vec2text: Invirtiendo embeddings de texto e implicaciones de seguridad
Sources: https://thegradient.pub/text-embedding-inversion, https://thegradient.pub/text-embedding-inversion/, The Gradient
Visión general
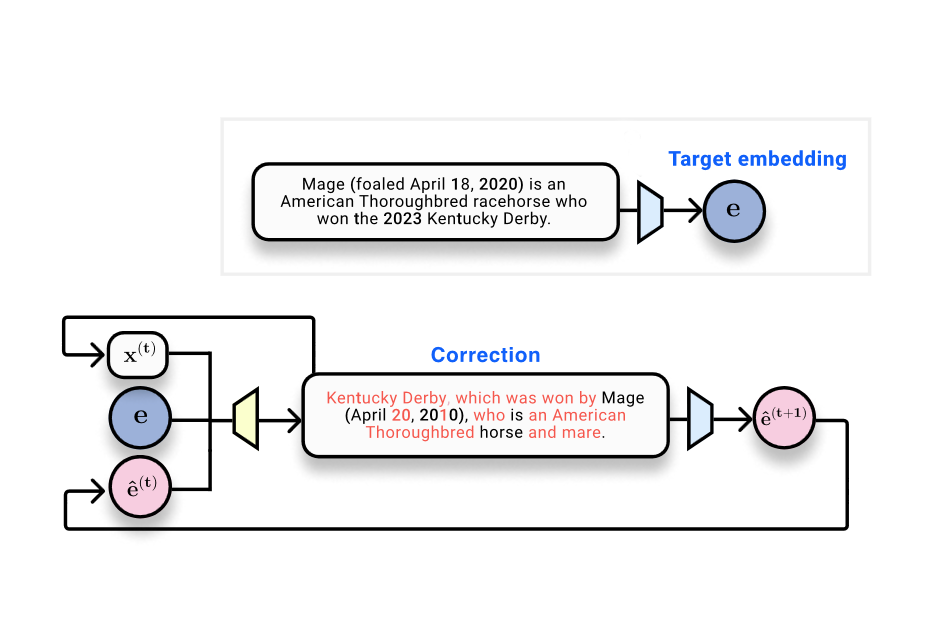
Los sistemas de Recuperación Aumentada por Generación (RAG) almacenan y buscan documentos utilizando embeddings, que son representaciones vectoriales del texto producidas por modelos de embedding. The Gradient plantea una cuestión clave: ¿se puede recuperar el texto de entrada a partir de sus embeddings? El artículo sitúa los embeddings en el contexto de bases de datos vectoriales y las preocupaciones de privacidad asociadas al almacenamiento de embeddings en lugar del texto en claro. Se cita el estudio Text Embeddings Reveal As Much as Text (EMNLP 2023), que aborda directamente la inversión: ¿se puede reconstruir el texto a partir de embeddings de salida? Desde el punto de vista técnico, los embeddings son el resultado de redes neuronales: el texto se tokeniza, se procesa a través de capas no lineales y finalmente se reduce a un vector fijo de tamaño. La literatura de procesamiento de información sugiere que tales transformaciones no pueden aumentar la información de la entrada; pueden conservar o perder información. En visión por computadora, existen resultados que demuestran que las imágenes pueden reconstruirse a partir de representaciones profundas, lo que motiva la investigación en el dominio del texto. Un escenario de juguete considera 32 tokens mapeados a embeddings de 768 dimensiones (32 × 768 = 24,576 bits, aproximadamente 3 kB). Esto establece un marco para evaluar cuán bien se puede recuperar el texto original. El artículo presenta una progresión de métodos y métricas para responder a esta pregunta. Un primer enfoque trata la inversión como un problema de aprendizaje automático: recopilar pares embedding–texto y entrenar un modelo para generar el texto a partir del embedding. En este setting, un transformador entrenado para generar texto a partir del embedding obtiene un BLEU de alrededor de 30/100 y una tasa de coincidencia exacta cercana a cero, ilustrando la dificultad de una reversión perfecta en una única pasada. Una observación clave es que, cuando el texto generado se re-embeda, el embedding resultante está muy cercano al embedding original: similitud coseno alrededor de 0,97. Esto confirma que el texto hipotesis permanece cercano en el espacio de embeddings, incluso cuando el texto superficial difiere. La idea central es pasar de una inversión en una sola pasada a un proceso de optimización aprendido que opere en el espacio de embeddings. Dado un embedding de referencia (el objetivo), un texto de hipótesis y su embedding, un modelo corrector se entrena para producir un texto que se acerque al objetivo. Este es el núcleo de vec2text: un optimizador aprendido que actualiza el texto en pasos discretos para alinearse con el embedding de referencia. Tras implementar este enfoque, los autores reportan una mejora notable: un único paso de corrección eleva el BLEU de ~30 a ~50. Además, vec2text puede usarse de forma recursiva: generar hipótesis, re-embedarlas y alimentarlas de nuevo para más actualizaciones. Con aproximadamente 50 iteraciones, el método recupera 92% de secuencias de 32 tokens exactamente y alcanza un BLEU de ~97. En otras palabras, para este entorno limitado, el vector de embedding contiene suficientes bits para reconstruir casi por completo el texto original, no solo su significado semántico. La conclusión es clara: los embeddings pueden invertirse con alta fidelidad en la práctica, lo que plantea importantes preguntas sobre la seguridad y la privacidad de sistemas de almacenamiento y transmisión basados en embeddings. El artículo también señala ciertas advertencias. En primer lugar, el embedding tiene una capacidad fija, por lo que existen límites teóricos a cuánta información puede almacenarse y recuperarse. En segundo lugar, los autores discuten la posibilidad de que la función de embedding sea perdedora (mapeando múltiples entradas al mismo embedding), lo que dificultaría la identificación; en sus experimentos, no observaron colisiones. Por último, el texto sitúa este resultado en un marco más amplio: si el texto puede reconstruirse casi por completo a partir de embeddings, entonces hay consideraciones de seguridad para bases de datos vectoriales y servicios que manejan embeddings. Para quienes quieran el trasfondo técnico, el artículo establece paralelismos con la inversión de imágenes y cita la literatura relevante, destacando que un estudio de EMNLP 2023 motiva la inversión desde el lado del texto: consulte el enlace para un tratamiento detallado y especificaciones experimentales: Text Embeddings Reveal As Much as Text.
Características clave
- vec2text: un enfoque de optimización aprendida que toma un embedding de referencia, un texto de hipótesis y su posición en el espacio de embeddings para predecir la secuencia de texto exacta.
- Iteración en el espacio de embeddings: el método admite refinamiento recursivo al re-embedar el texto generado y alimentarlo de nuevo para nuevas actualizaciones.
- Ganancias de rendimiento demostradas: una corrección única eleva BLEU de ~30 a ~50; con ~50 pasos, recuperación exacta en 92% de secuencias de 32 tokens y BLEU cercano a 97.
- Proximidad en el espacio de embeddings: el texto generado a menudo produce embeddings muy parecidos al embedding original (similitud coseno ~0,97), incluso cuando el texto superficial difiere.
- Implicaciones de seguridad y privacidad: la capacidad de invertir embeddings subraya preocupaciones para almacenamiento y uso de embeddings.
- Marco teórico: conecta la inversión de embeddings con ideas de pérdida de información y requisitos de seguridad.
- Contexto interdominios: paralelos con trabajos de inversión de imágenes que inspiran estas preocupaciones en el dominio textual.
Casos de uso comunes
- Flujos RAG que dependen de la búsqueda por embeddings: los vectores en una base de datos vectorial representan documentos, y la similitud dirige la recuperación. Si los embeddings pueden invertirse para recuperar el texto, surge un riesgo de privacidad para datos almacenados como vectores.
- Escenarios de fuga de embeddings: exposiciones accidentales o accesos de proveedores a embeddings podrían, en teoría, permitir la reconstrucción del contenido textual protegido, sujeto a la capacidad del modelo y a los patrones de acceso.
- Implicaciones de seguridad para bases de datos vectoriales: las organizaciones pueden necesitar revisar políticas de retención de datos, controles de acceso y modelos de riesgo ante posibles inversiones.
- Interés de investigación: vec2text demuestra que la inversión no es solo posible, sino que puede mejorarse con corrección iterativa, informando enfoques futuros sensibles a la seguridad en el diseño de embeddings.
Setup & instalación
No se proporciona en el material fuente. Si evalúas la seguridad de embeddings en tu stack, considera acciones de alto nivel:
# No proporcionado en el textoQuick start
- Partir de un embedding de referencia E y una hipótesis de texto H. Calcular el embedding de H, compararlo con E y aplicar el modelo de corrección vec2text para predecir un texto más cercano al objetivo.
- Re-embedar el texto corregido, comparar embeddings y repetir el proceso. Este bucle recursivo es el núcleo de la aproximación vec2text y mostró mejoras sustanciales en fidelidad de superficie.
- En el entorno de juguete descrito (32 tokens, embedding de 768 dimensiones), las tentativas iniciales producen un BLEU de aproximadamente 30; iteraciones más largas pueden acercar el BLEU a 97 con suficientes pasos y alcanzar recuperación exacta en la mayor parte de las secuencias.
Ventajas y desventajas
- Ventajas
- Inversión de alta fidelidad: demostrada recuperación casi perfecta para un conjunto de 32 tokens tras varias iteraciones.
- Iteración conceptualmente simple: aprovecha re-embedding y correcciones para converger hacia el texto de referencia.
- Define un camino mensurable hacia la inversión desde embeddings con métricas claras (BLEU, coincidencia exacta, similitud coseno).
- Puede usarse recursivamente para un refinamiento progresivo en escenarios de decodificación iterativa.
- Desventajas
- Riesgo para la privacidad: la capacidad de invertir embeddings subraya posibles filtraciones de datos en almacenamiento y uso de embeddings.
- No universal: la fidelidad de recuperación se demuestra en un entorno de juguete específico; textos reales más largos pueden presentar desafíos.
- Límites de capacidad de embeddings: existe una capacidad de bits fija, imponiendo límites a la información que puede almacenarse y recuperarse.
- Posibles ambigüedades: aunque se logra alta fidelidad, no siempre se garantiza coincidencia exacta; colisiones (múltiples entradas para el mismo embedding) son una preocupación teórica, pero no se observaron en estos experimentos.
Alternativas (comparaciones breves)
- Inversión directa con un transformer entrenado para mapear embeddings a texto: la línea base mostró BLEU ~30 y coincidencia exacta cercana a cero, lo que ilustra la dificultad sin refinamiento iterativo.
- Inversión de embeddings de imágenes: en visión por computadora, trabajos muestran que las imágenes pueden reconstruirse a partir de representaciones profundas, lo que motiva preocupaciones de inversión trans-dominio. Dosovitskiy (2016) es citado como ejemplo temprano.
- Perspectiva más amplia: las representaciones de embeddings son deliberadamente lossy, equilibrando utilidad semántica con compresión; sin embargo, los resultados de inversión revelan recuperaciones significativas en ciertos escenarios.
Precio o Licencia
No especificado en el material.
Referencias
More resources

IA General No Es Multimodal: Inteligencia centrada en el Encarnamiento
Recurso conciso que explica por qué las arquitecturas multimodales basadas en escalado probablemente no conducen a una AGI y por qué los modelos del mundo embebidos son esenciales.

Forma, Simetrías y Estructura: El papel cambiante de las matemáticas en la investigación de ML
Analiza cómo las matemáticas siguen siendo centrales en ML, pero su rol se expande hacia geometría, simetrías y explicaciones post-hoc a gran escala.

Qué falta en los chatbots de LLM: un sentido de propósito
Explora el diálogo con propósito en chatbots LLM, argumentando que las interacciones de varias vueltas alinean mejor la IA con los objetivos del usuario y facilitan la colaboración, especialmente en código y asistentes personales.

Visiones positivas de la IA basadas en el bienestar
Un marco centrado en el bienestar para IA beneficiosa, que une ciencias del bienestar, economía y gobernanza para delinear visiones prácticas y accionables de despliegue que apoyen el florecimiento individual y social.

Aplicaciones de LLMs en mercados financieros — visión general y casos de uso
Visión general de cómo los LLMs pueden aplicarse a los mercados financieros, incluyendo modelado autoregresivo de datos de precios, entradas multimodales, residualización, datos sintéticos y predicciones de múltiples horizontes.

Visión general sobre sesgos de género en IA
Resumen de trabajos clave que miden sesgos de género en IA, abarcando embeddings, co-referencia, reconocimiento facial, benchmarks de QA y generación de imágenes; discusión de mitigación, lagunas y auditoría robusta.