Capacitando a pesquisa de qualidade do ar com análises preditivas seguras baseadas em ML
Sources: https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-with-secure-ml-driven-predictive-analytics, https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-with-secure-ml-driven-predictive-analytics/, AWS ML Blog
TL;DR
- Um fluxo de imputação de dados preenche lacunas de PM2.5 com ML treinado no SageMaker Canvas, orchestrado por AWS Lambda e AWS Step Functions.
- O conjunto de dados de exemplo inclui mais de 15 milhões de registros de mar/2022 a out/2022, em Kenya e Nigéria, de 23 sensores em 15 locais.
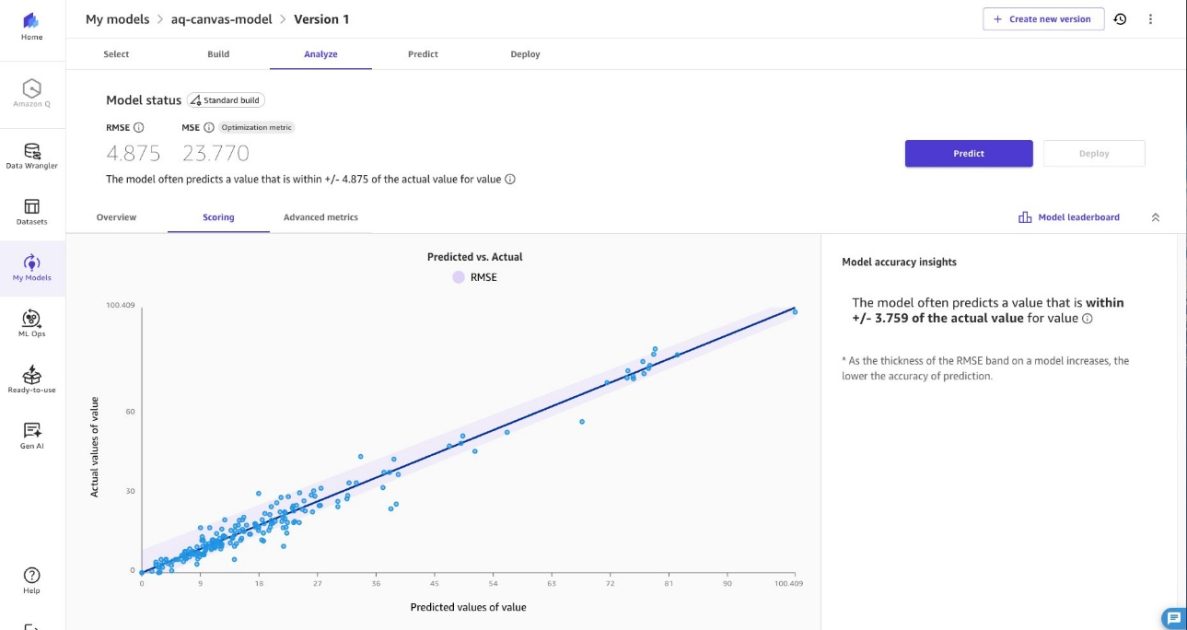
- As previsões são geradas para valores de PM2.5 ausentes dentro de um intervalo de até +/- 4,875 µg/m³ para manter a precisão das tendências.
- A solução enfatiza segurança, criptografia e implantação em rede privada, com um modelo de responsabilidade compartilhada orientando as proteções do cliente.
Contexto e antecedentes
A poluição do ar continua sendo um desafio crítico de saúde ambiental na África. Organizações como sensors.AFRICA implantaram centenas de sensores para monitorar as condições, mas lacunas de dados persistem devido a instabilidades de energia e conectividade em regiões de alto risco, onde a manutenção é limitada. Dados PM2.5 ausentes reduzem poder estatístico e introduzem vieses, dificultando a detecção de tendências confiável e conclusões robustas sobre padrões de qualidade do ar. Essas lacunas comprometem decisões baseadas em evidências para controle da poluição, avaliações de impactos à saúde e conformidade regulatória. A exposição a PM2.5 está associada a milhões de mortes prematuras globalmente, destacando a importância de previsões precisas para a saúde pública. O post demonstra a capacidade de entropia temporal do Amazon SageMaker Canvas, uma plataforma de ML de baixo código, para prever valores de PM2.5 a partir de dados incompletos. O Canvas oferece resiliência a dados ausentes, permitindo operação contínua de redes de monitoramento durante falhas de sensores ou manutenção. Isso ajuda agências ambientais e autoridades de saúde pública a manter acesso ininterrupto a informações críticas para alertas oportunos e análises de longo prazo. A abordagem combina previsão com imputação de dados usando Amazon SageMaker AI, AWS Lambda e AWS Step Functions. O conjunto de dados de demonstração foi obtido a partir do openAFRICA e contém mais de 15 milhões de registros entre mar/2022 e out/2022, de 23 dispositivos em 15 locais, na Kenya e Nigéria, ilustrando como a solução pode ser adaptada a dados reais. A arquitetura centra-se em dois componentes de ML: um fluxo de treinamento e um fluxo de inferência. Os fluxos são construídos com o SageMaker Canvas para desenvolvimento de modelos e exportação para inferência em lote. O processo começa com a extração de dados de sensores de um banco de dados, importação para o Canvas para análise preditiva e treinamento, exportando o modelo treinado para uso em batch processing. O método suporta re-treinamento com novos dados de PM2.5.
O que há de novo
O artigo demonstra um fluxo completo e seguro de imputação de dados para lacunas de PM2.5 usando uma combinação de serviços da AWS. Características-chave:
- Previsão de séries temporais com SageMaker Canvas para estimar valores ausentes de PM2.5 em dados com lacunas.
- Fluxo de ponta a ponta robusto: extração de dados, treinamento no Canvas, exportação do modelo e pipeline de inferência em lote.
- Orquestração diária: uma função Lambda executa a cada 24 horas para iniciar um trabalho de Transformação em Lote do SageMaker nos dados com lacunas, atualizando o conjunto de dados com as previsões.
- Dados de demonstração realistas: o conjunto usa mais de 15 milhões de registros de Mar 2022 a Oct 2022, de Kenya e Nigéria, com 23 sensores em 15 locais.
- Segurança em primeiro lugar: criptografia em repouso no S3, no banco de dados Aurora PostgreSQL-compatible e no SageMaker Canvas; criptografia em trânsito via TLS; credenciais temporárias IAM para o acesso ao RDS; funções Lambda com mínimo privilégio; implantação em sub-redes privadas com pontos finais VPC para S3 e SageMaker AI.
- Implantação via IaC: o article descreve um fluxo baseado em CDK para treinamento, registro de modelo e implantação, permitindo atualizações consistentes. Para implementar, o projeto oferece um repositório com código de exemplo e um README com instruções passo a passo. A arquitetura visa entregar dados PM2.5 completos a decisores de saúde pública, apoiando alertas de poluição oportunos e análises de longo prazo.
Por que isso importa (impacto para desenvolvedores/empresas)
Para equipes de desenvolvimento e empresas que trabalham com monitoramento ambiental, esta abordagem oferece:
- Pipelines de dados resilientes que mantêm a operação mesmo com falhas de sensores, reduzindo lacunas de dados e custos de indisponibilidade.
- Insights acionáveis de PM2.5 extraídos de dados incompletos sem exigir streams perfeitos, ajudando pesquisadores e formuladores de políticas a manter visibilidade de tendências a tempo.
- Solução escalável, segura e baseada em nuvem que se integra a armazéns de dados existentes (Aurora) e armazenamento de objetos (S3), com controles de segurança rigorosos.
- Padrão de implantação audível: infraestrutura como código via CDK permite implantações consistentes e mais fáceis de atualizar conforme a rede de sensores muda.
- Diretrizes claras de proteção de dados em trânsito e em repouso, com permissões granulares IAM e rede privada para minimizar exposições. Este trabalho está alinhado com objetivos de saúde pública, permitindo monitoramento contínuo e análises mais confiáveis de PM2.5, apoiando estratégias de controle de poluição e conformidade regulatória.
Detalhes técnicos ou Implementação
A solução compreende dois componentes principais de ML: um fluxo de treinamento e um fluxo de inferência, ambos integrados a um pipeline seguro.
- Dados e treinamento
- Dados históricos de PM2.5 são extraídos de um banco de dados relacional e preparados no SageMaker Canvas para análise preditiva.
- O Canvas suporta treinar um modelo para previsão de um único alvo com transformações de dados e engenharia de recursos adequadas para séries temporais.
- Após o treinamento, o Canvas exporta o modelo para inferência em lote.
- O conjunto de dados de treinamento de exemplo contém mais de 15 milhões de registros entre Mar/2022 e Out/2022, de 23 sensores em 15 locais na Kenya e Nigéria.
- Inferência e imputação de dados
- O Step Functions coordena o fluxo; uma função Lambda é chamada a cada 24 horas.
- A função Lambda inicia um trabalho de Transformação em Lote do SageMaker para prever valores ausentes nos dados novos com lacunas.
- A transformação em lote processa todo o conjunto de dados em uma única passagem, atualizando o conjunto com as previsões.
- O conjunto de dados resultante permite a distribuição a decision-makers de saúde pública para análises de padrões de PM2.5 mais eficazes.
- Ciclo de vida do modelo e implantação
- Após treinamento e avaliação (incluindo RMSE e outras métricas), o modelo é registrado no SageMaker Model Registry e implantado para inferência em lote.
- O fluxo baseado em CDK cria um domínio SageMaker AI e perfil de usuário, provisionando recursos para treinamento e inferência.
- Um fluxo inclui criar o modelo SageMaker em uma VPC, implantar o trabalho de transformação em lote e atualizar a infraestrutura com o novo ID do modelo via cdk deploy.
- A solução suporta re-treinamento com dados PM2.5 atualizados para adaptar-se a padrões de sensores em evolução.
- Destaques de segurança e conformidade
- Criptografia em repouso ativada para S3, Aurora e SageMaker Canvas.
- Criptografia em trânsito com TLS para todas as conexões de Lambda.
- Credenciais temporárias IAM para o RDS, eliminando senhas estáticas.
- Funções Lambda operam com privilégios mínimos, com acessos específicos para cada função.
- A implantação acontece em sub-redes privadas da VPC, sem acesso direto à Internet pública, com endpoints VPC para S3 e SageMaker AI.
- Configuração e extensibilidade
- A arquitetura foi pensada para ser adaptável a futuras alterações de configuração via CDK, com um arquivo de configuração descrevendo os parâmetros padrão.
- A adoção prioriza segurança e alinhamento com o AWS Shared Responsibility Model, incentivando clientes a revisar responsabilidades de implantação segura.
- Tabela: componentes-chave e papéis
| Componente | Papel |
|---|---|
| SageMaker Canvas | Treinamento e exportação do modelo para inferência em lote |
| AWS Lambda | Orquestra a atualização de dados e inicia transformações em lote a cada 24 horas |
| AWS Step Functions | Coordena o fluxo de trabalho de ponta a ponta |
| Amazon Aurora PostgreSQL‑Compatible | Armazena dados de sensores com acesso IAM autenticado |
| Amazon S3 | Armazenamento de dados em data lake com criptografia em repouso |
- Referências e notas de implantação
- A abordagem é documentada com código de exemplo e instruções passo a passo no repositório Git: [email protected]:aws-samples/sample-empowering-air-quality-research-secure-machine-learning-predictive-analytics.git
- O artigo publicado está disponível em https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-secure-ml-driven-predictive-analytics/.
Principais conclusões
- Imputação de lacunas de PM2.5 com um modelo SageMaker Canvas e pipeline de inferência em lote é viável.
- Lambda aciona a transformação em lote diariamente, mantendo dados atualizados com interrupções mínimas no monitoramento.
- Medidas de segurança, incluindo criptografia, credenciais IAM temporárias e sub-redes privadas, ajudam a proteger dados ambientais sensíveis.
- O padrão orientado por IaC facilita implantações reproduzíveis, auditáveis e escaláveis.
FAQ
-
Como a imputação de PM2.5 é realizada?
O fluxo treina um modelo SageMaker Canvas com dados históricos de PM2.5 e usa um trabalho de Transformação em Lote para prever valores ausentes dentro de +/- 4,875 µg/m³ da concentração real.
-
ue dados foram usados no exemplo?
Um conjunto de dados de treinamento do openAFRICA com mais de 15 milhões de registros entre Mar/2022 e Out/2022, coletados na Kenya e Nigéria a partir de 23 sensores em 15 locais.
-
uais serviços da AWS compõem o pipeline?
SageMaker Canvas para treinamento e exportação, AWS Lambda para orquestração, AWS Step Functions para coordenação, SageMaker Transform para inferência, Amazon Aurora PostgreSQL-compatible para armazenamento e Amazon S3 para data lake, tudo em rede privada segura.
-
Como a segurança é tratada?
Criptografia em repouso (S3, Aurora, SageMaker Canvas), criptografia em trânsito (TLS), credenciais temporárias IAM para RDS, privilégios mínimos nas funções Lambda, sub-redes privadas com endpoints VPC, em conformidade com o AWS Shared Responsibility Model.
-
Como posso implantar isso no meu ambiente?
O repositório fornece um fluxo baseado em CDK com um README com instruções para reproduzir o fluxo de ponta a ponta e adaptar aos seus conjuntos de dados PM2.5.
Referências
- https://aws.amazon.com/blogs/machine-learning/empowering-air-quality-research-secure-ml-driven-predictive-analytics/
- [email protected]:aws-samples/sample-empowering-air-quality-research-secure-machine-learning-predictive-analytics.git
More news

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.

Prompting para precisão com Stability AI Image Services no Amazon Bedrock
O Bedrock now oferece Stability AI Image Services com nove ferramentas para criar e editar imagens com maior precisão. Veja técnicas de prompting para uso empresarial.

Aumente a produção visual com Stability AI Image Services no Amazon Bedrock
Stability AI Image Services já estão disponíveis no Amazon Bedrock, oferecendo capacidades de edição de mídia prontas para uso via Bedrock API, ampliando os modelos Stable Diffusion 3.5 e Stable Image Core/Ultra já existentes no Bedrock.

Use AWS Deep Learning Containers com o SageMaker AI gerenciado MLflow
Explore como os AWS Deep Learning Containers (DLCs) se integram ao SageMaker AI gerenciado pelo MLflow para equilibrar controle de infraestrutura e governança robusta de ML. Um fluxo de trabalho de predição de idade de ostra com TensorFlow demonstra rastreamento de ponta a ponta, governança de model

Construir Fluxos de Trabalho Agenticos com GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore
Visão geral de ponta a ponta para implantar modelos GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore, alimentando um analisador de ações com múltiplos agentes usando LangGraph, incluindo quantização MXFP4 de 4 bits e orquestração serverless.