Como o Amazon Finance construiu um assistente de IA usando Amazon Bedrock e Amazon Kendra para apoiar analistas na descoberta de dados e insights de negócios
Sources: https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights, https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights/, AWS ML Blog
TL;DR
- O Amazon Finance criou um assistente de IA que combina o LLM Anthropic Claude 3 Sonnet via Amazon Bedrock com a busca inteligente do Amazon Kendra para ajudar analistas na descoberta de dados e geração de insights.
- A solução usa Retrieval Augmented Generation (RAG): vetores para busca semântica e geração aumentada que se ancora no conhecimento recuperado para reduzir alucinações.
- O Amazon Kendra Enterprise Edition Index foi escolhido em detrimento do OpenSearch Service e do Amazon Q Business por conta de capacidades integradas, processamento de documentos em mais de 40 formatos, conectores empresariais e manejo avançado de consultas.
- A interface é construída com Streamlit; avaliações indicam redução de 30% no tempo de busca e melhoria de 80% na exatidão dos resultados de busca, com ganhos de precisão e recall.
- A arquitetura padroniza o acesso a dados em toda a Amazon Finance, preserva conhecimento institucional e aumenta a agilidade de tomada de decisão. As afirmações acima resumem a implementação descrita pela equipe de Amazon Finance e citadas no AWS ML Blog [https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-built-an-ai-assistant-using-amazon-bedrock-and-amazon-kendra-to-support-analysts-for-data-discovery-and-business-insights/].
Contexto e antecedentes
Analistas de finanças da Amazon Finance enfrentam complexidade crescente no planejamento e na análise, lidando com grandes conjuntos de dados que atravessam diversos sistemas, lagos de dados e unidades de negócio. Navegar por catálogos de dados manualmente e reconciliar informações de fontes díspares consome tempo significativo, reduzindo o espaço para análises e geração de insights. Dados históricos e decisões passadas residem em documentos e sistemas legados, dificultando o uso de aprendizados anteriores durante ciclos de planejamento. À medida que o contexto de negócios evolui rapidamente, é necessária acesso rápido a métricas relevantes, premissas de planejamento e insights financeiros para apoiar decisões baseadas em dados. Ferramentas tradicionais com buscas por palavras-chave e estruturas de consultas rígidas perdem relacionamentos contextuais em dados financeiros e não capturam adequadamente o conhecimento institucional, levando a análises redundantes e premissas de planejamento inconsistentes entre equipes. Em resumo, analistas precisavam de uma forma mais intuitiva de acessar, entender e usar o conhecimento financeiro da organização e os ativos de dados. A equipe de Amazon Finance desenvolveu um assistente de IA de ponta a ponta para enfrentar esses desafios, combinando IA generativa com busca corporativa. O objetivo foi permitir que analistas interajam com fontes de dados financeiros e documentação por meio de consultas em linguagem natural, reduzindo a necessidade de buscas manuais entre vários sistemas, mantendo respostas ancoradas em uma base de conhecimento corporativa que reflita o contexto institucional e os requisitos de segurança. Essa abordagem não apenas acelera a descoberta de dados, mas também ajuda a preservar raciocínios de decisão e padronizar o planejamento em uma organização distribuída. A solução baseia-se no padrão Retrieval Augmented Generation (RAG), que combina recuperação de conhecimento externo com geração de linguagem. O sistema armazena e consulta representações de texto em alta dimensão usando vetores para suportar buscas semânticas, condiciona o modelo de linguagem ao contexto recuperado e, em seguida, gera respostas alinhadas às fontes. O objetivo é manter a precisão e a responsabilização ao longo das conversas de IA para finanças. A implementação utiliza Large Language Models (LLMs) na Amazon Bedrock e busca semântica com o Amazon Kendra para oferecer uma experiência de assistente corporativo coesa, segura e escalável. O modelo escolhido foi o Claude 3 Sonnet da Anthropic, acessado via Bedrock, por suas capacidades de geração de linguagem e raciocínio. A integração com o Kendra permite entender a intenção do usuário e recuperar respostas relevantes com base em documentos empresariais. Os recursos de segurança empresarial do Kendra ajudam a proteger dados e cumprir requisitos regulatórios de finanças. A interface de usuário segue uma abordagem moderna com Streamlit para facilitar desenvolvimento rápido, iteração e implantação. O foco principal é o Retrieval Augmented Generation (RAG), que separa a recuperação de informações do processo de geração para manter a confiabilidade e a precisão das respostas. A implementação combina LLMs na Bedrock com a busca inteligente do Kendra, formando um fluxo de trabalho que sustenta conversas significativas sobre fontes de dados e contexto de negócios. O post da AWS descreve esse design e os resultados observados, incluindo métricas de tempo de busca e acurácia. [fonte]
O que há de novo
A implementação integra várias tecnologias modernas em um fluxo de trabalho coeso. Componentes-chave:
- Retrieval e augmented generation (RAG) como padrão central, combinando busca semântica com geração ancorada em conhecimento recuperado.
- Camada de recuperação baseada em vetores para busca semântica, permitindo contexto mais rico para o modelo.
- LLMs hospedados na Amazon Bedrock, com Claude 3 Sonnet para geração de linguagem e raciocínio.
- Amazon Kendra Enterprise Edition Index para interpretação de linguagem natural, processamento automático de documentos em mais de 40 formatos, conectores empresariais pré-construídos e manejo inteligente de consultas, incluindo reconhecimento de sinônimos e sugestões de refinamento. Essas capacidades reduzem a necessidade de configuração manual e melhoram a qualidade da recuperação. A equipe comparou Kendra com o OpenSearch Service, destacando que este último exige personalização extensa para alcançar capacidades similares, enquanto o Kendra oferece recursos integrados adequados a casos de uso de finanças. Também foi feita a comparação com o Amazon Q Business, e o Kendra foi escolhido pela robustez e flexibilidade na recuperação. Veja as comparações e as motivações no References.
- UI e ferramentas: Streamlit foi escolhido por permitir desenvolvimento rápido, integração com Python, componentes interativos, potencial de visualização e implantação simples.
- Templates de prompt para formatar consultas, incorporar conhecimento recuperado e impor restrições de geração.
- Um framework de avaliação para quantificar desempenho (precisão, recall, tempo de resposta) e qualidade da experiência do usuário. A arquitetura enfatiza ancorar respostas em fontes corporativas e conhecimento institucional, o que é essencial para casos de finanças onde precisão e rastreabilidade são cruciais. A equipe selecionou Claude 3 Sonnet (Anthropic) via Bedrock por suas capacidades de geração de linguagem, e integrou-o ao Kendra para suportar um fluxo RAG coeso que recorta a necessidade de configuração manual, mantendo o foco em dados financeiros. A tabela a seguir resume as razões de escolha entre Kendra, OpenSearch e Q Business.
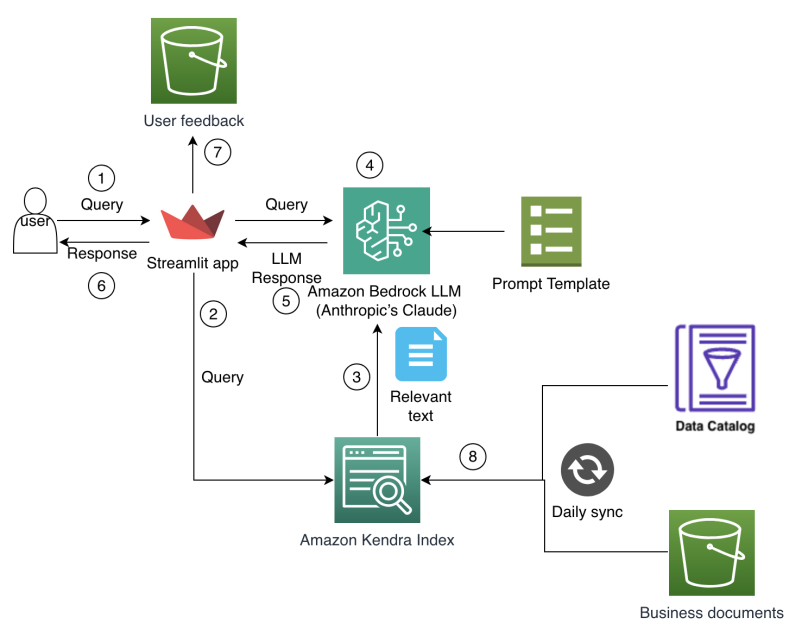
Arquitetura e fluxo de trabalho
O fluxo de conversa do assistente segue três etapas: (1) recuperar informações relevantes a partir de fontes de conhecimento usando busca semântica, (2) Condicionar o modelo de linguagem com esse contexto recuperado e (3) gerar respostas refinadas que incorporam as informações recuperadas. Esse ciclo garante que as saídas estejam ancoradas em documentos e catálogos de dados da empresa, mantendo a qualidade da conversa com explicações naturais. A arquitetura de frontend foi desenhada para apoiar modificações rápidas, escalabilidade e segurança, permitindo que analistas interajam com fontes de dados e documentos por meio de uma interface de usuário limpa e responsiva. O painel e o chat são estruturados para acomodar novos catálogos de dados e fontes de conhecimento à medida que o metadata cresce. A framework de avaliação capturou métricas quantitativas (precisão, recall, tempo de resposta) e indicadores de usabilidade (utilidade, qualidade das respostas). Em testes com analistas, a solução registrou uma redução de 30% no tempo de busca e um aumento de 80% na exatidão dos resultados. Os números de precisão e recall foram registrados em tarefas de descoberta de dados (precisão inicial 65%, recall 60% sem enriquecimento de metadados) e busca de conhecimento (precisão 83%, recall 74% sem enriquecimento). Esses resultados indicam ganhos significativos, com expectativa de que melhorias de metadados elevem ainda mais o desempenho à medida que o acervo de dados corporativos amadurece. O post da AWS detalha essas escolhas de design e resultados, conforme Referências.
Detalhes técnicos ou Implementação
Componentes centrais e motivação:
- Recuperação inteligente com vetores para busca semântica, oferecendo contexto mais rico para o modelo e resultados mais precisos do que abordagens apenas por palavras-chave.
- Geração aumentada (RAG) para produzir respostas contextuais e precisas condicionando Claude 3 Sonnet ao conhecimento recuperado.
- Large Language Models (LLMs) hospedados na Amazon Bedrock, com Claude 3 Sonnet escolhido pela capacidade de geração de linguagem e raciocínio.
- Amazon Kendra Enterprise Edition Index utilizado para NLP avançado, processamento automático de documentos em mais de 40 formatos, conectores empresariais e manejo de consultas com reconhecimento de sinônimos e sugestões de refinamento. Essa combinação reduz a necessidade de configuração manual e melhora a qualidade da recuperação. A equipe destacou que o OpenSearch exige personalização extensa para alcançar capacidades similares, e que o Kendra oferece recursos embutidos adequados para casos de finanças. A comparação com o Q Business evidenciou que o Kendra é mais robusto e flexível para recuperação de informações. Consulte as Referências para o contexto completo.
- UI e ferramentas: Streamlit para desenvolvimento rápido, integração com Python, componentes interativos, visualização e implantação simples. Templates de prompt estruturam consultas, integração de conhecimento recuperado e imposição de restrições de geração.
- Estrutura de avaliação: métricas de precisão, recall e tempo de resposta para mensurar melhorias em descoberta de dados e busca de conhecimento. Os resultados indicam ganhos expressivos na descoberta de dados e na confiabilidade das respostas, com a expectativa de melhorias adicionais à medida que metadata se torna mais rica. A seguir, uma tabela de comparação que ilustra por que Kendra foi escolhido em detrimento de alternativas: | Serviço | Motivo de uso | Principais recursos relevantes para este caso |---|---|---| | Amazon Kendra Enterprise Edition Index | NLP pronto para uso, menos configuração | Compreensão de linguagem natural, processamento automático de documentos para 40+ formatos, conectores empresariais, manuseio inteligente de consultas incluindo sinônimos e sugestões de refino |OpenSearch Service | Requer personalização extensa | Implementação manual de recursos de busca semântica e vetorial |Amazon Q Business | Menos robusto/flexível | Capacidades de recuperação, porém menos amadurecidas para cenários empresariais | Essa escolha, aliada à integração com Bedrock e Kendra, sustenta um fluxo RAG que ancora as respostas em fontes corporativas, mantendo uma experiência de conversação confiável para analistas de finanças. Para mais detalhes, consulte o post da AWS em Referências. [fonte]
Por que isso importa (impacto para desenvolvedores/empresas)
Essa abordagem demonstra como organizações podem escalar IA orientada a dados para descoberta e suporte à decisão mantendo governança e segurança. Ao ancorar respostas em um conhecimento corporativo central e usar busca semântica para trazer os documentos certos, analistas obtêm acesso mais rápido a métricas relevantes, premissas de planejamento e raciocínios históricos. O padrão RAG permite manter a confiabilidade ao tempo que proporciona conversas em linguagem natural com referências baseadas em fontes oficiais. Para desenvolvedores e engenheiros de dados, a arquitetura apresenta um caminho pragmático para combinar recuperação baseada em vetores com um LLM robusto e uma camada de busca empresarial, resultando em uma ferramenta pronta para produção capaz de tratar consultas financeiras com alta fidelidade. A disponibilidade de Kendra Enterprise Edition oferece recursos de NLP, processamento de documentos e conectores que facilitam conformidade e governança em finanças. O impacto prático é maior agilidade no planejamento, decisões mais consistentes e melhor interoperabilidade entre operações globais. O post da AWS descreve um caso concreto que respalda esses benefícios. [fonte]
Principais lições (takeaways)
- Fluxos de IA fundamentados em recuperação (RAG) podem transformar a descoberta de dados e a geração de insights em finanças.
- Busca semântica baseada em vetores, aliada à geração, reduz alucinações e aumenta a precisão.
- Escolha de uma solução de busca empresarial com NLP embutido e processamento de documentos (Kendra Enterprise Edition) facilita adoção e conformidade.
- Interface de usuário baseada em Streamlit facilita desenvolvimento rápido e iteração com analistas.
- Um framework de avaliação estruturado orienta melhorias contínuas, especialmente com o enriquecimento de metadados ao longo do tempo.
FAQ
-
Como o assistente grounda suas respostas?
Ele recupera informações relevantes com busca semântica em um repositório vetorial, condiciona Claude 3 Sonnet ao contexto recuperado e gera respostas alinhadas às fontes recuperadas.
-
Por que escolher Claude 3 Sonnet via Bedrock para este caso?
Claude 3 Sonnet oferece capacidades fortes de geração de linguagem e raciocínio, compatíveis com um fluxo RAG que precisa de respostas naturais e bem fundamentadas.
-
uais foram as métricas observadas na avaliação?
Redução de 30% no tempo de busca e melhoria de 80% na exatidão dos resultados de busca, com ganhos de precisão/recall em tarefas de descoberta de dados e busca de conhecimento.
-
uais as vantagens do Kendra Enterprise Edition frente OpenSearch ou Q Business?
NLP pronto para uso, processamento automático de documentos, conectores empresariais, reconhecimento de sinônimos e sugestões de refinamento, reduzindo configuração manual e elevando a qualidade da recuperação.
Referências
More news

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Como reduzir gargalos do KV Cache com NVIDIA Dynamo
O Dynamo da NVIDIA transfere o KV Cache da memória da GPU para armazenamento de custo mais baixo, permitindo janelas de contexto maiores, maior concorrência e menor custo de inferência em grandes modelos.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.

Prompting para precisão com Stability AI Image Services no Amazon Bedrock
O Bedrock now oferece Stability AI Image Services com nove ferramentas para criar e editar imagens com maior precisão. Veja técnicas de prompting para uso empresarial.

Aumente a produção visual com Stability AI Image Services no Amazon Bedrock
Stability AI Image Services já estão disponíveis no Amazon Bedrock, oferecendo capacidades de edição de mídia prontas para uso via Bedrock API, ampliando os modelos Stable Diffusion 3.5 e Stable Image Core/Ultra já existentes no Bedrock.

Use AWS Deep Learning Containers com o SageMaker AI gerenciado MLflow
Explore como os AWS Deep Learning Containers (DLCs) se integram ao SageMaker AI gerenciado pelo MLflow para equilibrar controle de infraestrutura e governança robusta de ML. Um fluxo de trabalho de predição de idade de ostra com TensorFlow demonstra rastreamento de ponta a ponta, governança de model