Análise de bancos de dados baseada em linguagem natural com Amazon Nova
Sources: https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova, https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova/, AWS ML Blog
TL;DR
- A análise de bancos de dados por linguagem natural é viabilizada pelos modelos de base Amazon Nova (Nova Pro, Nova Lite, Nova Micro) e pelo padrão ReAct implementado via LangGraph, permitindo interações no estilo de conversa com sistemas de banco de dados complexos.
- A solução gira em torno de três componentes essenciais—UI, IA gerativa e dados—e usa um agente para coordenar perguntas, raciocínio, orquestração de fluxos e respostas em linguagem natural com autorrecuperação.
- Ela oferece autocorreção e fluxos de HITL (human-in-the-loop) para validar e refinar consultas SQL, assegurando que os resultados correspondam à intenção do usuário e aos requisitos do esquema.
- Avaliações no dataset Spider de text-to-SQL mostram desempenho competitivo e baixa latência em tarefas de tradução cross-domain, com destaque para as perguntas mais complexas. Para implantações de produção, são observadas considerações de segurança para o Streamlit na demonstração.
- A colaboração com o GenAIIC oferece acesso a especialistas para identificar casos de uso valiosos e adaptar soluções práticas de IA generativa; a arquitetura usa o Amazon Bedrock para permitir NL==SQL e visualizações de dados.
Contexto e antecedentes
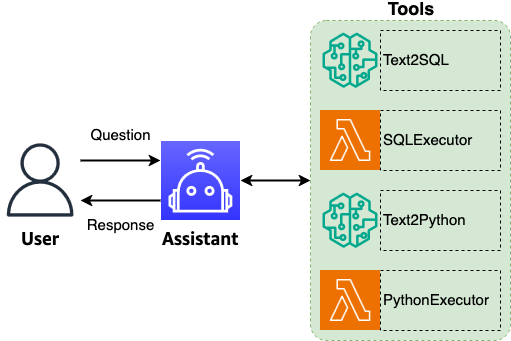
Interfaces de linguagem natural para bancos de dados são um objetivo antigo na gestão de dados. A abordagem here utiliza modelos de linguagem grandes (LLMs) com agentes para decompor consultas complexas em etapas de raciocínio explícitas e permitir a autorrecuperação por meio de ciclos de validação. Ao detectar erros, analisar falhas e refinar consultas, o sistema se aproxima de corresponder à intenção do usuário e aos requisitos do esquema com precisão e confiabilidade. Isso permite interações intuitivas, no estilo de conversa, com sistemas de banco de dados sofisticados, mantendo a exatidão analítica. Para alcançar desempenho otimizado com compromissos mínimos, a solução usa a família de modelos de base Amazon Nova (Nova Pro, Nova Lite e Nova Micro). Esses FMs codificam vastas quantidades de conhecimento mundial, permitindo raciocínio sutil e compreensão contextual para análises complexas de dados. O padrão ReAct (raciocínio e ação) é implementado através da arquitetura flexível do LangGraph, combinando as forças do Nova com etapas de raciocínio explícitas e ações. O resultado é uma abordagem moderna para análises de banco de dados em linguagem natural que suporta análise automatizada e consultas NL-to-SQL em conjuntos de dados. Muitos clientes em transformação de IA generativa reconhecem que seus grandes repositórios de dados contêm potencial não explorado para análises automatizadas. Isso os leva a explorar soluções SQL de consulta para extrair dados, desde cláusulas simples SELECT até consultas multipagina com agregações e funções sofisticadas. O desafio central é transformar a intenção do usuário — expressa ou implícita — em consultas SQL performáticas, precisas e válidas que retornem o conjunto de dados correto para visualização e exploração subsequentes. Nossa solução se destaca por gerar consultas com contexto e metadados que obtêm conjuntos de dados precisos e realizam análises complexas. Ampliar a usabilidade com uma interface amigável é crucial; desenvolvemos uma interface intuitiva em que o usuário é guiado ao longo da jornada de análise com capacidades de HITL, permitindo entradas, aprovações e modificações em pontos decisivos. A arquitetura facilita uma análise integrada e de longo prazo, não apenas uma única consulta.
O que há de novo
A arquitetura apresentada traz três componentes centrais—UI, IA gerativa e dados—com um agente central que coordena perguntas, roteamento e saídas. O agente realiza compreensão de questões, tomada de decisões, orquestração de fluxos e geração de respostas em linguagem natural, aprimora a qualidade do texto, padroniza a terminologia e mantém o contexto de conversa para permitir uma sequência de consultas relacionadas com uma intenção analítica precisa. As capacidades-chave incluem roteamento inteligente para invocar as ferramentas corretas para cada pergunta, permitindo o processamento end-to-end de consultas. O fluxo também processa dados tabulares e visuais, gerando resumos abrangentes que explicam descobertas, destacam percepções-chave e sugerem perguntas de acompanhamento relevantes. Um benefício adicional é a habilidade do agente de propor perguntas de acompanhamento para aprofundar a exploração de dados e revelar insights inesperados. O agente mantém o contexto entre as conversas, reconstruindo perguntas abreviadas a partir do contexto anterior para confirmação e sugerindo perguntas adicionais após cada troca. A padronização de terminologia é aplicada para manter consistência com padrões da indústria, diretrizes de clientes e requisitos de marca, expandindo abreviações para formas completas para melhorar clareza tanto nas entradas quanto nas saídas. A solução também inclui autocorreção: se ocorrer erro de execução, o agente usa o erro e o contexto completo para regenerar uma consulta SQL corrigida. Essa abordagem aumenta a robustez do processamento de consultas. A saída do agente inclui um sumário em linguagem natural, resultados tabulares com raciocínio, visualizações com explicações e um resumo conciso de insights. A demonstração utiliza o Streamlit apenas para ilustração; implantações de produção devem considerar configurações de segurança apropriadas. O GenAIIC (Centro de Inovação em IA Generativa) oferece suporte adicional com especialistas para identificar casos de uso e soluções sob medida. Os modelos Nova, aliados ao Bedrock, permitem transformar consultas em linguagem natural em SQL com suporte a visualizações, com resultados de avaliação que indicam desempenho competitivo e potencial para democratizar o acesso a dados por meio de interfaces naturais.
Detalhes técnicos ou Implementação
Arquitetura e componentes centrais
A arquitetura envolve três componentes centrais: UI, IA gerativa e dados. Um agente atua como coordenador central, realizando compreensão de perguntas, tomada de decisões, orquestração de fluxos, roteamento inteligente e geração de respostas em linguagem natural. O agente aprimora a qualidade do texto, padroniza a terminologia e mantém o contexto para suportar uma cadeia de consultas relacionadas com intencionalidade analítica precisa. O roteamento inteligente assegura que as ferramentas corretas sejam chamadas para cada pergunta, possibilitando o processamento end-to-end. O fluxo também processa dados tabulares e visuais e utiliza o contexto completo para gerar resumos e percepções.
O agente e capacidades de autocorreção
Um recurso-chave é a capacidade de autocorreção do agente. Quando ocorre um erro de execução, o agente utiliza o erro e o contexto para regenerar uma consulta SQL corrigida. Essa abordagem robusta sustenta o processamento confiável de consultas, mesmo em cenárioscomplexos. O agente processa entradas — a pergunta reescrita, os resultados da análise e o contexto — para produzir um sumário em linguagem natural e uma resposta que inclua resultados tabulares com raciocínio, explicações de visualizações e um resumo de insights. O agente mantém o contexto entre conversas, reconstruindo perguntas abreviadas para confirmação e sugerindo perguntas de acompanhamento após cada interação.
Processamento de dados, visualização e padronização de linguagem
A solução suporta o processamento de dados tabulares e visuais e a geração de saídas que explicam descobertas e destacam insights. A terminologia é padronizada para alinhar-se a padrões da indústria, diretrizes do cliente e requisitos de marca, com a expansão de abreviações para formas completas para maior clareza.
Avaliação e considerações de produção
A solução foi avaliada no Spider dataset de text-to-SQL, um conjunto de referência amplamente utilizado para parsing semântico cross-domain. O Spider compreende 10.181 questões e 5.693 consultas SQL únicas em 200 bancos de dados com 138 domínios. A avaliação foi realizada em configuração zero-shot (sem ajuste fino com exemplos do conjunto) para medir a generalização da tradução NL-to-SQL. As métricas destacaram desempenho competitivo e baixa latência, especialmente para consultas complexas. A avaliação ajuda a comparar o Nova com abordagens de ponta e demonstra o potencial de apoiar consultas em linguagem natural em escala.
Demonstração e considerações de produção
A interface Streamlit é usada para fins ilustrativos na demonstração. Para implantações de produção, configurações de segurança e arquitetura de implantação devem ser revisadas para assegurar alinhamento com os requisitos e melhores práticas da organização. O GenAIIC oferece acesso a especialistas para ajudar a identificar casos de uso valiosos e adaptar soluções de IA generativa às necessidades específicas.
Pré-requisitos e etapas de implantação (visão geral)
- Use notebooks SageMaker para experimentar a solução.
- Faça o download e prepare o banco de dados utilizado para consultas.
- Inicie a aplicação Streamlit com o comando: streamlit run app.py. A demonstração ilustra a interface e o fluxo; em produção, considere segurança e escalabilidade.
Tabela de fatos-chave
| Componente | Descrição |
|---|---|
| Modelos centrais | Amazon Nova Pro, Nova Lite, Nova Micro |
| Padrão | ReAct (raciocínio e ação) via LangGraph |
| Plataforma | Amazon Bedrock |
| Conjunto de avaliação | Spider Text-to-SQL (zero-shot) |
| Domínios de dados | 138 em 200 bancos de dados |
Por que isso importa (impacto para desenvolvedores/empresas)
- Permite consultas naturais de ponta a ponta sobre dados estruturados com geração de SQL precisa, reduzindo a barreira de acesso a dados para analistas e tomadores de decisão.
- Usa etapas de raciocínio explícitas e ações para aumentar a transparência do processo analítico e a rastreabilidade.
- Suporta autocorreção e fluxos HITL para melhorar robustez e confiabilidade em implantações reais.
- Oferece uma abordagem escalável para tradução de consultas cross-domain com baixa latência, mesmo para consultas complexas.
- Oferece orientação especializada através do GenAIIC para identificar casos de uso impactantes e adaptar soluções às necessidades da organização.
Principais conclusões
- Amazon Nova, guiado pelo padrão ReAct e pelo LangGraph, permite transformação NL em SQL com raciocínio explícito.
- Um agente central coordena perguntas, roteamento e saídas, mantendo contexto entre diálogos.
- Autocorreção e HITL aumentam a robustez diante de erros de execução e refinam resultados.
- A avaliação Spider mostra desempenho competitivo em tarefas de tradução NL-to-SQL com baixa latência.
- A demonstração com Streamlit é ilustrativa; implantações de produção exigem configurações de segurança adequadas.
FAQ
-
Qual é o papel do Amazon Nova nesta solução?
O Amazon Nova fornece os modelos de base usados para compreensão de linguagem natural e raciocínio, possibilitando a tradução NL-to-SQL dentro do framework ReAct.
-
Como funciona a autocorreção?
Quando ocorre erro de execução, o agente utiliza o erro e o contexto completo para regenerar uma consulta SQL corrigida, aumentando a robustez.
-
ual é o papel do LangGraph?
LangGraph implementa o padrão ReAct, coordenando etapas de raciocínio e ações com os modelos Nova para conduzir o processamento de consultas end-to-end.
-
ual dataset foi utilizado na avaliação e o que ele mostra?
O Spider dataset (10.181 questões, 5.693 SQL únicas, 200 bancos de dados, 138 domínios) foi utilizado em configuração zero-shot para medir generalização, mostrando desempenho competitivo e baixa latência.
-
Onde posso saber mais ou colaborar com o GenAIIC?
O GenAIIC oferece acesso a especialistas para identificar casos de uso e soluções sob medida; informações sobre colaboração estão disponíveis através dos canais do AWS Generative AI Innovation Center mencionados no post.
Referências
- https://aws.amazon.com/blogs/machine-learning/natural-language-based-database-analytics-with-amazon-nova/
- Referências ao Amazon Nova Foundation Models e Amazon Bedrock são mencionadas no artigo como parte do contexto da solução.
More news

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Scaleway Como Novo Fornecedor de Inferência no Hugging Face para Inferência serverless de Baixa Latência
A Scaleway é agora um Fornecedor de Inferência compatível no Hugging Face Hub, permitindo inferência serverless diretamente nas páginas de modelo com as SDKs JS e Python. Acesse modelos abertos populares com operações escaláveis e baixa latência.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.

Prompting para precisão com Stability AI Image Services no Amazon Bedrock
O Bedrock now oferece Stability AI Image Services com nove ferramentas para criar e editar imagens com maior precisão. Veja técnicas de prompting para uso empresarial.

Aumente a produção visual com Stability AI Image Services no Amazon Bedrock
Stability AI Image Services já estão disponíveis no Amazon Bedrock, oferecendo capacidades de edição de mídia prontas para uso via Bedrock API, ampliando os modelos Stable Diffusion 3.5 e Stable Image Core/Ultra já existentes no Bedrock.

Use AWS Deep Learning Containers com o SageMaker AI gerenciado MLflow
Explore como os AWS Deep Learning Containers (DLCs) se integram ao SageMaker AI gerenciado pelo MLflow para equilibrar controle de infraestrutura e governança robusta de ML. Um fluxo de trabalho de predição de idade de ostra com TensorFlow demonstra rastreamento de ponta a ponta, governança de model