O 'Super Weight': Como um único parâmetro pode determinar o comportamento de um LLM
Sources: https://machinelearning.apple.com/research/the-super-weight
TL;DR
- Um conjunto extremamente pequeno de parâmetros de LLM, denominado de “super weights”, pode moldar desproporcionalmente o comportamento do modelo.
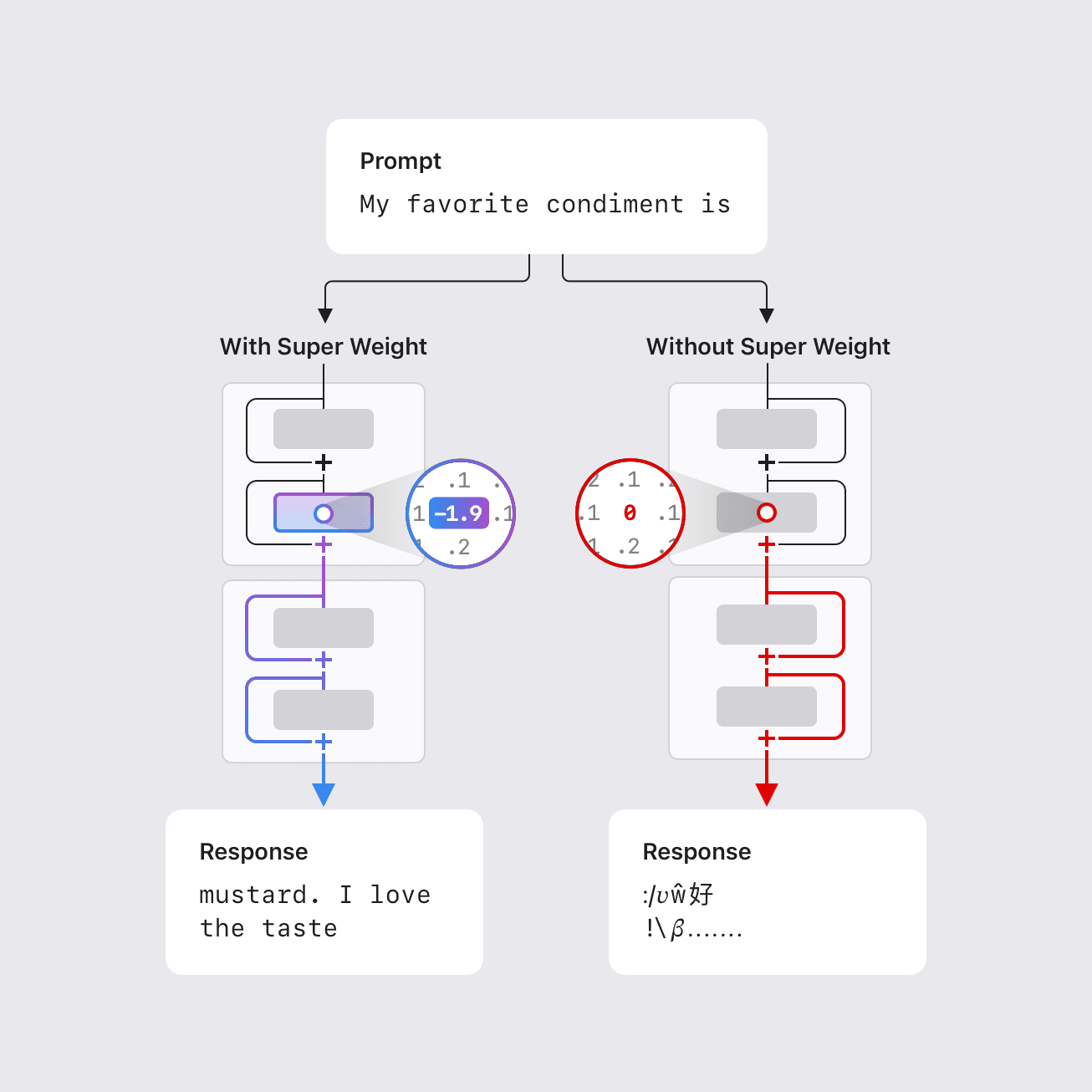
- Em alguns casos, remover apenas um super weight pode destruir a capacidade do modelo de gerar texto coerente, causando um aumento de três ordens de grandeza na perplexidade e reduzindo a exatidão de zero-shot a níveis de palpite aleatório.
- Super weights induzem ativações correspondentes, chamadas de “super activations”, que persistem entre camadas e influenciam as saídas do modelo de forma global; a remoção do peso suprime esse efeito.
- Um método de uma única passagem pode localizar esses pesos detectando outliers de ativação raros e de grande magnitude (super activations) que se alinham com o canal do super weight, tipicamente após o bloco de atenção na projeção descendente da rede feed-forward.
- Um índice de coordenadas de super weights foi compilado para vários LLMs abertos para apoiar pesquisas futuras; por exemplo, estão fornecidas coordenadas para o Llama-7B.\n
Contexto e antecedentes
Modelos de linguagem grande costumam ter bilhões ou centenas de bilhões de parâmetros, o que complica a implantação em hardware com recursos limitados, como dispositivos móveis. Reduzir tamanho e demanda computacional é essencial para uso local e privado sem acesso à internet. Pesquisas anteriores mostraram que uma fração pequena de outliers de peso pode ser vital para manter a qualidade do modelo; remover ou modificar significativamente esses pesos degrada a saída. Em trabalhos anteriores, essa fração podia ser tão pequena quanto 0,01% dos pesos — ainda assim dezenas de milhares de parâmetros em modelos muito grandes. O trabalho da Apple identifica um conjunto notavelmente pequeno de parâmetros, chamados de “super weights”, que podem destruir a capacidade de um LLM gerar texto coerente quando alterados. Por exemplo, no modelo Llama-7B, remover o seu único super weight impede o modelo de produzir saída significativa. Por outro lado, remover milhares de outliers de peso, mesmo com magnitude maior, resulta apenas em degradação modesta de qualidade. O estudo propõe uma metodologia para localizar esses super weights com uma única passagem para frente, usando a observação de que as super weights geram grandes ativações raras (super activations) que persistem nas camadas subsequentes com magnitude e posição constantes; o canal dessas ativações alinha-se com o da própria super weight. O trabalho também aponta que a super weight é consistentemente encontrada na projeção descendente da rede feed-forward após o bloco de atenção, geralmente em uma camada inicial. Um índice de coordenadas de super weights foi compilado para vários modelos abertos comuns para facilitar a investigação pela comunidade.\n
O que há de novo
Pesquisadores da Apple identificam um fenômeno até então pouco valorizado: um número muito pequeno de parâmetros pode ditar o comportamento de um LLM. As principais descobertas incluem:
- A existência de “super weights” cuja alteração pode degradar drasticamente a qualidade da geração de texto; em alguns casos, um único parâmetro é suficiente para interromper a função.
- O conceito de “super activations”: ativações grandes, raras, que surgem após o weight e persistem através das camadas com posição e magnitude estáveis, alinhadas ao canal da super weight.
- Uma abordagem prática de detecção que requer apenas uma passagem e identifica picos nas distribuições de ativação em componentes específicos, notadamente na projeção descendente do network after attentional block, para localizar a super weight e sua ativação correspondente.
- Padrões de localização são consistentes entre modelos: a super weight costuma ficar na projeção descendente após a atenção, em uma camada inicial.
- A Tabela 1 lista números de camada, tipos de camada e tipos de peso para vários modelos; um exemplo explícito é Llama-7B no HuggingFace: acesse a super weight usando layers[2].mlp.down_proj.weight[3968, 7003]. O estudo também fornece um índice de coordenadas para vários modelos para facilitar a verificação pela comunidade.\n
Por que isso importa
Compreender e identificar super weights tem implicações práticas para compressão:
- A preservação de super activations com alta precisão pode viabilizar compressão eficaz com quantização de aproximação simples, mantendo desempenho competitivo frente a técnicas mais avançadas.
- Para quantização de pesos, preservar o super weight enquanto se recorta outliers pode permitir tamanhos de blocos de quantização maiores ainda funcionais, levando a melhores razões de compressão.
- Essa abordagem direcionada oferece um caminho mais eficiente em hardware para rodar LLMs poderosos em dispositivos com recursos limitados, mantendo qualidade relativamente alta em comparação com estratégias de poda generalizadas.
- A descoberta também alimenta questões sobre o design e treinamento de modelos, sugerindo que alguns outliers podem moldar saídas semânticas e que sua preservação durante a compressão é crítica. O trabalho disponibiliza um diretório de super weights para incentivar investigação contínua.\n
Detalhes técnicos ou Implementação
Resumo dos pontos centrais:
- Super weights são um subconjunto extremamente pequeno de parâmetros com influência desproporcional sobre o comportamento do modelo.
- Super activations são ativações grandes, raras, que aparecem após o super weight e persistem nas camadas subsequentes mantendo posição e magnitude; alinham-se ao canal da super weight.
- O método de detecção proposto requer apenas uma passagem para frente e depende de picos nas distribuições de ativação em componentes como a projeção descendente da rede feed-forward após o bloco de atenção para localizar a super weight e sua ativação correspondente.
- Padrões de localização são robustos entre modelos: a super weight aparece na projeção descendente após a atenção, em uma camada inicial.\n | Modelo (exemplo) | Coordenada de peso super (amostra) |--- |--- |Llama-7B (HuggingFace) | layers[2].mlp.down_proj.weight[3968, 7003] |
Pontos-chave
- Um conjunto extremamente pequeno de parâmetros pode guiar o comportamento de um LLM, com remoção ou modificação que pode comprometer drasticamente o desempenho.
- Os conceitos de “super weights” e “super activations” fornecem uma nova perspectiva sobre a dinâmica interna dos LLMs e têm implicações práticas para compressão.
- Uma abordagem prática de uma única passagem permite localizar esses pesos por meio de picos de ativação, possibilitando preservação direcionada durante quantização e poda.
- O estudo disponibiliza um índice oficial de coordenadas para modelos bem conhecidos, facilitando validação e experimentação pela comunidade.\n
FAQ
-
O que são super weights?
São um conjunto extremamente pequeno de parâmetros que, se alterados, podem impactar drasticamente a capacidade do LLM de gerar texto coerente.
-
Como as super weights são encontradas?
Por meio de uma única passagem para frente, detectando outliers de ativação raros e de grande magnitude (super activations) que se alinham com o canal da super weight, tipicamente após a projeção descendente do bloco de atenção.
-
Por que isso importa para compressão?
Preservar as super activations com alta precisão facilita a quantização simples, mantendo qualidade, e a preservação da super weight pode permitir melhores taxas de compressão ao clipping de outros outliers.
-
Onde essas weights geralmente ficam?
Na projeção descendente da rede feed-forward após o bloco de atenção, geralmente em uma camada inicial; um exemplo de coordenada está disponível para o Llama-7B.
Referências
More news

Como reduzir gargalos do KV Cache com NVIDIA Dynamo
O Dynamo da NVIDIA transfere o KV Cache da memória da GPU para armazenamento de custo mais baixo, permitindo janelas de contexto maiores, maior concorrência e menor custo de inferência em grandes modelos.

Reduzindo a Latência de Cold Start para Inferência de LLM com NVIDIA Run:ai Model Streamer
Análise detalhada de como o NVIDIA Run:ai Model Streamer reduz o tempo de cold-start na inferência de LLMs ao transmitir pesos para a memória da GPU, com benchmarks em GP3, IO2 e S3.

Otimize o acesso a alterações de conteúdo ISO-rating com Verisk Rating Insights e Amazon Bedrock
Verisk Rating Insights, impulsionado pelo Amazon Bedrock, LLMs e RAG, oferece uma interface conversacional para acessar mudanças ERC ISO, reduzindo downloads manuais e aumentando a velocidade e a precisão das informações.

Como a msg otimizou a transformação de RH com Amazon Bedrock e msg.ProfileMap
Este post mostra como a msg automatizou a harmonização de dados para o msg.ProfileMap usando o Amazon Bedrock para alimentar fluxos de enriquecimento de dados alimentados por LLM, elevando a precisão na correspondência de conceitos de RH, reduzindo trabalho manual e alinhando-se ao EU AI Act e ao GD

Automatize pipelines RAG avançadas com SageMaker AI da AWS
Aperfeiçoe a experimentação até a produção para Retrieval Augmented Generation (RAG) com SageMaker AI, MLflow e Pipelines, promovendo fluxos reprodutíveis, escaláveis e com governança.

Implante Inferência de IA Escalável com NVIDIA NIM Operator 3.0.0
O NVIDIA NIM Operator 3.0.0 amplia a inferência de IA escalável no Kubernetes, permitindo implantações multi-LLM e multi-nó, integração com KServe e suporte a DRA em modo de tecnologia, com colaboração da Red Hat e NeMo Guardrails.