Conheça o Boti: o assistente de IA que transforma o acesso dos cidadãos de Buenos Aires às informações governamentais com Amazon Bedrock
Sources: https://aws.amazon.com/blogs/machine-learning/meet-boti-the-ai-assistant-transforming-how-the-citizens-of-buenos-aires-access-government-information-with-amazon-bedrock, https://aws.amazon.com/blogs/machine-learning/meet-boti-the-ai-assistant-transforming-how-the-citizens-of-buenos-aires-access-government-information-with-amazon-bedrock/, AWS ML Blog
TL;DR
- A Prefeitura da Cidade de Buenos Aires, em parceria com o AWS GenAIIC, desenvolveu um assistente de IA agentivo usando LangGraph e Amazon Bedrock que responde a perguntas sobre procedimentos governamentais.
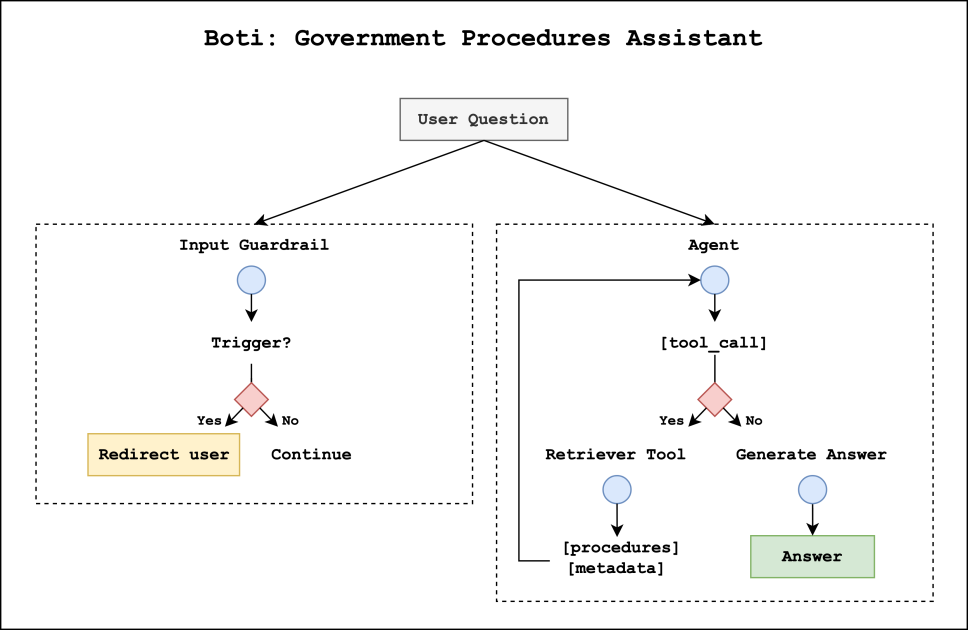
- A solução tem duas camadas: um sistema de guarda de entrada (guardrail) que classifica as consultas do usuário e um agente de procedimentos governamentais que recupera informações e compõe respostas.
- Um fluxo de recuperação com raciocínio utiliza resumos comparativos para desambiguar procedimentos semelhantes, atingindo até 98,9% de exatidão na recuperação top-1 e um ganho de 12,5–17,5% em relação a métodos padrão de RAG.
- Os guardrails bloquearam 100% das queries nocivas na avaliação; especialistas observaram 98% de precisão no uso do voseo e 92% na precisão do tempo verbal futuro periprástico.
- O projeto amplia o alcance do Boti além das mais de 3 milhões de conversas mensais já realizadas pelo WhatsApp, conectando cidadãos a mais de 1.300 procedimentos governamentais.
Contexto e histórico
A Prefeitura da Cidade de Buenos Aires mantém uma trajetória de uso de assistentes de IA para atender os cidadãos. Desde fevereiro de 2019, o Boti funciona via WhatsApp, o canal mais utilizado para informações da cidade na Argentina. Com o Boti, os cidadãos podem acessar informações sobre renovação de carteira de motorista, serviços de saúde, eventos culturais e muito mais. Esse canal tornou-se um meio preferencial de comunicação, realizando mais de 3 milhões de conversas por mês. À medida que o uso do Boti cresce, a cidade busca aprimorar a experiência conversacional com os avanços mais recentes de IA generativa, respondendo perguntas sobre procedimentos governamentais e conectando os usuários aos procedimentos corretos. Para testar uma solução mais avançada, a cidade fez uma parceria com o AWS GenAIIC, que colaborou para construir um sistema de IA agentivo com LangGraph e Amazon Bedrock. A implementação tem como pilares dois componentes primários: um sistema de guarda de entrada (guardrail) e um agente de procedimentos governamentais. O guardrail utiliza um classificador de LLM personalizado para analisar as consultas e decidir aprovar ou bloquear. Consultas aprovadas são tratadas pelo agente de procedimentos governamentais, que recupera informações relevantes e gera respostas no tom característico do Boti. A cidade de Buenos Aires mantém mais de 1.300 procedimentos governamentais, cada um com lógica, nuances e exceções próprias, o que tornou essencial deslocar o foco para desambiguação e recuperação precisa. Para a construção do knowledge base e a inferência, as equipes utilizam o Amazon Bedrock Knowledge Bases e a Bedrock Converse API para executar LLMs. O projeto também prioriza a adequação linguística ao Rioplatense espanhol, enfatizando o voseo e o tempo verbal periprástico.
O que há de novo
O sistema de IA agentivo apresenta dois componentes que trabalham em paralelo no momento da consulta. Primeiro, o guardrail analisa a consulta do usuário para decidir se ela pode ser processada on-topic. Se a consulta for considerada nociva, a execução do grafo é interrompida e o usuário é redirecionado para perguntas sobre procedimentos governamentais de forma segura. Se aprovada, o agente de procedimentos governais assume a tarefa de gerar a resposta. Em segundo lugar, o agente de procedimentos pode acionar uma ferramenta de recuperação para obter contexto e metadados relevantes de procedimentos armazenados nos Bedrock Knowledge Bases, permitindo respostas precisas e atualizadas. A solução utiliza a Bedrock Converse API para inferência de LLM, aproveitando uma ampla seleção de LLMs para otimizar desempenho e latência em diferentes subtarefas. Uma inovação-chave é o fluxo de recuperação por raciocínio, feito para desambiguar procedimentos intimamente relacionados. O processo começa com a criação de um knowledge base de procedimentos governamentais a partir de informações básicas (propósito, público, custos, etapas, requisitos) e de resumos comparativos que descrevem o que distingue cada procedimento de seus vizinhos. Esses resumos são agrupados em clusters pequenos (tamanho médio ≈ 5) e enriquecidos com descrições que apontam as diferenças, geradas por um LLM. O resultado é um resumo final discriminatório anexado às informações básicas. Essa abordagem compartilha semelhanças com a Contextual Retrieval da Anthropic, que antecipa contexto explicativo aos trechos de documento. Com o knowledge base preparado, o Reasoning Retriever opera em três etapas: recebe os procedimentos completos recuperados, executa seu próprio processo de pensamento para identificar o conteúdo relevante e as URLs de atribuição ao gerar a resposta, e utiliza essas informações para compor a resposta final. Em avaliações com um conjunto sintético de 1.908 perguntas provenientes de procedimentos conhecidos, o Reasoning Retriever superou significativamente as técnicas RAG padrão em exatidão de recuperação top-k. Os resultados mostraram que embeddings multilingues da Cohere, combinados com um passo de raciocínio usando Claude/Haiku no Bedrock, apresentaram desempenho particularmente forte entre várias métricas top-k. O ranking de recuperação foi avaliado em um conjunto de referência amplo. Os três primeiros métodos representam abordagens padrão de recuperação baseada em vetores. O método Section Titan segmenta procedimentos por seções de documentos (~250 palavras por trecho) e embeda os trechos com Titan Text Embeddings v2. O método Summaries Titan embeda os resumos de procedimentos, melhorando a exatidão em comparação aos trechos. O método Summaries Cohere utiliza Cohere Multilingual v3 para embeddings. O modelo Cohere Multilingual produziu melhoria notável com todos os valores top-k acima de 90%. Em seguida, as configurações com Reasoning Retriever embutem resumos com embeddings Cohere e aplicam o raciocínio com Haiku/Claude no Bedrock, obtendo, segundo a avaliação, até 98,9% de exatidão top-1 e melhoria de 12,5–17,5% sobre o RAG padrão. Do ponto de vista de qualidade linguística, especialistas valorizaram que as respostas do Boti apresentam uso de voseo em 98% dos casos e tempo verbal futuro periprástico em 92% dos casos. Esses números indicam que o sistema não apenas fornece informações corretas, mas também se alinha ao estilo linguístico regional.
Por que isso importa (impacto para desenvolvedores/empresas)
O projeto demonstra como uma prefeitura pode escalar um assistente de IA para gerenciar um inventário grande de procedimentos mantendo padrões de segurança e precisão. O desenho de guardrails personalizado e linguístico mostra como organizações podem adaptar sistemas de IA gerativa para refletir normas locais e línguas sem sacrificar a segurança. Ao integrar LangGraph com o Bedrock, desenvolvedores podem construir assistentes agenticos que combinam recuperação robusta, desambiguização precisa e geração contextual. Para empresas, o projeto oferece um modelo de arquitetura prática: um sistema de duas camadas que protege usuários de conteúdo nocivo enquanto permite recuperação complexa sobre uma base de conhecimento bem estruturada. A dação de disambiguation por raciocínio é particularmente relevante para domínios com procedimentos, regras e exceções. A solução também destaca impacto real: respostas rápidas e úteis, com orientação segura quando a consulta sai do escopo on-topic. A integração com Bedrock Knowledge Bases e Bedrock Converse API demonstra como organizações podem obter inferência escalável com LLMs dentro de um ecossistema de armazenamento de conhecimento governamental.
Detalhes técnicos ou Implementação
- Arquitetura do sistema: duas trilhas paralelas no momento da consulta — guardrail de entrada e o agente de procedimentos governamentais. O guardrail atribui uma categoria primária (aprovado ou bloqueado) e uma subcategoria; consultas aprovadas vão para o agente; bloqueadas são redirecionadas para tópicos seguros.
- Guardrail de entrada: classificador de LLM personalizado para detectar conteúdo nocivo, incluindo linguagem ofensiva, opiniões perigosas, tentativas de injeção de prompt e comportamentos antiéticos. Na avaliação, o guardrail bloqueou 100% das queries nocivas, com algumas consultas normais sinalizadas como nocivas de forma conservadora.
- Agente de procedimentos: utiliza uma ferramenta de recuperação dentro de um framework RAG para buscar contexto nos Bedrock Knowledge Bases e gerar respostas em Rioplatense espanhol.
- Construção do knowledge base: metadados básicos dos procedimentos (propósito, público, custos, etapas, requisitos) mais resumos comparativos que descrevem diferenças entre procedimentos. Os resumos são agrupados em clusters (~5 por grupo) e enriquecidos com descrições de diferenciação geradas por um LLM. A combinação de informações básicas + resumos discriminatórios forma as entradas do knowledge base. Essa abordagem é inspirada em Contextual Retrieval, mas adaptada para o contexto local.
- Reasoning Retriever: após a recuperação inicial, o agente aplica um raciocínio com estilo de cadeia de pensamento para identificar os procedimentos relevantes e as fontes URL a citar, garantindo rastreabilidade.
- Modelos e avaliação: abordagens padrão incluíam Titan (porções de ~250 palavras), Summaries Titan e Summaries Cohere. Embeddings multilingues Cohere produziram excelente desempenho com todos os valores top-k acima de 90%. Configurações com Reasoning Retriever usaram embeddings Cohere + modelos LLM (Haiku 3, Claude 3 Sonnet, Claude 3.5 Sonnet) no Bedrock para selecionar os resultados mais relevantes, atingindo até 98,9% de exatidão top-1 e melhoria de 12,5–17,5% frente ao RAG tradicional.
- Inferência e latência: tanto o guardrail quanto o agente utilizam a Bedrock Converse API para inferência de LLM, o que facilita a otimização de desempenho em várias subtarefas.
- Avaliação e fidelidade linguística: especialistas registraram 98% de precisão no uso do voseo e 92% de precisão no tempo verbal periprástico, confirmando a qualidade linguística das respostas.
Principais aprendizados
- Um sistema de IA em duas camadas (guardrails + agente de procedimentos) pode escalar com segurança para gerenciar centenas de procedimentos governamentais.
- Guardrails personalizados por idioma e contexto local podem oferecer forte segurança sem prejudicar a utilidade das respostas.
- Um fluxo de recuperação por raciocínio com resumos comparativos melhora a desambiguação e a recuperação em domínios com regras complexas.
- Bedrock Knowledge Bases + Bedrock Converse API permitem inferência de LLM escalável para tarefas de informação governamental.
- O Boti demonstra que é possível entregar respostas rápidas e contextualizadas, com tom local, mantendo padrões de segurança.
FAQ
-
Qual é o objetivo do Boti?
judar cidadãos a acessar informações sobre procedimentos governamentais respondendo perguntas e orientando para o procedimento correto.
-
Como funciona o guardrail de entrada?
Usa um classificador de LLM personalizado que decide entre aprovado ou bloqueado, permitindo que consultas aprovadas sigam para o agente de procedimentos; consultas bloqueadas são redirecionadas.
-
O que é o Reasoning Retriever e por que ele é usado?
O Reasoning Retriever usa resumos comparativos e seleção baseada em LLM para desambiguar procedimentos e identificar os resultados mais relevantes.
-
uais resultados de desempenho foram observados?
O guardrail bloqueou 100% das consultas nocivas na avaliação e o Reasoning Retriever atingiu até 98,9% de exatidão top-1, com ganho de 12,5–17,5% sobre o RAG. Especialistas relataram 98% de precisão no voseo e 92% no tempo verbal periprástico.
-
uais tecnologias são usadas?
LangGraph, Amazon Bedrock, Bedrock Knowledge Bases e Bedrock Converse API.
Referências
- AWS ML Blog: Meet Boti: The AI assistant transforming how the citizens of Buenos Aires access government information with Amazon Bedrock. https://aws.amazon.com/blogs/machine-learning/meet-boti-the-ai-assistant-transforming-how-the-citizens-of-buenos-aires-access-government-information-with-amazon-bedrock/
More news

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.

Prompting para precisão com Stability AI Image Services no Amazon Bedrock
O Bedrock now oferece Stability AI Image Services com nove ferramentas para criar e editar imagens com maior precisão. Veja técnicas de prompting para uso empresarial.

Aumente a produção visual com Stability AI Image Services no Amazon Bedrock
Stability AI Image Services já estão disponíveis no Amazon Bedrock, oferecendo capacidades de edição de mídia prontas para uso via Bedrock API, ampliando os modelos Stable Diffusion 3.5 e Stable Image Core/Ultra já existentes no Bedrock.

Use AWS Deep Learning Containers com o SageMaker AI gerenciado MLflow
Explore como os AWS Deep Learning Containers (DLCs) se integram ao SageMaker AI gerenciado pelo MLflow para equilibrar controle de infraestrutura e governança robusta de ML. Um fluxo de trabalho de predição de idade de ostra com TensorFlow demonstra rastreamento de ponta a ponta, governança de model

Construir Fluxos de Trabalho Agenticos com GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore
Visão geral de ponta a ponta para implantar modelos GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore, alimentando um analisador de ações com múltiplos agentes usando LangGraph, incluindo quantização MXFP4 de 4 bits e orquestração serverless.