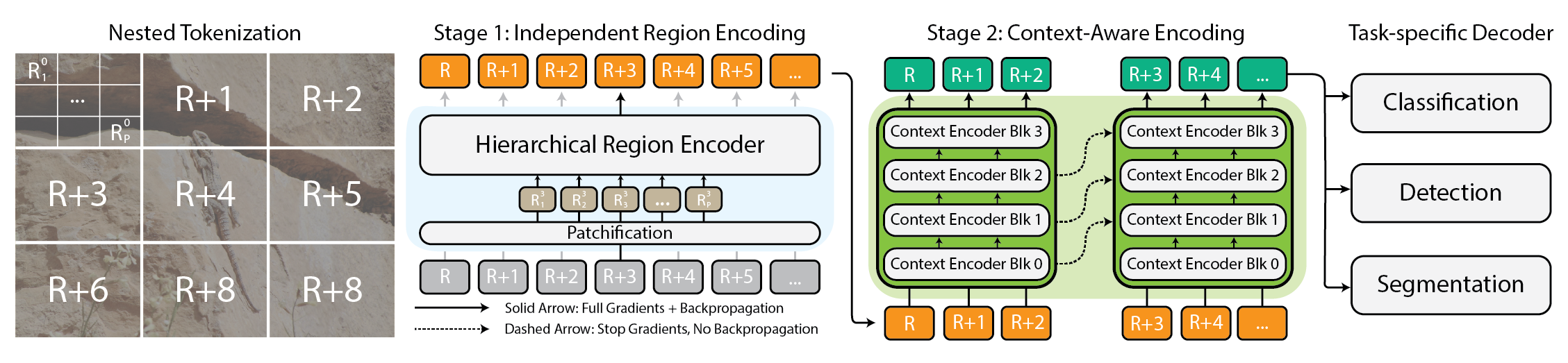
Modelar imágenes extremadamente grandes se ha convertido en una necesidad práctica a medida que las cámaras y sensores generan datos de gigapíxeles. Los enfoques tradicionales luchan porque el uso de memoria crece de manera cuadrática con el tamaño de la imagen, obligando a muestrear a menor resolución o recortar, lo que provoca la pérdida de información y contexto importante. xT propone un nuevo marco para modelar imágenes muy grandes de forma end-to-end en GPUs contemporáneas, agregando eficazmente contexto global con detalles locales. En su núcleo, xT introduce la tokenización anidada, una descomposición jerárquica de una imagen en regiones y subregiones que son procesadas por componentes especializados antes de ensamblarlas para formar una representación global. En xT, la imagen se divide en regiones mediante la tokenización anidada. Cada región es tratada por un region encoder, que puede ser un backbone de visión de última generación como Swin, HierA, ConvNeXt, entre otros. El region encoder funciona como un experto local y transforma las regiones en representaciones detalladas de forma aislada. Para construir una imagen global, el context encoder toma estas representaciones regionales y modela dependencias de largo alcance en toda la imagen. El context encoder suele ser un modelo de secuencias largas; los autores prueban Transformer-XL y una variante llamada Hyper, además de Mamba, aunque Longformer y otros modelos de secuencias largas también son opciones viables. La magia de xT reside en su combinación de tokenización anidada, region encoders y context encoders. Dividiendo la imagen en piezas manejables y luego integrándolas, xT mantiene la fidelidad de los detalles mientras incorpora información distante. Este procesamiento end-to-end permite modelar imágenes masivas en GPUs modernas, evitando los cuellos de botella de memoria de los enfoques tradicionales. xT se evalúa en conjuntos de datos desafiantes que abarcan tareas de baselines establecidos y tareas de imágenes grandes. Obtiene mayor precisión en las tareas de downstream con menos parámetros y una memoria por región significativamente menor frente a baselines de punta. Los autores demuestran la capacidad de modelar imágenes de hasta 29,000 × 25,000 píxeles en GPUs A100 de 40 GB, mientras que los baselines comparables quedan sin memoria a aproximadamente 2,800 × 2,800. Las tareas incluyen clasificación de especies finas (iNaturalist 2018), segmentación dependiente del contexto (xView3-SAR) y detección (MS-COCO). Más allá de los aspectos técnicos, xT permite a científicos y médicos ver tanto el bosque como los árboles: en monitoreo ambiental ayuda a entender cambios a gran escala junto con detalles locales; en salud, podría ayudar a diagnosticar al considerar el contexto amplio y parches detallados. Aunque los autores no afirman haber resuelto todos los problemas, presentan xT como un paso significativo hacia modelos que pueden equilibrar contexto a gran escala con detalles finos en GPUs modernas. Un preprint está disponible en arXiv y la página del proyecto ofrece enlaces al código y pesos liberados.
Características clave
- Tokenización anidada: descomposición jerárquica en regiones y sub-regiones para procesamiento escalable
- Encoders regionales: backbones locales especializados (Swin, HierA, ConvNeXt, etc.) que transforman las regiones en representaciones detalladas
- Encoders de contexto: modelos de secuencias largas (Transformer-XL, Hyper, Mamba; Longformer y otros son posibles) que conectan las representaciones regionales
- End-to-end en GPUs: imágenes masivas modeladas de extremo a extremo con una huella de memoria manejable
- Contexto global con detalle local: mantiene información fina al integrar el contexto de toda la imagen
- Evaluaciones en benchmarks variados: mayor precisión con menos parámetros y menos memoria por región respecto a baselines de punta
- Capacidad para imágenes muy grandes: demostrada hasta 29k × 25k en GPUs A100 de 40 GB; baselines equivalentes fallan antes
- Código abierto: código y pesos liberados en la página del proyecto; el artículo en arXiv está disponible
Casos de uso comunes
- Clasificación de especies finas en imágenes muy grandes (iNaturalist 2018)
- Segmentación dependiente del contexto en escenas grandes (xView3-SAR)
- Detección en grandes conjuntos de datos (MS-COCO)
- Monitoreo ambiental: ver cambios a gran escala junto con detalles locales
- Imagenología médica: ayuda al diagnóstico considerando el contexto global y parches detallados
Configuración e instalación
Nota: el texto no proporciona comandos exactos de instalación. Consulte la página del proyecto para código y pesos.
# Setup & instalación
# Comandos exactos no proporcionados en la fuente.
# Consulte la página del proyecto para código y pesos.Inicio rápido
Este esquema rápido es un boceto conceptual que ilustra el flujo previsto; no es una receta ejecutable proporcionada por la fuente.
# Inicio rápido (conceptual)
# Cargar una imagen grande (escala gigapixel)
image = load_large_image('path/para/imagen_gigante.png')
# Tokenización anidada en regiones y sub-regiones
regions = nested_tokenize(image)
# Procesamiento local para cada región
local_features = [region_encoder(r) for r in regions]
# Fusionar características regionales con el contexto global
global_context = context_encoder(local_features)
# Predecir con la tarea específica
preds = head_classifier(global_context)
print(preds)Pros y contras
- Pros
- Manejo end-to-end de imágenes masivas en GPUs modernas
- Mantiene detalles locales a la vez que integra el contexto global
- Menor memoria por región con potencial para menos parámetros que baselines
- Demostración de soporte para imágenes muy grandes (29k × 25k) cuando los enfoques tradicionales fallan
- Flexibilidad para elegir backbones regionales y modelos de contexto
- Aplicable a dominios diversos, incluida ecología y salud
- Contras
- Requiere una configuración coordinada de encodeurs regionales y de contexto y posiblemente modelos de secuencias largas
- Los pasos exactos de instalación y entrenamiento no están detallados en la fuente
- Es un marco de investigación; la implementación práctica puede requerir ingeniería y hardware específico
Alternativas (breve comparación)
- Muestreo hacia abajo (down-sampling): reduce el tamaño de la imagen antes del procesamiento, pero se pierde información y contexto
- Recorte (cropping): procesa parches locales; puede romper el contexto global
- Otros backbones de secuencias largas (Longformer, Transformer-XL): usados como encodeurs de contexto en xT; otras opciones pueden ser viables
- Procesamiento en una única resolución alta con optimizaciones de memoria: típicamente no viable para imágenes realmente gigantes sin arquitecturas especializadas | Enfoque | Fortalezas | Limitaciones |---|---|---| | Down-sampling | Simple, baja memoria | Pérdida de detalles y contexto |Cropping | Enfoque local; modular | Contexto global fragmentado |xT (tokenización anidada) | End-to-end, contexto global con detalles | Mayor complejidad de implementación |Otros backbones de secuencias largas | Maneja dependencias largas | Costos potenciales de memoria/tiempo; integración compleja |
Precio o Licencia
La información de licencia no se proporciona en la fuente. La página del proyecto menciona código y pesos liberados, pero no hay licencia explícita.
Referencias
More resources

CUDA Toolkit 13.0 para Jetson Thor: Ecosistema Unificado de Arm y Más
Kit CUDA unificado para Arm en Jetson Thor con coherencia de memoria total, uso compartido de GPU entre procesos, interoperabilidad OpenRM/dmabuf, soporte NUMA y herramientas mejoradas para embebidos y servidores.

Reducir costos de implementación de modelos manteniendo el rendimiento con intercambio de memoria de GPU
Utiliza el intercambio de memoria de GPU (hot-swapping de modelos) para compartir GPUs entre varios LLM, reducir costos de GPU ociosas y mejorar el autoescalado manteniendo los SLA.

Mejora del autoajuste de GEMM con nvMatmulHeuristics en CUTLASS 4.2
Presenta nvMatmulHeuristics para seleccionar rápidamente un conjunto corto de configuraciones de kernels GEMM con alto potencial para CUTLASS 4.2, reduciendo drásticamente el tiempo de ajuste y acercándose al rendimiento de una búsqueda exhaustiva.

Haz ZeroGPU Spaces más rápido con la compilación ahead-of-time (AoT) de PyTorch
Descubre cómo la compilación AoT de PyTorch acelera ZeroGPU Spaces exportando un modelo compilado y recargándolo al instante, con cuantización FP8, formas dinámicas e integración con Spaces GPU.

Cómo detectar y resolver 5 cuellos de botella de rendimiento en pandas con cudf.pandas
Guía técnica para desarrolladores sobre cinco cuellos de botella comunes de pandas, soluciones CPU/GPU y aceleración GPU con cudf.pandas sin cambiar el código.

Dentro de NVIDIA Blackwell Ultra: el chip que impulsa la era de la fábrica de IA
Perfil detallado de Blackwell Ultra, su diseño de doble dado NV‑HBI, precisión NVFP4, 288 GB HBM3e por GPU e interconexiones de sistema para fábricas de IA e inferencia a gran escala.