Crie um fluxo sem servidor para orquestração de lotes Bedrock com AWS Step Functions
Sources: https://aws.amazon.com/blogs/machine-learning/build-a-serverless-amazon-bedrock-batch-job-orchestration-workflow-using-aws-step-functions, https://aws.amazon.com/blogs/machine-learning/build-a-serverless-amazon-bedrock-batch-job-orchestration-workflow-using-aws-step-functions/, AWS ML Blog
TL;DR
- A inferência em lote do Bedrock oferece uma opção econômica e escalável para volumes elevados, com desconto de 50% em relação ao processamento sob demanda.
- Este artigo apresenta um padrão de orquestração sem servidor usando AWS Step Functions e um stack do AWS CDK para gerenciar pré-processamento, jobs em lote em paralelo e pós-processamento.
- A demonstração utiliza 2,2 milhões de linhas do conjunto SimpleCoT, com fluxos de geração de texto ou embeddings.
- Templates de prompts e formatação de entrada são centralizados em código (prompt_templates.py e prompt_id_to_template), com fontes de entrada configuráveis incluindo datasets do Hugging Face ou arquivos CSV/Parquet no S3.
- A solução é projetada para ser econômica e escalável, com orientações sobre monitoramento, paralelismo e limpeza de recursos.
Contexto e antecedentes
À medida que organizações adotam cada vez mais modelos de base para cargas de trabalho de IA/ML, existem dois padrões amplos de inferência: em tempo real e em lote. A inferência em lote é adequada para processar grandes conjuntos de dados onde resultados imediatos não são necessários, e o Bedrock oferece uma opção com desconto em comparação ao processamento sob demanda. Implementar inferência em lote em grande escala traz desafios como formatação de entradas, gerenciamento de cotas de jobs, orquestração de execuções concorrentes e tratamento de pós-processamento para interpretar as saídas do modelo. A abordagem descrita aqui reúne componentes escaláveis e sem servidor em um fluxo de trabalho de orquestração de lote. O fluxo cobre três fases: pré-processamento dos dados de entrada (por exemplo, formatação de prompts), execução de inferência em lote em paralelo e pós-processamento para analisar os resultados. A solução é projetada para ser flexível e escalável, permitindo fluxos de trabalho como geração de embeddings para grandes coleções de documentos ou execução de tarefas de avaliação ou conclusão personalizadas em grandes conjuntos de dados. A arquitetura é definida em um stack do AWS Cloud Development Kit (CDK) que implanta uma máquina de estado do Step Functions para orquestrar o processo de ponta a ponta. No caso de uso apresentado, o conjunto de 2,2 milhões de linhas do SimpleCoT é utilizado para demonstrar o pipeline. SimpleCoT é um conjunto de exemplos voltados a tarefas, criado para ilustrar o raciocínio em cadeia em modelos de linguagem e abrange várias tipos de problemas. O padrão de orquestração Bedrock em lote emprega componentes escaláveis e sem servidor para cobrir considerações arquiteturais específicas de fluxos de processamento em lote. As seções seguintes descrevem os passos para implantar o stack do AWS CDK e rodar o fluxo no seu ambiente AWS.
O que há de novo
Este post destaca uma arquitetura sem servidor, escalável, para processamento em lote com Bedrock, orquestrada pelo AWS Step Functions. Ele mostra como:
- Pré-processar entradas e formatar prompts via o módulo prompt_templates.py e o mapeamento prompt_id_to_template que liga uma tarefa a um prompt específico.
- Lançar jobs em lote em paralelo e gerenciá-los com uma máquina de estado do Step Functions implantada via CDK.
- Pós-processar saídas para extrair resultados, agregando-os em arquivos Parquet que preservam as colunas da entrada e acrescentam as informações de saída (resposta ou embedding). Um caso concreto utiliza 2,2 milhões de linhas do SimpleCoT. A configuração utiliza um stack do CDK, e o processo pode ser estendido para outros conjuntos de dados ou cargas de FM. O máximo de concorrência é controlado pelo valor maxConcurrentJobs no arquivo cdk.json, oferecendo um parâmetro simples para ajustar throughput e custo. O exemplo também demonstra como identificar as saídas do CloudFormation que revelam os nomes do bucket de dados de entrada e da workflow do Step Functions, facilitando a localização e monitoramento dos recursos. O fluxo aceita entrada na forma de um URI S3 apontando para um conjunto de dados armazenado no S3 em formatos CSV ou Parquet, ou uma referência a um dataset do Hugging Face, dependendo do caso de uso. Quando se utiliza prompts, o mapeamento prompt_id corresponde a um template de prompt que popula o conteúdo com base nas colunas do dataset, como o campo topic. O conjunto de dados precisa possuir uma coluna correspondente para que o prompt seja preenchido corretamente. Para tarefas de embeddings, não é necessário fornecer um prompt_id, mas o CSV de entrada deve possuir uma coluna chamada input_text com o texto a embedding. Conceitos de operação: a execução de inferência em lote sem servidor é monitorada pela máquina de estado; a saída é agregada em Parquet com as mesmas colunas da entrada mais o output do modelo. Em tarefas de geração de texto, a saída fica na coluna response; em embeddings, fica na coluna embedding (uma lista de números de ponto flutuante). O post ressalta que não há SLAs garantidos para a API de Batch Inference, e que os tempos de execução variam conforme a demanda do modelo. Em uma experiência, o processamento de 2,2 milhões de registros em 45 jobs com até 20 jobs simultâneos levou, em média, 9 horas por job, totalizando cerca de 27 horas de processamento de ponta a ponta.
Por que isso importa (impacto para desenvolvedores/empresas)
Para desenvolvedores e organizações, esse padrão facilita a construção de pipelines de inferência por lote que são escaláveis, resilientes e com custo controlado. Benefícios-chave:
- Custos reduzidos para inferência em lote com Bedrock, tornando viável processar milhões de registros para embeddings ou geração textual.
- Uma arquitetura baseada em servidor e orientada a orquestração reduz a complexidade operacional de pipelines de inferência em lote.
- A separação clara entre pré-processamento, computação e pós-processamento simplifica a manutenção e a extensão do fluxo para diferentes modelos e datasets.
- Integração fácil com fontes de dados como S3 ou datasets do Hugging Face, ampliando a reutilização entre projetos.
- Controles explícitos de concorrência e dimensionamento de lotes permitem ajustar desempenho e custo conforme as necessidades da organização. Para equipes que trabalham com rotinas de rotulagem de dados, geração de dados sintéticos ou distilação de modelos, esse padrão oferece um blueprint prático para pipelines de inferência em lote em nuvem.
Detalhes técnicos ou Implementação
Abaixo está uma visão resumida de como implementar o fluxo de orquestração Bedrock em lote com AWS Step Functions, destacando etapas-chave e pontos de configuração.
- Pré-requisitos: Instale os pacotes necessários com o comando npm i.
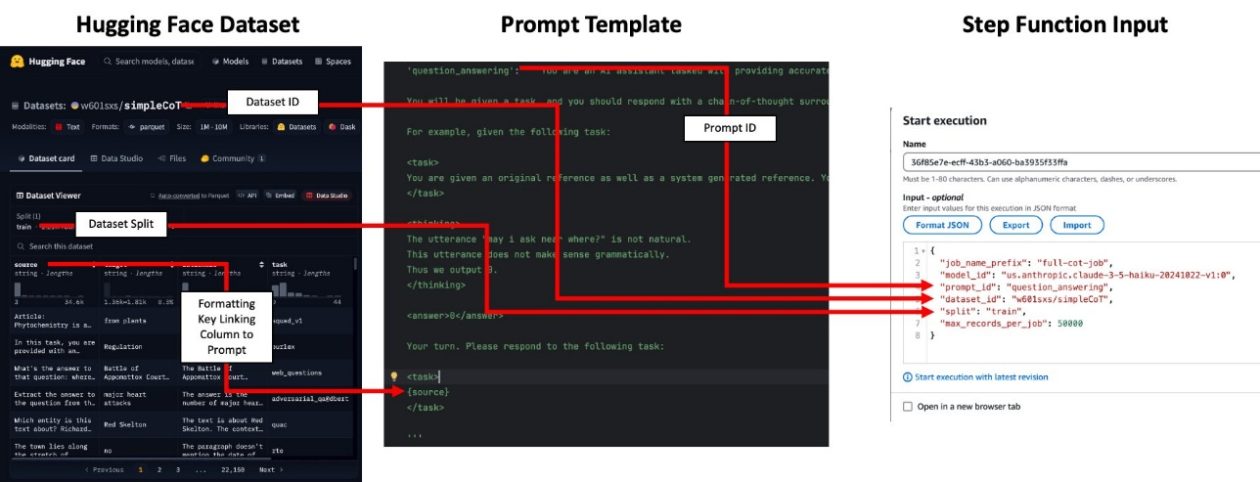
- Prompts e mapeamento: Revise prompt_templates.py e adicione um novo template de prompt ao mapeamento prompt_id_to_template para o seu caso de uso. O mapeamento vincula uma tarefa a um prompt específico. Garanta que as chaves de formatação do template correspondam às colunas do conjunto de dados de entrada, conforme exigido pelos prompts. Observação: prompts não são usados para trabalhos de embeddings.
- Implantação do stack: Implemente o stack do CDK com npm run cdk deploy. Após a implantação, registre as saídas do CloudFormation que indicam os nomes do bucket de dados e do fluxo Step Functions.
- Preparação de dados: Seu input pode ser um Hugging Face dataset ID (por exemplo, w601sxs/simpleCoT) ou um dataset no S3 (CSV ou Parquet). Se usar Hugging Face, referencie o dataset ID e a divisão (por exemplo, train); o dataset será puxado do Hugging Face Hub. As colunas do dataset devem obedecer às chaves de formatação exigidas pelos prompts.
- Mapeamento de prompts e formatação de dados: A coluna usada para o prompting é exposta por meio de uma chave de formatação (por exemplo, topic). O dataset precisa ter uma coluna correspondente para que o prompt seja preenchido corretamente. Para embeddings, não é necessário fornecer prompt_id, mas o CSV de entrada deve conter a coluna input_text com o texto a embedding.
- Ingestão de dados e orquestração: Carregue seu CSV ou Parquet no bucket S3 designado (por exemplo, aws s3 cp topics.csv s3://batch-inference-bucket-/inputs/jokes/topics.csv). Abra o console do Step Functions e envie uma entrada com um s3_uri apontando para o seu conjunto de dados. O prompt_id mapeia para um template de prompt que gera a racionalidade e a resposta para cada linha (ou, para embeddings, opera sobre input_text).
- Observabilidade e monitoramento: O máximo de jobs concorrentes é controlado pela variável maxConcurrentJobs no cdk.json. Os Parquet resultantes contêm as mesmas colunas da entrada mais o output do modelo. Em tarefas de geração de texto, a saída está na coluna response; para embeddings, na coluna embedding (uma lista de números).
- Observação de tempo e custo: não há SLA garantido para o Batch Inference; tempos variam conforme demanda do modelo. Em uma demonstração, a inferência de 2,2 milhões de registros em 45 jobs com até 20 concorrentes levou em média 9 horas por job, totalizando cerca de 27 horas de processamento.
- Limpeza de recursos: para evitar custos contínuos, execute cdk destroy para derrubar os recursos criados pela stack CDK. O stack e a solução associada estão disponíveis em um repositório público no GitHub mencionado no artigo.
- Referências e atribuição: o fluxo e a justificativa são descritos no artigo do blog da AWS, que oferece walkthrough completo e exemplos de configuração. As explicações também incluem um diagrama conceitual da arquitetura da solução que pode ser adaptado para seus dados e modelos.
| Configuração-chave | Descrição |
|---|---|
| maxConcurrentJobs | Controla o número máximo de jobs simultâneos via o contexto do CDK em cdk.json, permitindo ajustar throughput e custo |
| Formatos de entrada | Hugging Face dataset ID ou arquivos CSV/Parquet no S3 |
| Saída | Arquivos Parquet contendo as mesmas colunas da entrada mais o output do modelo; text generation gera a coluna response e embeddings geram a coluna embedding |
Fluxo de trabalho prático
- Passo 1: Pré-processar seus dados para corresponder aos prompts, assegurando que todas as chaves de formatação necessárias estejam presentes.
- Passo 2: Lançar jobs em lote em paralelo com a orquestração do Step Functions, respeitando o limite de concorrência definido.
- Passo 3: Pós-processar as saídas para extrair os resultados, agregando-os em arquivos Parquet com as colunas de entrada e a saída do modelo.
Takeaways chave
- Inferência em lote com Bedrock é escalável e economicamente viável para workloads grandes quando resultados imediatos não são necessários.
- Um padrão de orquestração sem servidor com Step Functions simplifica pipelines de inferência em lote ao separar pré-processamento, computação e pós-processamento.
- O fluxo funciona com dados de fontes diversas (Hugging Face ou S3) e com tarefas de geração de texto ou embeddings, com saídas armazenadas em Parquet para analytics.
- Controles de concorrência e implantação via CDK tornam o pipeline repetível, auditável e ajustável aos recursos disponíveis.
- O artigo oferece um exemplo prático com 2,2 milhões de linhas, servindo como ponto de partida para adaptar o fluxo a outros modelos e datasets.
FAQ
-
Qual problema esta solução resolve?
Fornece uma estrutura robusta, sem servidor, para orquestrar inferência em lote do Bedrock em escala, lidando com pré-processamento, execução paralela e pós-processamento.
-
ue fontes de dados são suportadas para entrada?
Pode-se referenciar um Hugging Face dataset ID (com divisão) ou apontar para um dataset no S3 em formatos CSV ou Parquet.
-
Como é controlada a concorrência?
O máximo de jobs simultâneos é controlado pelo maxConcurrentJobs no arquivo de configuração do CDK (cdk.json).
-
Como limpar recursos após testes?
Execute cdk destroy para derrubar os recursos criados pela stack.
-
uais saídas o fluxo produz?
rquivos Parquet com as colunas de entrada mais a saída do modelo; para geração de texto, há uma coluna response; para embeddings, uma coluna embedding.
Referências
More news

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.

Prompting para precisão com Stability AI Image Services no Amazon Bedrock
O Bedrock now oferece Stability AI Image Services com nove ferramentas para criar e editar imagens com maior precisão. Veja técnicas de prompting para uso empresarial.

Aumente a produção visual com Stability AI Image Services no Amazon Bedrock
Stability AI Image Services já estão disponíveis no Amazon Bedrock, oferecendo capacidades de edição de mídia prontas para uso via Bedrock API, ampliando os modelos Stable Diffusion 3.5 e Stable Image Core/Ultra já existentes no Bedrock.

Use AWS Deep Learning Containers com o SageMaker AI gerenciado MLflow
Explore como os AWS Deep Learning Containers (DLCs) se integram ao SageMaker AI gerenciado pelo MLflow para equilibrar controle de infraestrutura e governança robusta de ML. Um fluxo de trabalho de predição de idade de ostra com TensorFlow demonstra rastreamento de ponta a ponta, governança de model

Construir Fluxos de Trabalho Agenticos com GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore
Visão geral de ponta a ponta para implantar modelos GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore, alimentando um analisador de ações com múltiplos agentes usando LangGraph, incluindo quantização MXFP4 de 4 bits e orquestração serverless.