Acelere o processamento inteligente de documentos com IA generativa na AWS
TL;DR
- A AWS apresenta o GenAI IDP Accelerator, uma solução de código aberto, sem servidor, que combina IA generativa com o Bedrock Data Automation e modelos de fundação para automatizar o processamento inteligente de documentos.
- O acelerador converte documentos não estruturados em dados estruturados, permitindo processamento escalável em diversos setores e reduzindo a entrada manual e erros.
- A implantação é facilitada por um template do AWS CloudFormation e por um fluxo de trabalho modular baseado em padrões, com entrega de resultados em dias, não meses.
- Casos reais incluem a Competiscan, que lida com dezenas de milhares de campanhas diárias, e a Ricoh, com transformação de documentos de saúde de alto volume e alta precisão.
- O projeto enfatiza um pipeline configurável, com prompts, templates de extração e regras de validação, tudo construído sobre serviços da AWS, com foco em segurança e custo-benefício.
Contexto e antecedentes
Todos os dias, organizações processam milhões de documentos, desde faturas e contratos até sinistros e prontuários médicos. Uma parcela significativa dos dados contidos nesses documentos é não estruturada, representando valor ainda não aproveitado que pode transformar resultados de negócios. A entrada manual de dados continua comum, pois PDFs, imagens digitalizadas e formulários costumam exigir intervenção humana. Essa abordagem é lenta, sujeita a erros e difícil de dimensionar conforme os volumes aumentam. O cenário de IDP (processamento inteligente de documentos) evoluiu com o surgimento de grandes modelos de linguagem (LLMs) e IA generativa. Modelos antigos baseados em templates e regras enfrentavam variações de documentos e layouts complexos. Hoje, modelos de IA podem compreender o contexto do documento, lidar com formatos diversos sem templates e alcançar alta precisão em extrações desafiadoras. Esse movimento permite processar vários tipos de documentos com menor tempo e custo de implementação. Nesse contexto, a AWS apresenta o GenAI IDP Accelerator como uma solução de código aberto, pronta para implantar e pronta para produção. O GenAI IDP Accelerator é uma solução serverless e modular, construída com serviços da AWS. Ela utiliza o Amazon Bedrock Data Automation para recursos de processamento de documentos prontos para uso e os modelos Bedrock para cenários que demandam lógica personalizada. O objetivo é oferecer um ponto de partida com qualidade empresarial que possa ser rapidamente adaptado a diferentes setores e tipos de documentos, mantendo segurança e escalabilidade. Para equipes técnicas, este projeto oferece um caminho concreto de transição de demonstração para uma solução de automação de documentos orientada a produção com IA generativa na AWS. A abordagem enfatiza manutenibilidade, controle de custos e uma arquitetura pronta para escalar. Fonte
O que há de novo
O GenAI IDP Accelerator é apresentado como uma solução de código aberto, pronta para implantação, que combina IA generativa com Bedrock Data Automation e modelos Bedrock. Pontos-chave:
- Uma base sem servidor com padrões de processamento baseados no Bedrock Data Automation, oferecendo recursos de processamento de documentos prontos para uso, alta precisão e precificação simples por página. Fonte
- Integração com os melhores modelos Bedrock (FMs) para lidar com documentos complexos que requerem lógica personalizada.
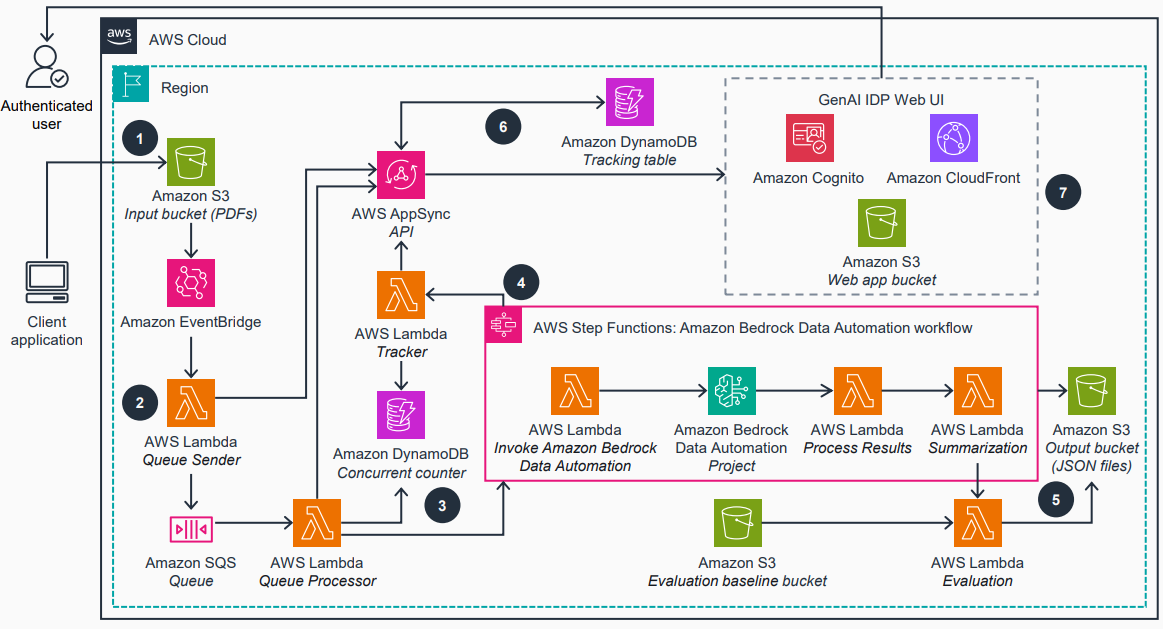
- Um pipeline modular que enriquece documentos em cada etapa—OCR, classificação, extração, avaliação, resumo e avaliação final—permitindo implantar e personalizar cada etapa de forma independente.
- Design orientado à configuração, tornando fácil ajustar prompts, templates de extração e regras de validação sem mexer na infraestrutura subjacente.
- Implantação via template do AWS CloudFormation; a implantação leva aproximadamente 15–20 minutos, após o que você recebe credenciais para acessar a interface web. Fonte
- Demonstração prática (Pattern-1) da fluxo padrão do Bedrock Data Automation e a possibilidade de acrescentar mais padrões conforme necessidades reais.
- Resultados reais de clientes mostrados no post, incluindo a Competiscan com alto volume de campanhas e a Ricoh com processamento de documentos de saúde. Fonte O projeto foi desenvolvido para ser compatível com o ecossistema, oferecendo um caminho escalável para que empresas automatizem fluxos de documentos, mantendo segurança e disciplina de custos.
Por que isso importa (impacto para desenvolvedores/empresas)
O GenAI IDP Accelerator responde a duas realidades persistentes no processamento de documentos: o volume de dados e a variação de formatos. Ao combinar IA generativa com uma pipeline sem servidor na AWS, a solução permite:
- Processar centenas a milhões de documentos com menos esforço manual, liberando insights de dados não estruturados com velocidade.
- Reduzir o tempo para ir à produção. Ao contrário de protótipos que costumam falhar em escala, o acelerador foca em robustez, tratamento de erros, escalabilidade e segurança empresarial.
- Manter flexibilidade e controle de custos. Um fluxo de trabalho modular baseado em padrões permite ajustar prompts, templates de extração e regras de validação, explorando também economia por página.
- Aproveitar a segurança, confiabilidade e ecossistema da AWS. Construído com serviços da AWS, a solução oferece escalabilidade e segurança de nível empresarial com opções de extensão para CDK ou Terraform no futuro. Fonte Para desenvolvedores e arquitetos, o acelerador oferece diretrizes concretas para transformar uma demonstração em uma solução de automação de documentos pronta para produção, capaz de lidar com diferentes tipos de documentos com alta precisão e escalabilidade. Fonte
Detalhes técnicos ou Implementação
O GenAI IDP Accelerator é apresentado como uma solução modular, sem servidor, construída sobre serviços da AWS. Elementos centrais:
- Um pipeline modular que enriquece documentos em cada etapa—OCR, classificação, extração, avaliação, resumo e avaliação final—permitindo implantar e personalizar etapas independentemente, mantendo o fluxo integrado. Esse design facilita adaptações a diferentes tipos de documentos.
- Utilização do Amazon Bedrock Data Automation para recursos de processamento de documentos prontos para uso, alta precisão e precificação simples por página. Para cenários mais complexos, modelos bedrock (FMs) fornecem lógica personalizada. Fonte
- Modelo de entrega aberto no GitHub, com capacidade de atualizar a pilha para a versão mais recente e de construir a partir do código-fonte, se for necessário personalizar mais ou implantar em outras regiões. O projeto adota uma abordagem orientada a configuração para prompts, templates de extração e regras de validação sem mexer na infraestrutura. Fonte
- Pattern-1 representa o fluxo de trabalho padrão do Bedrock Data Automation, e o post indica planos de adicionar mais padrões para cobrir necessidades reais. A arquitetura é ilustrada com o padrão padrão e as conexões entre os componentes na pilha da AWS. Fonte Detalhes de implantação e operação:
- Pré-requisitos: uma conta AWS com permissões de administrador e acesso aos modelos do Amazon Bedrock (incluindo modelos Anthropic, quando aplicável) no Bedrock. Consulte as diretrizes de acesso aos modelos. Fonte
- Implantação via AWS CloudFormation: o template provisiona os recursos necessários; após a implantação, você recebe um e-mail com as credenciais de acesso à interface web. A pilha leva cerca de 15–20 minutos para ficar pronta.
- Fluxo de produção: em produção, os documentos são enviados para um bucket S3 de entrada para acionar automaticamente o processamento. Há orientações para testar sem a interface e para atualizar a pilha para a versão mais recente. Fonte
- Extensibilidade: é possível construir a partir do código para suportar mais regiões ou alterações. Existem planos para suporte ao AWS CDK e Terraform no futuro. Acompanhe o repositório GitHub para atualizações e participe da comunidade para contribuir com melhorias. Fonte Casos de uso e resultados reais mencionados no artigo: Competiscan, que lida com um grande arquivo de campanhas diárias com histórico de 15 anos, e Ricoh, que transformou o processamento de documentos de saúde para clientes, com volumes mensais significativos. Fonte
Principais conclusões
- O GenAI IDP Accelerator oferece um caminho testado e orientado à produção para automatizar a transformação de documentos não estruturados com IA generativa na AWS.
- A solução é modular, sem servidor e configurável, permitindo ajustes rápidos a tipos de documentos e regras de negócio.
- Bedrock Data Automation cuida do processamento de documentos pronto para uso, enquanto Bedrock FMs fornecem lógica personalizada para cenários mais complexos.
- A implantação é simplificada por meio de um template do CloudFormation, com janela de provisionamento de 15–20 minutos e economia por página escalável.
- Casos reais de clientes destacam o potencial de substituir a entrada manual por extrações estruturadas com alta precisão em larga escala. Fonte
FAQ
-
O que é o GenAI IDP Accelerator?
é uma solução de código aberto, sem servidor, que combina IA generativa com Bedrock Data Automation e modelos Bedrock para automatizar o processamento inteligente de documentos em escala. [Fonte](https://aws.amazon.com/blogs/machine-learning/accelerate-intelligent-document-processing-with-generative-ai-on-aws/)
-
Como é a implantação?
A implantação ocorre via template do AWS CloudFormation, leva em média 15–20 minutos, e você recebe credenciais para a interface web. Os documentos são processados a partir de um bucket S3 de entrada. [Fonte](https://aws.amazon.com/blogs/machine-learning/accelerate-intelligent-document-processing-with-generative-ai-on-aws/)
-
Que tipos de documentos e padrões são suportados?
O pipeline modular trata diversos tipos de documentos por meio do fluxo de trabalho padrão do Bedrock Data Automation (Pattern-1) e há planos para adicionar padrões adicionais. Casos complexos podem usar a lógica personalizada dos FMs do Bedrock. [Fonte](https://aws.amazon.com/blogs/machine-learning/accelerate-intelligent-document-processing-with-generative-ai-on-aws/)
-
Quais são alguns casos de uso e benefícios?
A Competiscan lida com alto volume de campanhas diárias e um arquivo histórico considerável; a Ricoh processa documentos de saúde com volumes mensais expressivos, demonstrando aplicabilidade em ambientes de alto volume. [Fonte](https://aws.amazon.com/blogs/machine-learning/accelerate-intelligent-document-processing-with-generative-ai-on-aws/)
-
Onde posso aprender mais ou contribuir?
O projeto está no GitHub e é descrito no post da AWS; há oportunidades para atualizações e contribuições da comunidade. [Fonte](https://aws.amazon.com/blogs/machine-learning/accelerate-intelligent-document-processing-with-generative-ai-on-aws/)
Referências
More news

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.

Prompting para precisão com Stability AI Image Services no Amazon Bedrock
O Bedrock now oferece Stability AI Image Services com nove ferramentas para criar e editar imagens com maior precisão. Veja técnicas de prompting para uso empresarial.

Aumente a produção visual com Stability AI Image Services no Amazon Bedrock
Stability AI Image Services já estão disponíveis no Amazon Bedrock, oferecendo capacidades de edição de mídia prontas para uso via Bedrock API, ampliando os modelos Stable Diffusion 3.5 e Stable Image Core/Ultra já existentes no Bedrock.

Use AWS Deep Learning Containers com o SageMaker AI gerenciado MLflow
Explore como os AWS Deep Learning Containers (DLCs) se integram ao SageMaker AI gerenciado pelo MLflow para equilibrar controle de infraestrutura e governança robusta de ML. Um fluxo de trabalho de predição de idade de ostra com TensorFlow demonstra rastreamento de ponta a ponta, governança de model

Construir Fluxos de Trabalho Agenticos com GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore
Visão geral de ponta a ponta para implantar modelos GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore, alimentando um analisador de ações com múltiplos agentes usando LangGraph, incluindo quantização MXFP4 de 4 bits e orquestração serverless.