Melhore a Análise Geoespacial com Amazon Bedrock: LLMs, RAG e Fluxos GIS
TL;DR
- O Amazon Bedrock oferece uma plataforma segura e flexível para hospedar e invocar modelos de IA e integrá-los a GIS e fluxos relacionados.
- RAG (Recuperação Baseada em Contexto) e fluxos orientados por agentes permitem casos geoespaciais ao combinar bases de conhecimento com dados ao vivo e ações contra provedores externos.
- Bases de conhecimento hospedadas em fontes como S3 e SharePoint fornecem documentos não estruturados; ferramentas podem recuperar informações em tempo real ou controlar processos externos via AWS Lambda, tudo orquestrado por Bedrock Agents.
- O artigo mostra um agente de análise de terremotos que conecta dados do Redshift com consultas geoespaciais para ilustrar capabilities de ponta a ponta.
- Um pipeline prático é descrito, incluindo permissões IAM, configuração da CLI, preparação de dados, configuração do Redshift, uma base de conhecimento e um agente, para demonstrar como operacionalizar Bedrock em contextos GIS.
Contexto e antecedentes
Dados geoespaciais são identificados por posição na Terra (latitude, longitude, altitude), e GIS (Sistemas de Informação Geográfica) oferecem um meio de armazenar, analisar e visualizar essas informações. Em aplicações GIS, os dados costumam ser apresentados em mapas que mostram ruas, edifícios e vegetação. À medida que o volume de dados aumenta e os sistemas de informação ficam mais complexos, as partes interessadas precisam de soluções que revelem insights de qualidade e apoiem fluxos de trabalho intuitivos. LLMs são uma subcategoria de modelos de base ampla e podem transformar entradas de texto (ou imagens, conforme o modelo) em saídas úteis, sendo empregados em várias tarefas de linguagem natural. Amazon Bedrock é um serviço abrangente, seguro e flexível para construir aplicações e agentes de IA generativa. Ele oferece hospedagem e invocação de modelos, além de facilitar a integração com a infraestrutura circundante. Os LLMs atendem a muitas tarefas gerais de processamento de linguagem natural, e em contextos geoespaciais eles podem ampliar fluxos GIS, apoiar a exploração de dados e auxiliar na tomada de decisões. Para adaptar o desempenho dos LLMs a casos de uso específicos, foram desenvolvidas abordagens como RAG e fluxos orientados por agentes. O RAG injeta informações contextuais de uma base de conhecimento durante a invocação do modelo, enquanto fluxos orientados por agentes tratam de análises de dados mais complexas e de orquestração. Com o RAG, informações contextuais de uma base de conhecimento são injetadas no prompt do modelo durante a invocação. A Bedrock oferece bases de conhecimento gerenciadas conectadas a fontes de dados como Amazon S3 e SharePoint, permitindo informações suplementares como planos de desenvolvimento urbano, relatórios de inteligência ou políticas/regulações para acompanhar as respostas geradas pela IA. Quando o modelo responde com dados provenientes do RAG, ele pode fornecer referências e citações às fontes. Em contextos geoespaciais, muitos dados são estruturados e residem em GIS; assim, ferramentas e agentes podem conectar diretamente o GIS ao LLM. Vários LLMs (por exemplo, Claude no Amazon Bedrock) permitem descrever ferramentas disponíveis, para que o modelo gere textos que invoquem processos externos, como obter clima atual de um local, consultar um data store estruturado, iniciar um fluxo de trabalho ou adicionar camadas ao mapa. Funcionalidades geoespaciais comuns que você pode integrar com o seu LLM via ferramentas incluem: recuperar dados geoespaciais, acionar fluxos de trabalho, desenhar marcadores na map, ou consultar informações em tempo real. As ferramentas costumam ser implementadas em AWS Lambda, que executa código sem a complexidade de gerenciar servidores. O Bedrock oferece o recurso Amazon Bedrock Agents para simplificar a orquestração e integração com suas ferramentas geoespaciais. Os agentes seguem instruções de raciocínio do LLM para dividir uma solicitação do usuário em tarefas menores e executar ações contra provedores de tarefas identificados. Diagramas no artigo ilustram como os Bedrock Agents podem aprimorar soluções GIS. O exemplo de demonstração utiliza um agente de terremotos com uma base de conhecimento baseada no Amazon Redshift. A instância do Redshift possui duas tabelas: terremotos (data, magnitude, latitude, longitude) e condados da Califórnia descritos como polígonos. As capacidades geoespaciais do Redshift podem relacionar esses conjuntos de dados para responder perguntas como qual condado teve o terremoto mais recente ou qual condado teve mais terremotos nos últimos 20 anos. O Bedrock agent pode gerar consultas geoespaciais com base em linguagem natural. Este pipeline end-to-end demonstra como o RAG e fluxos baseados em agentes podem manter a precisão dos dados enquanto conectam modelos de IA a bases de conhecimento estruturadas. Para implementar a abordagem, é necessário uma conta AWS com as permissões IAM adequadas para Amazon Bedrock, Amazon Redshift e Amazon S3. O artigo descreve etapas para configurar o AWS CLI, validar o ambiente, criar variáveis do Bedrock e do Redshift, configurar roles IAM para S3 e Redshift, preparar os dados e o armazenamento no S3, transformar dados geoespaciais, configurar o cluster Redshift, criar o esquema do banco de dados, criar uma base de conhecimento e, por fim, criar e configurar um agente. O texto enfatiza que o conteúdo inclui trechos de código para ilustrar as etapas, mas o foco é o fluxo de ponta a ponta: conectar raciocínio de IA a dados geoespaciais e bases organizacionais para fluxos GIS mais dinâmicos e contextuais. A integração de IA com GIS cria sistemas intuitivos para usuários de diferentes níveis técnicos realizarem análises espaciais complexas por meio de linguagem natural. Ao usar o RAG e fluxos orientados por agentes, as organizações podem manter a integridade dos dados ao conectar modelos de IA a bases de conhecimento e a sistemas de dados estruturados. O Bedrock facilita a convergência entre IA e tecnologia GIS, oferecendo uma plataforma robusta para invocação de modelos, recuperação de conhecimento e integração com infraestruturas existentes. Para detalhes e diagramas, consulte o post original no blog da AWS.
Novidades
| Aspecto | Descrição |
|---|---|
| RAG | Injeção dinâmica de contexto de uma base de conhecimento durante a invocação do modelo para respostas geoespaciais. |
| Fluxos orientados por agentes | Divide uma solicitação em tarefas menores e executa ações contra provedores de tarefas identificados para completar análises geoespaciais. |
| Bases de conhecimento | Conexões gerenciadas com fontes de dados como S3 e SharePoint permitem enriquecimento com documentos não estruturados e referências de políticas. |
| Ferramentas e orquestração | Ferramentas (frequentemente Lambda) permitem recuperação de dados ao vivo, interações com mapas ou controle de fluxos, coordenados pelos Bedrock Agents. |
| Exemplo de ponta a ponta | Um agente de análise de terremotos demonstra consultar dados do Redshift para produzir insights espaciais e mapas. |
Por que isso importa (impacto para desenvolvedores/empresas)
- Análise simplificada: a IA assistida por GIS reduz etapas manuais e facilita a exploração de dados espaciais.
- Tomada de decisão aprimorada: respostas com contexto ajudam no planejamento e interpretação de políticas com referências rastreáveis.
- Integração flexível: o Bedrock oferece um caminho único para hospedar modelos, gerenciar bases de conhecimento e conectar a fontes de dados existentes e fluxos de trabalho.
- Valor para diferentes funções: aproveita usuários técnicos, de negócios e liderança, entregando insights acessíveis e baseados em dados.
- Saídas auditáveis: com RAG, o sistema pode citar fontes; agentes executam tarefas que se conectam a dados ao vivo e ferramentas, reduzindo o risco de resultados desatualizados.
Detalhes técnicos ou Implementação (alto nível)
A abordagem combina modelos hospedados no Bedrock, recuperação de conhecimento com RAG e Bedrock Agents que orquestram tarefas contra fontes de dados e ferramentas externas.
Visão geral de arquitetura
- Fontes de dados: dados GIS armazenados em um banco de dados GIS estruturado (p. ex., Redshift com polígonos de condados) e datasets geoespaciais ao vivo.
- Modelos de IA: LLMs hospedados no Bedrock atuam como mecanismo de raciocínio e interface de linguagem natural.
- Camada de conhecimento: bases de conhecimento gerenciadas em S3 ou SharePoint fornecem documentos não estruturados e referências de políticas.
- Orquestração: Bedrock Agents traduzem intents do usuário em tarefas e chamam processos ou stores de dados externos (tipicamente funções Lambda).
- Ferramentas: processos externos recuperam dados em tempo real, interrogam stores geoespaciais ou modificam camadas GIS; essas ferramentas são invocadas pelo LLM via descrições de ferramentas.
Fontes de dados e armazenamento (exemplo)
- O exemplo de terremotos utiliza uma instância Redshift com duas tabelas: earthquakes (data, magnitude, latitude, longitude) e condados da Califórnia (polígonos). As capacidades geoespaciais do Redshift relacionam os conjuntos de dados para responder perguntas como qual condado teve o terremoto mais recente ou qual condado teve mais terremotos nos últimos 20 anos. O agente Bedrock pode gerar consultas geoespaciais em linguagem natural, com base nos dados do Redshift e no fluxo de trabalho do agente para realizar a análise.
- Bases de conhecimento no Bedrock podem conectar-se a fontes como S3 e SharePoint para fornecer informações suplementares, incluindo documentos de políticas, planos de desenvolvimento ou diretrizes regulatórias.
Fluxo de ponta a ponta (alto nível)
- Preparar permissões IAM para Bedrock, Redshift e S3.
- Configurar o ambiente AWS CLI e validar a configuração.
- Criar e inicializar variáveis do Bedrock e do Redshift, incluindo roles que concedem acesso aos dados.
- Preparar os dados geoespaciais e armazená-los no S3 para uso pelo fluxo de trabalho.
- Transformar formatos de dados geoespaciais conforme necessário para alinhar com as capacidades do Redshift.
- Configurar o cluster Redshift e criar o esquema do banco de dados relevante.
- Criar e carregar a base de conhecimento com documentos necessários para respostas baseadas em RAG.
- Criar e configurar um Bedrock Agent para interpretar intenções, recuperar informações de apoio, consultar os data stores e modificar GIS, se apropriado.
Exemplos de prompts e capacidades
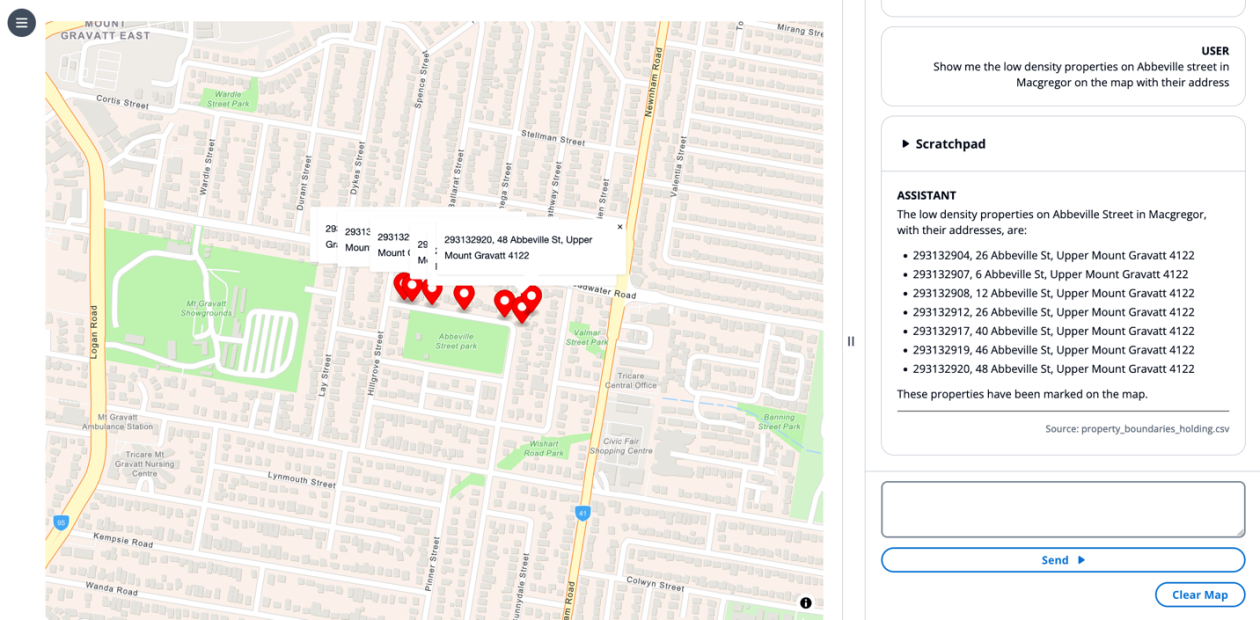
- O artigo demonstra prompts como: Resuma quais zonas permitem construção de um apartamento. Aqui o LLM utiliza recuperação com RAG para trazer informações de documentos de zoneamento como contexto, respondendo em linguagem natural. Outro exemplo solicita um relatório sobre como dados de habitação podem ser usados para planejar o desenvolvimento, com o LLM recuperando documentos de código de planejamento e gerando um relatório padronizado. Um terceiro exemplo solicita mostrar propriedades de baixa densidade em uma rua específica com marcadores no mapa, com o LLM acionando uma ferramenta de desenho. Por fim, um prompt pergunta se é possível construir um apartamento em um local específico; o estado do mapa e dados de políticas alimentam a resposta com justificativas.
- Os exemplos ilustram templates de prompts, RAG, sumarização, raciocínio em cadeia, uso de ferramentas e controle de interface de usuário. Eles também demonstram como um motor de estado pode repassar contexto da interface para o input do LLM, permitindo respostas mais precisas e com contexto.
Implementação e testes (alto nível)
- Após criar o agente, você pode testá-lo com entradas em linguagem natural e observar como o LLM utiliza o RAG para recuperar fontes e como o agente aciona ferramentas para gerar mapas, consultas ou relatórios.
- O artigo enfatiza a importância de testes de ponta a ponta e de limpeza de recursos para evitar cobranças indesejadas.
Considerações para practitioners
- Gerenciamento de IAM, governança de dados e controle de custos são cruciais ao implantar fluxos GIS baseados em Bedrock.
- O RAG melhora a precisão contextual ao referenciar bases de conhecimento; fluxos orientados por agentes tratam de tarefas multi-etapa e de orquestração entre bases de dados e ferramentas.
- A combinação de Bedrock, Redshift, S3 e Lambda permite pipelines de IA geoespacial de ponta a ponta que se integram aos sistemas GIS existentes e às políticas organizacionais.
Conclusões-chave
- Bedrock oferece uma plataforma abrangente para hospedar modelos, gerenciar bases de conhecimento e orquestrar fluxos GIS alimentados por IA.
- RAG e fluxos orientados por agentes permitem análises geoespaciais com contexto e automação de várias etapas envolvendo dados e ferramentas.
- Bases de conhecimento conectadas ao S3 e ao SharePoint ampliam as respostas da IA com documentos relevantes e políticas, enquanto os dados GIS armazenados no Redshift fornecem suporte a raciocínio espacial preciso.
- Bedrock Agents simplificam a orquestração do raciocínio de LLM com invocação de ferramentas em tempo real, promovendo experiências GIS interativas por meio da linguagem natural.
- O exemplo de Análise de Terremotos demonstra um pipeline completo que conecta raciocínio de IA com dados geoespaciais e stores de dados ao vivo, mantendo a precisão e a rastreabilidade.
FAQ
-
O que é um Bedrock Agent no contexto GIS?
Bedrock Agents são projetados para simplificar a orquestração e a integração, dividindo uma solicitação do usuário em tarefas menores e executando ações contra provedores de tarefas identificados.
-
Como o RAG ajuda em casos geoespaciais?
O RAG injeta contextualização de uma base de conhecimento durante a invocação do modelo, permitindo que a IA faça referência a fontes e forneça citações quando responde a perguntas espaciais.
-
Quais dados são usados no exemplo de terremotos?
O exemplo usa um conjunto de dados Redshift com a tabela earthquakes (data, magnitude, latitude, longitude) e a tabela de condados da Califórnia com polígonos. As capacidades geoespaciais do Redshift conectam os conjuntos de dados para responder perguntas sobre terremotos por região.
-
Quais configurações são necessárias para implementar essa abordagem?
Uma conta AWS com permissões IAM adequadas para Bedrock, Redshift e S3; configuração do AWS CLI; criação de variáveis do Bedrock e Redshift; preparação de dados; criação de uma base de conhecimento; criação e configuração de um agente.
Referências
More news

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Como reduzir gargalos do KV Cache com NVIDIA Dynamo
O Dynamo da NVIDIA transfere o KV Cache da memória da GPU para armazenamento de custo mais baixo, permitindo janelas de contexto maiores, maior concorrência e menor custo de inferência em grandes modelos.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.

Prompting para precisão com Stability AI Image Services no Amazon Bedrock
O Bedrock now oferece Stability AI Image Services com nove ferramentas para criar e editar imagens com maior precisão. Veja técnicas de prompting para uso empresarial.

Aumente a produção visual com Stability AI Image Services no Amazon Bedrock
Stability AI Image Services já estão disponíveis no Amazon Bedrock, oferecendo capacidades de edição de mídia prontas para uso via Bedrock API, ampliando os modelos Stable Diffusion 3.5 e Stable Image Core/Ultra já existentes no Bedrock.

Use AWS Deep Learning Containers com o SageMaker AI gerenciado MLflow
Explore como os AWS Deep Learning Containers (DLCs) se integram ao SageMaker AI gerenciado pelo MLflow para equilibrar controle de infraestrutura e governança robusta de ML. Um fluxo de trabalho de predição de idade de ostra com TensorFlow demonstra rastreamento de ponta a ponta, governança de model