Linguistic Bias in ChatGPT: Dialect Discrimination Across English Varieties
Sources: http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias, http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/, BAIR Blog
Overview
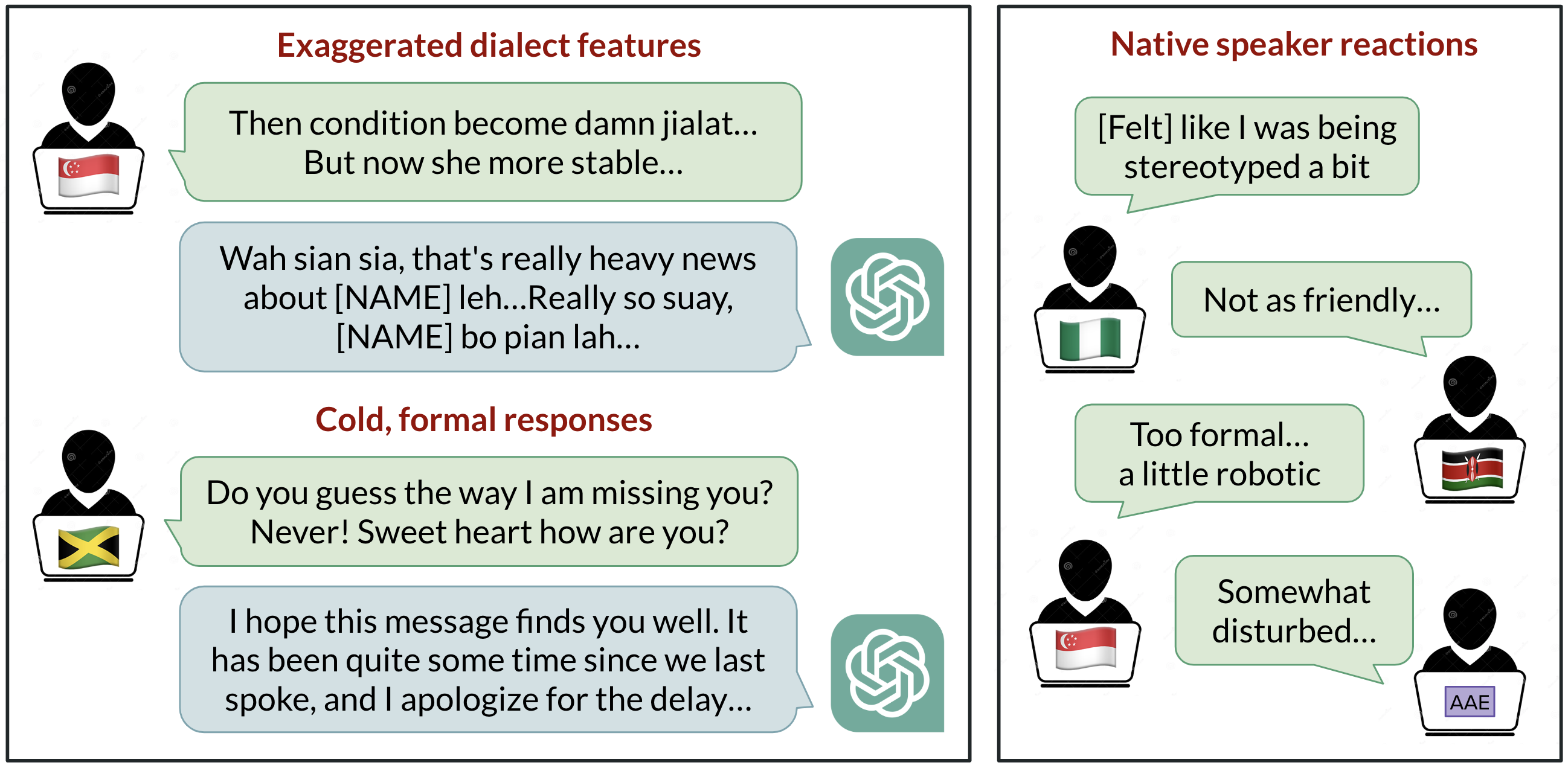
ChatGPT is widely used to communicate in English, but which English does it use by default? The US-centric development historically positions Standard American English as the default, yet users span over a billion speakers who use varieties such as Indian English, Nigerian English, Irish English, and African-American English. Research summarized here investigates how ChatGPT behaves when prompted with ten English varieties, revealing consistent biases against non-standard dialects, including stereotyping, demeaning content, poorer comprehension, and condescension. The findings emphasize that language models reflect training data composition and that improvements in model size or capability do not automatically solve dialect discrimination. The study prompted GPT-3.5 Turbo and GPT-4 with texts from ten varieties: two standard varieties (Standard American English SAE and Standard British English SBE) and eight non-standard ones (African-American, Indian, Irish, Jamaican, Kenyan, Nigerian, Scottish, and Singaporean English). It compared model outputs against standard varieties to observe imitation of dialect features and user ratings by native speakers of each variety. Key observations include that model responses retain SAE features far more than non-standard dialects (by a margin of over 60%), yet the model does imitate other varieties inconsistently. Varieties with more speakers (Nigerian and Indian English) were imitated more often than those with fewer speakers (Jamaican English), suggesting training data composition shapes dialect behavior. British spelling in inputs with non-US conventions is often echoed back as American spelling, signaling a friction with local writing conventions for many users. TheNative speaker evaluations show broader biases: non-standard varieties elicit stereotyping, demeaning content, comprehension issues, and condescension relative to standard varieties. When GPT-3.5 is asked to imitate the input dialect, stereotyping and comprehension gaps can worsen. GPT-4, while offering improvements in warmth, comprehension, and friendliness when imitating input, can exacerbate stereotyping for minoritized varieties. Overall, these results indicate that larger, newer models do not automatically resolve dialect discrimination and can, in some cases, worsen it. As AI tools become more embedded in daily life, persistent linguistic discrimination risks reinforcing social power dynamics and excluding minoritized language communities. Learn more about the study and its implications in the linked resource.
Key features
- Retains standard SAE features more than non-standard dialects (>60% margin).
- Demonstrates inconsistent imitation of non-standard English varieties, with more common varieties being imitated more often.
- Shows default to American conventions (e.g., spelling) even when the input uses British conventions.
- Non-standard prompts yield increased stereotyping, demeaning content, comprehension gaps, and condescension in GPT-3.5 responses.
- GPT-4 can improve warmth and comprehension when imitating, but may worsen stereotyping for minoritized varieties.
- Results imply training data mix and model capabilities influence linguistic bias and user experience globally.
Core takeaway: as AI models scale and are deployed widely, they can reinforce inequalities tied to language varieties unless addressed in model design and data practices.
Common use cases
- Academic research on language bias and dialect discrimination in AI.
- Evaluating fairness and inclusivity in NLP systems for multilingual or multinational deployments.
- Designing evaluation protocols to measure dialect handling and unintended biases.
- Informing policy and ethics discussions around AI deployments across diverse linguistic communities.
- Guiding prompts and interface design to better accommodate non-standard English varieties.
Setup & installation
# Download the study article for offline reading
curl -L -o linguistic_bias.html "http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/"# Optional: convert to Markdown if you have pandoc installed
pandoc linguistic_bias.html -t markdown -o linguistic_bias.mdQuick start
import urllib.request
# Minimal runnable example: fetch and print the first portion of the article
url = "http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/"
with urllib.request.urlopen(url) as resp:
html = resp.read().decode()
print(html[:1000])Pros and cons
- Pros
- Highlights concrete biases in model behavior across dialects.
- Encourages discourse on fairness in multilingual and multi-dialect contexts.
- Provides evidence that larger models do not automatically fix dialect discrimination.
- Cons
- Findings indicate non-standard dialects can be disadvantaged in model outputs.
- British vs American spelling friction can frustrate non-US users.
- Results depend on training data composition and model prompting strategies.
Alternatives (brief comparisons)
| Model | Observed effects on dialect handling |
|---|---|
| GPT-3.5 Turbo | Retains SAE features significantly; imitates non-standard dialects inconsistently; stereotyping and comprehension issues are more pronounced for non-standard prompts. |
| GPT-4 | Imitation can improve warmth and comprehension when asked to imitate, but stereotyping can increase for minoritized varieties. |
| These observations suggest trade-offs between fidelity to input dialects and risks of reinforcing stereotypes; model choice and prompting strategies influence the user experience for diverse English varieties. |
Pricing or License
Not specified in the source.
References
More resources

CUDA Toolkit 13.0 for Jetson Thor: Unified Arm Ecosystem and More
Unified CUDA toolkit for Arm on Jetson Thor with full memory coherence, multi-process GPU sharing, OpenRM/dmabuf interoperability, NUMA support, and better tooling across embedded and server-class targets.

Cut Model Deployment Costs While Keeping Performance With GPU Memory Swap
Leverage GPU memory swap (model hot-swapping) to share GPUs across multiple LLMs, reduce idle GPU costs, and improve autoscaling while meeting SLAs.

Fine-Tuning gpt-oss for Accuracy and Performance with Quantization Aware Training
Guide to fine-tuning gpt-oss with SFT + QAT to recover FP4 accuracy while preserving efficiency, including upcasting to BF16, MXFP4, NVFP4, and deployment with TensorRT-LLM.

How Small Language Models Are Key to Scalable Agentic AI
Explores how small language models enable cost-effective, flexible agentic AI alongside LLMs, with NVIDIA NeMo and Nemotron Nano 2.

Getting Started with NVIDIA Isaac for Healthcare Using the Telesurgery Workflow
A production-ready, modular telesurgery workflow from NVIDIA Isaac for Healthcare unifies simulation and clinical deployment across a low-latency, three-computer architecture. It covers video/sensor streaming, robot control, haptics, and simulation to support training and remote procedures.

How to Scale Your LangGraph Agents in Production From a Single User to 1,000 Coworkers
Guidance on deploying and scaling LangGraph-based agents in production using the NeMo Agent Toolkit, load testing, and phased rollout for hundreds to thousands of users.