Vec2text: Inverting Text Embeddings and Security Implications
Sources: https://thegradient.pub/text-embedding-inversion, https://thegradient.pub/text-embedding-inversion/, The Gradient
Overview
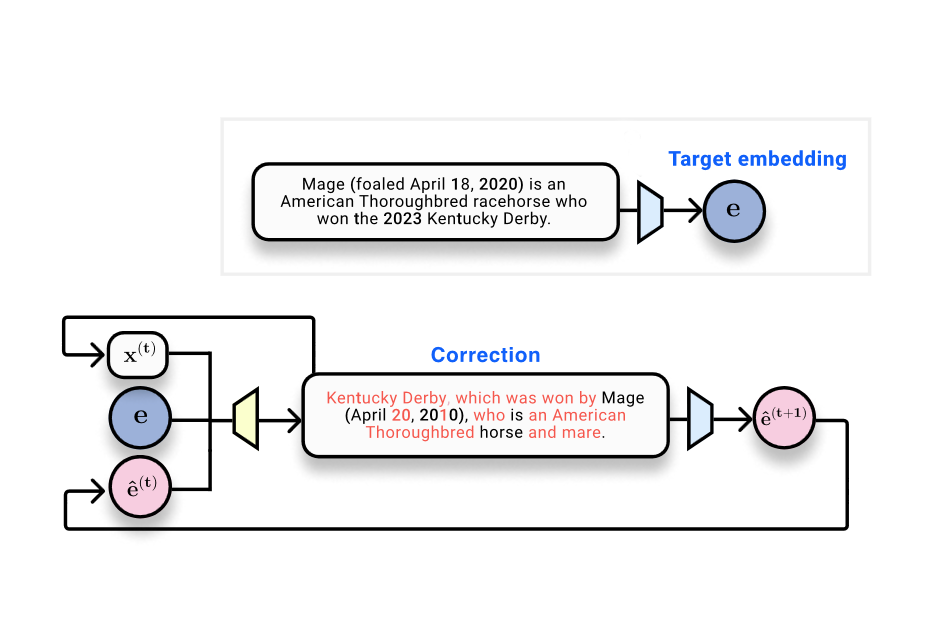
Retrieval Augmented Generation (RAG) systems store and search through documents by using embeddings—vector representations of text produced by embedding models. The Gradient article Do text embeddings perfectly encode text? explores a core question: can input text be recovered from its embeddings? The discussion situates embeddings in the broader context of vector databases and the privacy implications of storing embeddings instead of raw text. The authors reference the paper Text Embeddings Reveal As Much as Text (EMNLP 2023), which directly tackles the inversion problem: can input text be reconstructed from output embeddings? From a technical standpoint, embeddings are the output of neural networks: text is tokenized, processed through nonlinear layers, and ultimately collapsed into a single fixed-size vector. Classic results in the data processing literature tell us that such mappings cannot increase information about the input; they can preserve or discard information. In the vision domain, there are established results showing that image inputs can be recovered from deep representations, which motivates the investigation in text domains as well. A toy scenario in the article considers 32 tokens mapped to 768-dimensional embeddings (32 × 768 = 24,576 bits, about 3 kB). This sets the stage for measurable evaluation: how well can the original text be recovered? The article presents a progression of methods and metrics to answer this question. An initial approach treats inversion as a standard machine learning problem: collect embedding–text pairs and train a model to output text from the embedding. In this setup, a transformer trained to generate text from the embedding achieves a BLEU score around 30/100 and an exact-match rate near zero, illustrating the difficulty of perfect reversal in a single forward pass. A key observation, however, is that when the generated text is re-embedded, the resulting embedding is highly similar to the ground-truth embedding: cosine similarity around 0.97. This confirms that the hypothesis text lies close in embedding space even when the surface text differs. A central idea of the work is to move from a one-shot inversion to a learned optimization process that operates in embedding space. Given a ground-truth embedding (the target), a current hypothesis text, and its embedding, a corrector model is trained to output text that brings the hypothesis closer to the ground truth. This approach is encapsulated in the vec2text method: a learned optimizer that updates text in discrete steps to align with the target embedding. After implementing this approach, the authors report a dramatic improvement: a single forward pass of correction raises BLEU from ~30 to ~50. Importantly, vec2text can be used recursively: starting from a text and its embedding, you can generate hypotheses, re-embed them, and feed them back in for further refinement. With about 50 iterations, the method recovers 92% of 32-token sequences exactly, and achieves a BLEU score of about 97. In other words, for this constrained setting, the text embedding vector contains enough information to nearly reconstruct the original surface text, not just its semantic gist. The takeaway is clear: embeddings can be inverted with high fidelity in practice, which raises important questions about security and privacy in embedding-based storage and communication systems. The article also notes a few caveats. First, the embedding vector has a fixed capacity, so there are theoretical limits to how much information can be stored or recovered. Second, the authors discuss the possibility that an embedding function could be lossy (mapping multiple inputs to the same embedding), which would undermine identifiability; in their experiments, they did not observe such collisions. Finally, the piece situates this result in a broader context: if text can be nearly perfectly reconstructed from embeddings, then there are nontrivial security and privacy considerations for vector databases and external service providers that handle embeddings. For readers who want the deeper background, the article points to prior work showing image inversion from neural representations and to the EMNLP 2023 paper that motivates the text-side inversion question. See the cited link for a detailed treatment and the experimental specifics: Text Embeddings Reveal As Much as Text.
Key features
- vec2text: a learned optimization approach that takes a ground-truth embedding, a hypothesis text, and the hypothesis’s position in embedding space to predict the true text sequence.
- Embedding-space iteration: the method supports recursive refinement by re-embedding generated text and feeding it back for additional updates.
- Demonstrated performance gains: a single correction step boosts BLEU from ~30 to ~50; with ~50 steps, up to 92% exact recovery on 32-token sequences and BLEU near 97.
- Strong embedding-space closeness: generated text often yields embeddings highly similar to the ground truth (cosine similarity ~0.97), even when surface text differs.
- Security and privacy implications: the ability to invert embeddings raises concerns for embedding-based storage and data-sharing setups.
- Theoretical framing: connects to the data processing inequality and the idea that embeddings are lossy representations that may still carry recoverable information.
- Cross-domain context: parallels with image inversion work in computer vision, where deep representations can be inverted to reconstruct inputs.
Common use cases
- Retrieval Augmented Generation (RAG) workflows that rely on embedding-based search: vectors in a vector database represent documents, and similarity drives retrieval quality. If embeddings can be inverted to recover text, this creates a potential privacy risk for data stored as vectors.
- Embedding leakage scenarios: accidental exposure of embedding vectors or a service provider’s access to embeddings could, in principle, enable reconstruction of protected text content, depending on model capacity and access patterns.
- Security and policy planning for vector databases: organizations may need to reassess data retention, access controls, and risk models in light of potential inversion capabilities.
- Research direction: the vec2text framework demonstrates that inversion is not only possible but can be enhanced through iterative correction, informing future security-aware embedding design.
Setup & installation
Not provided in the source document. See the referenced discussion for the core ideas and results. If you’re evaluating embedding security in your own stack, consider the following high-level actions:
# Not provided in sourceQuick start
- Start from a ground-truth embedding E and an initial hypothesis text H. Compute the embedding of H, compare to E, and apply the vec2text correction model to predict a closer text sequence.
- Re-embed the corrected text, compare embeddings, and repeat the process. This recursive loop is the essence of the vec2text approach and was shown to yield substantial gains in surface fidelity over a single-pass inversion.
- In the described toy setting (32 tokens, 768-d embeddings), initial attempts produce BLEU around 30, while iterative correction can push BLEU toward 97 with enough steps, and achieve exact recovery on a large fraction of sequences.
Pros and cons
- Pros
- High-fidelity inversion: demonstrated near-perfect recovery for a constrained 32-token setting after multiple iterations.
- Conceptually simple iteration: leverages re-embedding and corrections to converge toward the ground-truth text.
- Demonstrates a measurable, analyzable pathway from embedding to text, with clear metrics (BLEU, exact-match, cosine similarity).
- Recursiveness enables progressive refinement and potential practical use in iterative decoding scenarios.
- Cons
- Privacy risk: the ability to invert embeddings highlights potential data leakage in embedding-based storage and sharing.
- Not universal: recovery fidelity is demonstrated for a specific toy setup; real-world texts longer than 32 tokens and diverse vocabularies may present additional challenges.
- Embedding capacity limits: there is a fixed bit budget in an embedding vector, implying fundamental limits to how much information can be stored and reconstructed.
- Occasional ambiguities: while the approach achieved high fidelity, exact matches were not guaranteed in all cases; collisions (mapping multiple inputs to the same embedding) are a theoretical concern but were not observed in these experiments.
Alternatives (brief comparisons)
- Direct inversion with a transformer trained to map embeddings to text: this baseline achieved BLEU ~30 and near-zero exact-match, illustrating the difficulty of direct reversal without iterative refinement.
- Image embedding inversion: in computer vision, early work showed that images can be recovered from deep feature representations, motivating cross-domain concerns about inversion from embeddings. An early example is Dosovitskiy (2016), which demonstrated reconstruction from CNN features.
- Broader view: embedding representations are intentionally lossy, balancing semantic utility with data compression; however, the demonstrated inversion results challenge assumptions about recoverability in some settings.
Pricing or License
Not specified in the source material.
References
More resources

How to Scale Your LangGraph Agents in Production From a Single User to 1,000 Coworkers
Guidance on deploying and scaling LangGraph-based agents in production using the NeMo Agent Toolkit, load testing, and phased rollout for hundreds to thousands of users.

cuPQC 0.4: Accelerated Hash Functions and Merkle Trees for Data Integrity
cuPQC v0.4 expands hash function support and adds Merkle-tree calculations to accelerate data integrity, verification, and privacy-preserving cryptography on GPUs.

MCP for Research: Connecting AI to Research Tools
Explains the Model Context Protocol (MCP) for research discovery and how AI can orchestrate research tools across arXiv, GitHub, and Hugging Face via natural language.

FilBench: Filipino Language Evaluation Suite for LLMs (Tagalog, Filipino, Cebuano)
FilBench is a comprehensive evaluation suite to assess LLM capabilities for Tagalog, Filipino, and Cebuano across cultural knowledge, NLP, reading comprehension, and generation, using a rigorous, historically informed methodology.

AGI Is Not Multimodal: Embodiment-First Intelligence
A concise resource outlining why multimodal, scale-driven approaches are unlikely to yield human-level AGI and why embodied world models are essential.

Shape, Symmetries, and Structure: The Changing Role of Mathematics in ML Research
Explores how mathematics remains central to ML, but its role is evolving from theory-first guarantees to geometry, symmetries, and post-hoc explanations in scale-driven AI.