Como os Serviços de Saúde da Amazon Melhoraram a Descoberta na Busca da Amazon com AWS ML e Gen AI
Sources: https://aws.amazon.com/blogs/machine-learning/learn-how-amazon-health-services-improved-discovery-in-amazon-search-using-aws-ml-and-gen-ai, https://aws.amazon.com/blogs/machine-learning/learn-how-amazon-health-services-improved-discovery-in-amazon-search-using-aws-ml-and-gen-ai/, AWS ML Blog
TL;DR
- A busca em saúde envolve relações complexas entre sintomas, condições, tratamentos e serviços, exigindo compreensão avançada de terminologia médica e intenção do usuário.
- A Amazon Health Services resolveu os desafios de descoberta na busca da Amazon aproveitando uma pilha de AWS em três partes: SageMaker para modelos de ML, Bedrock para capacidades de LLM e EMR/Athena para processamento de dados.
- A abordagem combina compreensão de consultas alimentada por ML, busca vetorial para correspondência de produtos e otimização de relevância por meio de LLM usando o padrão Retrieval Augmented Generation.
- Um conhecimento abrangente foi expandido com termos de ontologia de saúde e prompts refinados de LLM, embeddings criados com FAISS e armazenados no S3 para busca por similaridade.
- A solução é usada diariamente para ajudar clientes a encontrar desde medicamentos com prescrição até cuidados primários e especializados por meio da Health Benefits Connector e ofertas correlatas.
Contexto e antecedentes
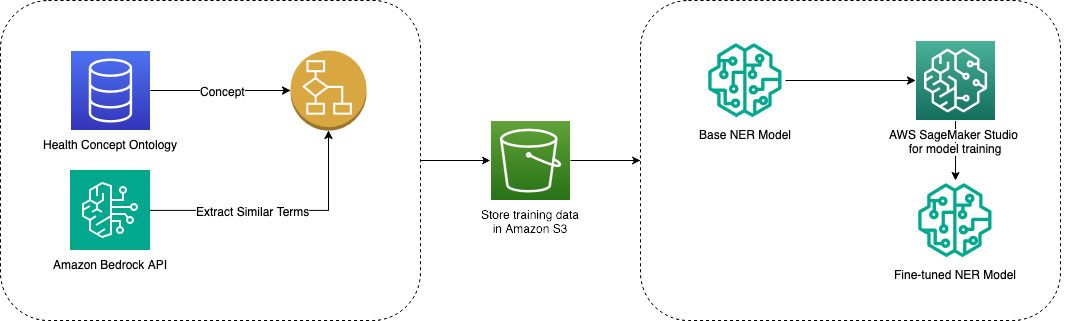
Descoberta de saúde em domínios de comércio eletrônico apresenta desafios que a busca de produtos tradicional não foi projetada para enfrentar. Diferentemente de livros ou eletrônicos, consultas de saúde envolvem relações sutis entre sintomas, condições, tratamentos e serviços, exigindo interpretação sofisticada de terminologia médica e intenção do usuário. Com a expansão da Amazon para serviços de saúde, a disponibilidade de medicamentos com prescrição via Amazon Pharmacy, atendimento primário via One Medical e parcerias de cuidado especializado via Health Benefits Connector trouxeram novos obstáculos técnicos e oportunidades. Este texto explica como a Amazon Health Services (AHS) aprimorou a descoberta na busca da Amazon.com utilizando serviços AWS como SageMaker, Bedrock e EMR para conectar clientes a ofertas de saúde relevantes, com uso diário da solução para consultas relacionadas à saúde. A iniciativa reconhece dois extremos da jornada de busca do cliente. Em um extremo estão as consultas spearfishing, com intenção de busca de baixo nível, que pedem produtos específicos com atributos precisos. No outro extremo estão consultas amplas de saúde, que buscam informações e recomendações que podem abranger vários tipos de produto. Essa moldura guiou a criação de duas capacidades especializadas para cobrir o espectro completo de buscas de saúde. Para identificar a intenção spearfishing, foram analisados dados anonimizados de engajamento de busca com produtos e treinado um classificador para detectar palavras chave que levam diretamente ao engajamento com ASINs de Farmácia Amazon. O processamento de dados para isso utilizou PySpark em EMR e Athena. Para identificar a intenção ampla de saúde, foi treinado um modelo de reconhecimento de entidades nomeadas para anotar termos de saúde em linguagem médica. Construímos um corpus de ontologia de saúde para reconhecer conceitos como condições, doenças, tratamentos, lesões e medicamentos. Quando termos alternativos não estavam presentes na base de conhecimento, utilizamos modelos de grande linguagem para expandir o vocabulário. O modelo NER fica protegido por previsões de tipos de produto relevantes para saúde gerados por modelos de tipo de produto de consulta para produto da Amazon. A fim de apoiar isso, começamos com os dados de catálogo existentes e expandimos com um grande modelo de linguagem por meio de um prompt ajustado e exemplos de few-shot para incluir termos adicionais relevantes de condições, sintomas e tratamentos para cada produto ou serviço. A base de conhecimento resultante foi convertida em embeddings usando FAISS, com um arquivo de índice para busca eficiente por similaridade. Mantivemos mapeamentos cuidadosos entre os embeddings e os itens da base de conhecimento para consultas de recuperação reversa quando necessário. Esse processo utilizou S3 para armazenamento e o OpenSearch Service foi apontado como uma opção viável para capacidades de banco de dados vetorial. Grandes pipelines de embedding foram executados com trabalhos programados no SageMaker. O design Retrieval Augmented Generation (RAG) foi fundamental. O primeiro passo é identificar palavras-chave conhecidas e produtos da Amazon para estabelecer a verdade de base. Com a base de conhecimento construída a partir de metadados de catálogo e atributos de ASIN, a consulta do cliente é convertida em embedding e utilizada como chave de busca no índice de similaridade. As correspondências são avaliadas com base em um critério de relevância definido pela estrutura ESCI — exato, substituto, complemento, irrelevante. Um time de rotulagem humano ajuda a estabelecer o ground truth, guiado pela estrutura ESCI, complementado por rotulagem com LLMs via job batch do Bedrock. A arquitetura é inteiramente baseada na AWS: SageMaker para modelos de ML, Bedrock para capacidades de LLM e EMR e Athena para processamento de dados. O objetivo é cobrir desde a compreensão de consultas de saúde até a recuperação de conhecimento relevante para serviços de saúde disponíveis na plataforma de ecommerce. O resultado é uma experiência de busca que alinha a intenção do usuário com os serviços e produtos de saúde mais relevantes, facilitando o acesso a cuidados.
O que há de novo
- Separação explícita entre intenções spearfishing e busca de saúde ampla com modelos dedicados de ML e NLP.
- Introdução de um mecanismo de recuperação em duas etapas: busca por similaridade com FAISS baseada em um knowledge base de saúde enriquecido, seguida por rotinas de relevância com ESCI.
- Expansão do knowledge base de saúde usando augmentação por LLM via Bedrock em lote, com ontologia de saúde para cobrir termos adicionais.
- Arquitetura RAG para conectar consultas a itens relevantes do conhecimento e ranqueamento com sinais de relevância aprimorados.
- Retenção de OpenSearch Service como opção de banco de dados vetorial e uso de S3 para armazenamento do knowledge base, com trabalhos de embedding programados no SageMaker.
Por que isso importa (impacto para desenvolvedores/empresas)
Este trabalho demonstra como uma busca voltada para saúde pode ser construída usando ferramentas de dados e ML existentes na nuvem para atender a desafios específicos do domínio. Ao incorporar compreensão de consultas especializada, conceitos de ontologia de saúde e busca vetorial escalável, equipes podem melhorar a relevância dos resultados de busca para serviços e produtos dentro do ecossistema de saúde. A abordagem também exemplifica como arquiteturas no estilo RAG podem manter bases de conhecimento atualizadas e como supervisão por meio de rotulagem humana combinada com rotulagem por LLM ajuda a manter alta qualidade em escala.
Detalhes técnicos ou Implementação
AHS construiu a solução totalmente com AWS, apoiada por três componentes principais:
- Modelos e pipelines de ML com Amazon SageMaker para treinamento e inferência em consultas de saúde.
- Modelos de linguagem de grande escala fornecidos pelo Amazon Bedrock para aprimorar relevância e para augmentar a base de conhecimento por meio de batch inference.
- Processamento de dados e orquestração com Amazon EMR e Amazon Athena para coleta, processamento e consulta em escala. A arquitetura reconhece dois extremos da jornada de busca de saúde:
- Consultas spearfishing com intenção de busca explícita de produto e atributos precisos como nome do medicamento e dosagem.
- Consultas amplas de saúde buscando informações e recomendações que podem abranger vários tipos de produto. Para construir o sistema foram implementadas várias capacidades interligadas:
- Um classificador que identifica a intenção spearfishing analisando dados de engajamento de busca anonimizados de produtos, treinado com PySpark em EMR e Athena.
- Um modelo NER para saúde ampla baseado em um corpus ontológico para reconhecer condições, doenças, tratamentos, lesões e medicamentos. Termos que não estavam presentes na base foram expandidos com LLMs, aumentando a cobertura de sinônimos e termos relacionados.
- Um mecanismo de gating que direciona intenções amplas para tipos de produto relevantes para saúde, assegurando experiências de busca apropriadas para categorias como medicamentos com prescrição ou serviços de cuidado.
- Uma base de conhecimento construída a partir de metadados de catálogo e atributos de ASIN, enriquecida com augmentação de termos de saúde via Bedrock batch inference. A base é transformada em embeddings com FAISS, com um índice e mapeamentos para facilitar buscas reversas.
- Infraestrutura para armazenamento e orquestração incluindo S3 e a observação de OpenSearch Service como opção de banco de dados vetorial.
- Jobs de embedding em larga escala executados por meio de tarefas programadas no SageMaker.
- O padrão Retrieval Augmented Generation para conectar embeddings de consultas a itens de conhecimento relevantes e para ranquear resultados com base em sinais de relevância.
- Rotina de rotulagem com uma equipe humana e com rotulagem baseada em LLM usando Bedrock em lote para melhorar sinais de modelo ao longo do tempo.
Detalhes de implantação
| Componente | Função
| --- |
|---|
| SageMaker |
| Bedrock |
| EMR e Athena |
| FAISS |
| S3 |
| OpenSearch Service |
| Jobs do SageMaker Notebook |
| O fluxo geral segue o padrão de Recuperação Aumentada por Geração, onde a consulta é convertida em embedding, comparada ao índice FAISS para encontrar itens relevantes e, em seguida, refinada por sinais de relevância e por uma etapa de reranking com LLM. A solução é projetada para conectar consultas de saúde a serviços e produtos relevantes na oferta da Amazon, facilitando o acesso a cuidados de saúde. |
Principais aprendizados
- Buscas específicas de saúde exigem compreensão de consultas orientada ao domínio e representações de conhecimento além da busca genérica por produtos.
- Um sistema de recuperação no estilo RAG pode conectar consultas a itens relevantes do conhecimento de saúde por meio de embeddings e um knowledge base bem mantido.
- Augmentação por LLM e rotulagem de relevância com ESCI ajudam a manter a qualidade e a atualidade dos resultados.
- Ferramentas AWS como SageMaker, Bedrock, EMR e FAISS permitem a construção de knowledge bases de saúde escaláveis dentro de um ambiente de ecommerce.
- Rotulagem humana aliada a rotulagem por LLM oferece sinais de qualidade fortes para ranqueamento e relevância, melhorando a descoberta de ofertas de saúde na plataforma.
FAQ
-
Qual problema a AHS abordou na busca da Amazon?
Os desafios de descoberta surgem de consultas de saúde complexas envolvendo sintomas, condições, tratamentos e serviços, indo além da busca tradicional de produtos.
-
uais serviços AWS foram usados para implementar a solução?
mazon SageMaker para ML, Amazon Bedrock para LLMs e Amazon EMR com Athena para processamento de dados.
-
O que é o padrão Retrieval Augmented Generation neste contexto?
O RAG usa embeddings para recuperar itens relevantes do conhecimento de saúde e aplica geração para produzir resultados relevantes com melhor ranking.
-
Como o conhecimento de saúde foi expandido além dos dados de catálogo?
ugmentação por LLM via Bedrock em lote adicionou termos de saúde adicionais com base em ontologia e prompts de few-shot.
-
Como os embeddings são armazenados e consultados?
Embeddings são criados com FAISS e armazenados com mapeamentos para facilitar buscas por similaridade e consultas reversas via S3, com opção de OpenSearch.
Referências
More news

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Como reduzir gargalos do KV Cache com NVIDIA Dynamo
O Dynamo da NVIDIA transfere o KV Cache da memória da GPU para armazenamento de custo mais baixo, permitindo janelas de contexto maiores, maior concorrência e menor custo de inferência em grandes modelos.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.

Prompting para precisão com Stability AI Image Services no Amazon Bedrock
O Bedrock now oferece Stability AI Image Services com nove ferramentas para criar e editar imagens com maior precisão. Veja técnicas de prompting para uso empresarial.

Aumente a produção visual com Stability AI Image Services no Amazon Bedrock
Stability AI Image Services já estão disponíveis no Amazon Bedrock, oferecendo capacidades de edição de mídia prontas para uso via Bedrock API, ampliando os modelos Stable Diffusion 3.5 e Stable Image Core/Ultra já existentes no Bedrock.

Use AWS Deep Learning Containers com o SageMaker AI gerenciado MLflow
Explore como os AWS Deep Learning Containers (DLCs) se integram ao SageMaker AI gerenciado pelo MLflow para equilibrar controle de infraestrutura e governança robusta de ML. Um fluxo de trabalho de predição de idade de ostra com TensorFlow demonstra rastreamento de ponta a ponta, governança de model