Agende cargas de trabalho sensíveis à topologia com o SageMaker HyperPod
Sources: https://aws.amazon.com/blogs/machine-learning/schedule-topology-aware-workloads-using-amazon-sagemaker-hyperpod-task-governance, https://aws.amazon.com/blogs/machine-learning/schedule-topology-aware-workloads-using-amazon-sagemaker-hyperpod-task-governance/, AWS ML Blog
TL;DR
- A AWS anunciou o agendamento sensível à topologia como uma nova capacidade do SageMaker HyperPod Task Governance para otimizar a eficiência de treino e a latência de rede em clusters Amazon EKS.
- A abordagem utiliza informações de topologia EC2 para posicionar tarefas de treino que se comunicam entre si dentro do mesmo nó de rede e camadas, reduzindo saltos de rede e latência.
- Existem dois métodos principais de envio de workloads com sensibilidade à topologia: anotação de topologia em manifestos do Kubernetes e uso do SageMaker HyperPod CLI com flags relacionados à topologia.
- O fluxo de trabalho envolve confirmar as informações de topologia, identificar nós que compartilham camadas de rede e enviar tarefas de treino sensíveis à topologia para alcançar maior visibilidade e controle sobre a colocação.
- O post oferece passos práticos, um exemplo de visão geral da topologia e convida usuários a deixarem feedback.
Contexto e antecedentes
Workloads de IA gerativa costumam exigir comunicação extensa entre nós no EC2. Nesse ambiente, a latência de rede é influenciada pela forma como as instâncias estão fisicamente e logicamente organizadas na topologia hierárquica de um data center. A AWS descreve data centers como compostos por unidades organizacionais aninhadas, como nós de rede e conjuntos de nós, com várias instâncias por nó e vários nós por conjunto. Instâncias que compartilham nós de rede mais próximos tendem a ter tempos de processamento mais rápidos devido a menos saltos de rede. Para otimizar a colocação de workloads de IA no cluster SageMaker HyperPod, é possível incorporar informações de topologia EC2 na submissão de jobs. A topologia de uma instância EC2 é descrita por um conjunto de nós, com um nó em cada camada da rede. A topologia é organizada em camadas, e a disponibilidade de compartilhamento de camadas informa sobre proximidade e eficiência de comunicação. Rótulos de topologia de rede permitem agendamento sensível à topologia para melhorar a eficiência das tarefas e a utilização de recursos. Nesse contexto, o SageMaker HyperPod Task Governance expande as capacidades de governança para alocação de recursos acelerados e políticas de prioridade entre equipes e projetos em clusters EKS. Essa governança ajuda administradores a alinhar a alocação de recursos com prioridades organizacionais, possibilitando acelerar a inovação em IA e reduzir o tempo de comercialização ao minimizar a coordenação de provisão de recursos e a replanejamento de tarefas. Para leitores que desejam orientação adicional, a AWS aponta melhores práticas para o SageMaker HyperPod.
O que há de novo
Este post introduz o agendamento sensível à topologia como uma capacidade do SageMaker HyperPod Task Governance, com o objetivo de otimizar eficiência de treino e throughput/latência de rede ao considerar a disposição física e lógica dos recursos no cluster. Pontos-chave:
- O agendamento sensível à topologia utiliza informações de topologia EC2 para informar a colocação de trabalhos, com instâncias nas mesmas camadas de rede compartilhando conectividade mais rápida.
- Administradores podem governar a alocação acelerada de recursos e aplicar políticas de prioridade de tarefas para melhorar a utilização de recursos.
- Cientistas de dados interagem com os clusters SageMaker HyperPod para garantir que haja capacidade e permissões ao trabalhar com recursos de GPU.
- A abordagem oferece flexibilidade com duas vias de submissão e um fluxo de trabalho alternativo.
Dois métodos de submissão (mais um fluxo alternativo)
- Anotação em manifestos do Kubernetes: adicione a anotação de topologia kueue.x-k8s.io/podset-required-topology ao seu Pod ou manifest de Job para agendar pods que compartilham a mesma camada 3 de rede. Para verificar a alocação dos pods, use:
- kubectl get pods -n hyperpod-ns-team-a -o wide
- CLI do SageMaker HyperPod: submeta trabalhos por meio da CLI do HyperPod usando —preferred-topology ou —required-topology ao criar um job. Um exemplo é fornecido para iniciar um treino MNIST sensível à topologia com um placeholder para o ID da conta AWS (XXXXXXXXXXXX). O post também observa considerações práticas para ambientes onde novos recursos foram implantados e aponta para a seção de Limpeza no workshop SageMaker HyperPod EKS para evitar cobranças indesejadas. Também enfatiza que o treinamento de grandes modelos de linguagem (LLMs) envolve comunicação entre pods, e a topologia sensível pode melhorar throughput e latência.
Como começar
Para começar, você deve:
- Confirmar informações de topologia de todos os nós no seu cluster.
- Executar um script para identificar quais instâncias compartilham nós de topo de rede entre as camadas 1–3.
- Agendar tarefas de treino sensíveis à topologia no seu cluster usando qualquer um dos métodos de submissão. Este fluxo de trabalho visa oferecer maior visibilidade e controle sobre a colocação de instâncias de treino, o que pode traduzir-se em desempenho mais previsível para workloads distribuídas de IA. O artigo observa que rótulos de topologia de rede ajudam a alcançar esses benefícios e aponta para visualizações (via Mermaid.js.org) para auxiliar o entendimento da topologia.
Por que isso importa (impacto para desenvolvedores/empresas)
O agendamento sensível à topologia resolve um fator crítico de desempenho para treinamento distribuído de IA: a comunicação entre nós. Em cargas de treino distribuído e especialmente em treinamentos de grandes modelos, reduzir saltos de rede entre GPUs em diferentes nós pode reduzir o tempo de treino e a latência de sincronização. Ao incorporar informações de topologia EC2 no SageMaker HyperPod Task Governance, organizações podem:
- Melhorar a utilização de recursos alinhando a colocação de computação com a proximidade de rede.
- Simplificar a governança de alocação de recursos acelerados entre equipes e projetos.
- Acelerar o time-to-market de inovações em IA ao reduzir a coordenação necessária para provisionar recursos e replanejar tarefas.
- Fornecer aos cientistas de dados maior visibilidade sobre onde suas tarefas irão rodar, permitindo melhor experimentação e otimização. Essas capacidades são particularmente valiosas para equipes que implementam treinamento distribuído de IA, como modelos em larga escala, onde a comunicação entre pods é frequente. A governança busca equilibrar desempenho (topologia de colocação) com controle administrativo (políticas de prioridade e governança de recursos).
Detalhes técnicos ou Implementação
Pré-requisitos e configuração:
- Comece mostrando rótulos de topologia de nós no seu cluster. Um rótulo comum é topology.k8s.aws/network-node-layer-3; um exemplo de saída pode mostrar topology.k8s.aws/network-node-layer-3: nn-33333example, revelando como as instâncias estão organizadas por camadas.
- Use um script para identificar quais nós compartilham camadas 1, 2 e 3 da rede. A saída pode ser usada para criar uma visualização de topologia (por exemplo, em Mermaid.js.org).
- O AWS descreve duas vias práticas de envio de cargas de trabalho sensíveis à topologia:
- Anotação em manifestos do Kubernetes: adicione a anotação kueue.x-k8s.io/podset-required-topology para agendar pods que compartilham a mesma camada 3 de rede.
- CLI do SageMaker HyperPod: use a CLI com —preferred-topology ou —required-topology ao criar um job. Essa abordagem permite agendamento baseado em topologia dentro do SageMaker HyperPod governance.
- Verificando a alocação: depois de lançar os pods, verifique a atribuição de nós com o comando kubectl get pods -n hyperpod-ns-team-a -o wide.
- O artigo fornece um comando de exemplo para iniciar um treino MNIST sensível à topologia via CLI HyperPod, substituindo XXXXXXXXXXXX pelo ID da sua conta AWS. O objetivo é ilustrar o fluxo da CLI, embora o comando exato não esteja reproduzido aqui. Observações práticas:
- Se você implantou novos recursos ao adotar o agendamento sensível à topologia, siga as orientações de Limpeza no workshop SageMaker HyperPod EKS para evitar cobranças não desejadas.
- O foco é especialmente relevante para treinamentos de grandes modelos de linguagem (LLMs), onde a troca de dados entre pods é frequente.
- A AWS ressalta que o agendamento sensível à topologia pode facilitar maior visibilidade e controle sobre a colocação de treinos, traduzindo-se em maior previsibilidade de desempenho para workloads de IA distribuída.
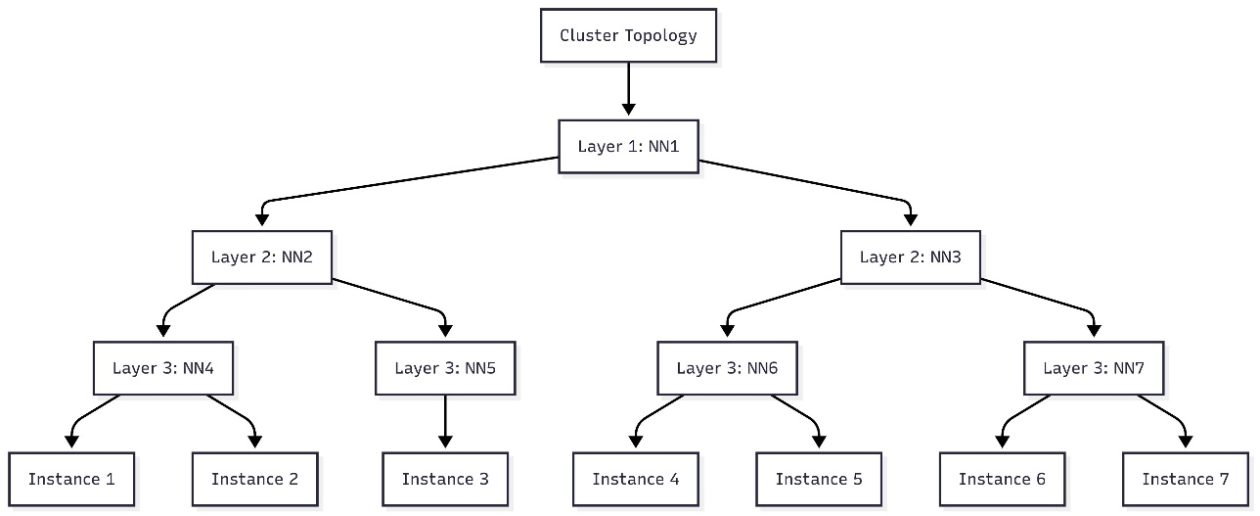
Exemplo prático e visualização
O fluxo de trabalho inclui a geração de um diagrama de topo que mostra como os nós se relacionam entre as camadas 1–3. Você pode visualizar essa topologia em ferramentas como Mermaid.js.org para planejar a colocação de pods antes de enviar tarefas sensíveis à topologia. O cluster de exemplo discutido no artigo ilustra como sete instâncias mapeiam a topologia hierárquica e orienta decisões sobre camadas de rede compartilhadas.
Considerações ao implementar
- Decida entre a abordagem baseada em manifestos ou a abordagem CLI, conforme seu fluxo de trabalho e automação.
- Garanta que sua equipe tenha permissões para interagir com o cluster SageMaker HyperPod e para anotar recursos do Kubernetes.
- Planeje monitorar a colocação por topologia e métricas de desempenho para validar ganhos de throughput e latência.
Principais conclusões
- O SageMaker HyperPod Task Governance agora suporta agendamento sensível à topologia para melhorar eficiência de treinamento e latência de rede.
- Você pode implementar esse agendamento via anotações em manifestos do Kubernetes ou via CLI do HyperPod, oferecendo flexibilidade para diferentes equipes.
- O uso de informações de topologia EC2 informa a colocação de pods em camadas de rede, reduzindo custos de comunicação entre nós.
- O fluxo de trabalho fornece maior visibilidade e controle sobre a colocação de instâncias de treino, o que pode trazer desempenho mais previsível para workloads distribuídas de IA.
- A estratégia é particularmente benéfica para treinamentos distribuídos de IA, como modelos de grande escala, onde a comunicação entre pods é frequente.
FAQ
-
O que é SageMaker HyperPod Task Governance com agendamento sensível à topologia?
É uma capacidade que otimiza eficiência de treino e latência de rede ao agendar cargas de trabalho levando em conta a topologia subjacente do EC2 dentro do SageMaker HyperPod Governance.
-
Como posso submeter tarefas sensíveis à topologia?
Você pode: (1) anotar manifestos do Kubernetes com a anotação de topologia (kueue.x-k8s.io/podset-required-topology) ou (2) usar a CLI do SageMaker HyperPod com --preferred-topology ou --required-topology ao criar um job.
-
uais são os pré-requisitos?
Verificar informações de topologia de todos os nós, rodar um script para identificar nós que compartilham camadas de rede e validar a alocação de pods com comandos kubectl. Consulte o exemplo de cenário de topologia MNIST fornecido no artigo.
-
Onde obter mais informações?
Consulte o post da AWS e explore as referências de visualização em Mermaid.js.org e a anotação de topologia do Kubernetes (kueue.x-k8s.io/podset-required-topology) para obter detalhes de implementação.
Referências
More news

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.

Prompting para precisão com Stability AI Image Services no Amazon Bedrock
O Bedrock now oferece Stability AI Image Services com nove ferramentas para criar e editar imagens com maior precisão. Veja técnicas de prompting para uso empresarial.

Aumente a produção visual com Stability AI Image Services no Amazon Bedrock
Stability AI Image Services já estão disponíveis no Amazon Bedrock, oferecendo capacidades de edição de mídia prontas para uso via Bedrock API, ampliando os modelos Stable Diffusion 3.5 e Stable Image Core/Ultra já existentes no Bedrock.

Use AWS Deep Learning Containers com o SageMaker AI gerenciado MLflow
Explore como os AWS Deep Learning Containers (DLCs) se integram ao SageMaker AI gerenciado pelo MLflow para equilibrar controle de infraestrutura e governança robusta de ML. Um fluxo de trabalho de predição de idade de ostra com TensorFlow demonstra rastreamento de ponta a ponta, governança de model

Construir Fluxos de Trabalho Agenticos com GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore
Visão geral de ponta a ponta para implantar modelos GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore, alimentando um analisador de ações com múltiplos agentes usando LangGraph, incluindo quantização MXFP4 de 4 bits e orquestração serverless.