
The Artificiality of Alignment: Critique of AI Safety, Markets, and Governance
Sources: https://thegradient.pub/the-artificiality-of-alignment, https://thegradient.pub/the-artificiality-of-alignment/, The Gradient
Overview
Credulous coverage of AI existential risk has saturated mainstream discourse, yet the article argues that public debates often muddle speculative future danger with present-day harms. It distinguishes large, “intelligence-approximating” models from actual algorithmic and statistical decision-making systems, and questions whether current AI alignment efforts address concrete, widespread harms. The piece contends that the current trajectory of alignment research may be misaligned with the real stakes, focusing more on sensational forecasts of superintelligence than on building reliable, humane systems that people actually use and pay for. The essay acknowledges the impressive capabilities of modern models (e.g., OpenAI’s ChatGPT, Anthropic’s Claude) and their potential usefulness, while refraining from endorsing claims about sentience or the necessity of relying on them for consequential tasks. The central concern is not mere capability but how those capabilities intersect with incentives, governance, and risk management in the real world. The article notes that safety-focused communities worry about rapid, unpredictable shifts toward overtly autonomous behavior, sometimes framed as a looming “ꜰᴏᴏᴍ” in the discourse. The piece situates alignment within a broader landscape of actors—private firms, researchers, and the Effective Altruism (EA) movement—each with distinct incentives and public-facing narratives. A key claim is that the most influential alignment work today occurs within a handful of companies that dominate the most capable models, and that revenue and platform dynamics inevitably shape governance, product design, and technical decisions. OpenAI and Anthropic are highlighted as examples of organizations pursuing both research advancement and market share, with alignment framed as a technical problem by some (e.g., Nick Bostrom) yet embedded in financial and strategic constraints in practice. The article cautions that relying on market incentives alone may complicate, if not undermine, the mission of creating aligned systems that avoid catastrophe. The discussion then turns to the technical core of current alignment approaches: intent alignment, preference modeling, and reinforcement learning guided by human feedback. These ideas are traced to a body of work from researchers who view alignment as shaping model behavior to reflect human preferences, typically summarized as “helpfulness, harmlessness, and honesty” (HHH). The piece emphasizes that the practical realization of intent alignment rests on constructing a dependable preference model and using it to critique and improve a base model. These ideas underpin widely used techniques like RLHF and its successor, RLAIF (also known as Constitutional AI). From this vantage point, the essay argues that alignment is both a technical and socio-economic problem: even a technically sound alignment method must operate within corporate incentives and public policy contexts that determine how models are developed, sold, and deployed. The piece invites readers to examine whether current alignment strategies—however technically sophisticated—are the right tools for preventing real-world harms, or whether they are primarily shaped by market demands and customer expectations.
Key features
- Distinction between speculative AI x-risk discourse and present-day harms; emphasis on real-world impacts over sensational futures.
- Observation that modern alignment work has grown out of corporate-led model development with revenue-driven incentives influencing governance and design.
- The emphasis on technical alignment work as a pathway, but with acknowledged limitations given market and product pressures.
- The central role of intent alignment as a framing device for what it means to align AI with human aims.
- RLHF and RLAIF (Constitutional AI) as the main practical techniques to induce alignment via learned human or AI feedback.
- The concept of a “preference model” that captures human preferences and is used to steer outputs toward HH H values.
- The HH H (helpfulness, harmlessness, honesty) framing used to guide model outputs and evaluation.
- A realistic, critical stance toward public communications from leading labs and the balance between research goals and monetization.
- Acknowledgment of a dense practitioner community (LessWrong, AI Alignment Forum) that underpins the terminology and approaches in alignment research.
Common use cases
- Assessing how corporate incentives shape AI safety and alignment research agendas.
- Analyzing the gaps between theoretical alignment goals and practical product deployment.
- Evaluating RLHF/RLAIF pipelines and their reliance on preference models to steer behavior.
- Comparing public communications and product narratives from leading labs (e.g., OpenAI, Anthropic) versus smaller vendors.
- Framing policy and governance discussions around the interplay of business models, risk, and technical alignment.
Setup & installation
To access the article for offline reading or curation, fetch it from its URL:
curl -L -o artificiality_of_alignment.html https://thegradient.pub/the-artificiality-of-alignment/If you wish to open it locally (on macOS):
open artificiality_of_alignment.htmlYou can also programmatically extract the main sections with a simple HTML parser in your preferred language; this primer uses the URL above as the data source.
Quick start
A minimal runnable example to fetch and print a short summary of the article:
import requests
url = "https://thegradient.pub/the-artificiality-of-alignment/"
text = requests.get(url).text
print(text[:1000]) # first 1000 charactersThis tiny snippet demonstrates how you might programmatically begin a local analysis of the article for a knowledge base or indexer.
Pros and cons
- Pros
- Provides a sober critique of x-risk rhetoric and clarifies the distinction between speculative futures and present harms.
- Connects alignment to real-world product and governance constraints, highlighting how incentives can influence outcomes.
- Describes concrete technical methods (RLHF, RLAIF) and a clear notion of intent alignment and HH H values.
- Encourages a broader contemplation of what constitutes useful and responsible AI development beyond sensational headlines.
- Cons
- The critique assumes alignment aims rooted in public-benefit narratives while acknowledging commercial imperatives; it may understate the social value of productive research and productization.
- The argument rests on the claim that current alignment work is “under-equipped” for present harms, which is a normative assessment rather than an empirical audit.
- The reliance on specific corporate case studies (OpenAI, Anthropic) may not capture the full spectrum of alignment activity worldwide.
Alternatives
The article contrasts leading labs’ public alignment narratives with those of other model vendors. For comparison: | Actor | Alignment posture (as described) | Implication |---|---|---| | OpenAI / Anthropic | High public emphasis on alignment and safety, with product-centric aims | Alignment work is closely tied to market strategy and monetization—potentially shaping safety goals indirectly |Mosaic / Hugging Face | Mentioned as vendors not emphasized for public alignment narratives | Might push a different balance between research, openness, and commercial incentives | These contrasts illustrate how different business and communication strategies intersect with technical alignment work.
Pricing or License
Not explicitly provided in the article’s excerpt. Licensing or usage terms are not discussed here.
References
More resources

How to Scale Your LangGraph Agents in Production From a Single User to 1,000 Coworkers
Guidance on deploying and scaling LangGraph-based agents in production using the NeMo Agent Toolkit, load testing, and phased rollout for hundreds to thousands of users.

MCP for Research: Connecting AI to Research Tools
Explains the Model Context Protocol (MCP) for research discovery and how AI can orchestrate research tools across arXiv, GitHub, and Hugging Face via natural language.

FilBench: Filipino Language Evaluation Suite for LLMs (Tagalog, Filipino, Cebuano)
FilBench is a comprehensive evaluation suite to assess LLM capabilities for Tagalog, Filipino, and Cebuano across cultural knowledge, NLP, reading comprehension, and generation, using a rigorous, historically informed methodology.

AGI Is Not Multimodal: Embodiment-First Intelligence
A concise resource outlining why multimodal, scale-driven approaches are unlikely to yield human-level AGI and why embodied world models are essential.

Shape, Symmetries, and Structure: The Changing Role of Mathematics in ML Research
Explores how mathematics remains central to ML, but its role is evolving from theory-first guarantees to geometry, symmetries, and post-hoc explanations in scale-driven AI.
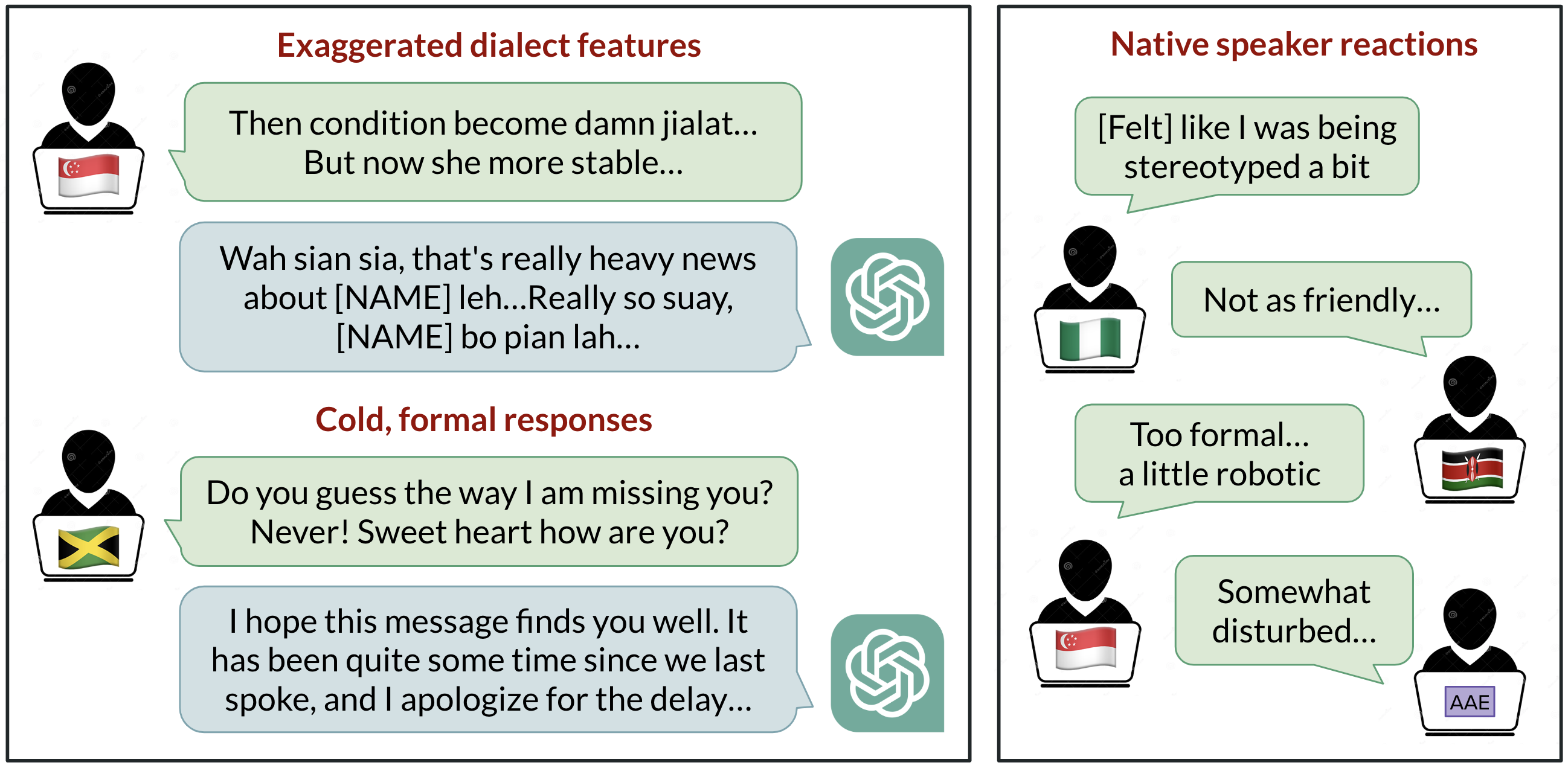
Linguistic Bias in ChatGPT: Dialect Discrimination Across English Varieties
Analysis of how ChatGPT responds to different English dialects, highlighting biases against non-standard varieties and implications for global users.