Infosys Topaz usa Amazon Bedrock para transformar operações do help desk técnico
TL;DR
- Infosys Topaz aproveita o Amazon Bedrock para sustentar um help desk técnico baseado em IA generativa para um grande fornecedor de energia. AWS blog
- O sistema ingere transcrições passadas e novas, constrói uma base de conhecimento e utiliza geração com recuperação (RAG) para fornecer resoluções, reduzindo o tempo de busca manual.
- Segurança de dados e controles de acesso contam com AWS IAM, KMS, Secrets Manager, TLS, CloudTrail e OpenSearch Serverless com controle de acesso baseado em funções.
- A arquitetura usa AWS Step Functions, Lambda, S3, DynamoDB e um frontend Streamlit para oferecer uma experiência em produção com rastreamento de tempo e métricas de QoS.
Contexto e antecedentes
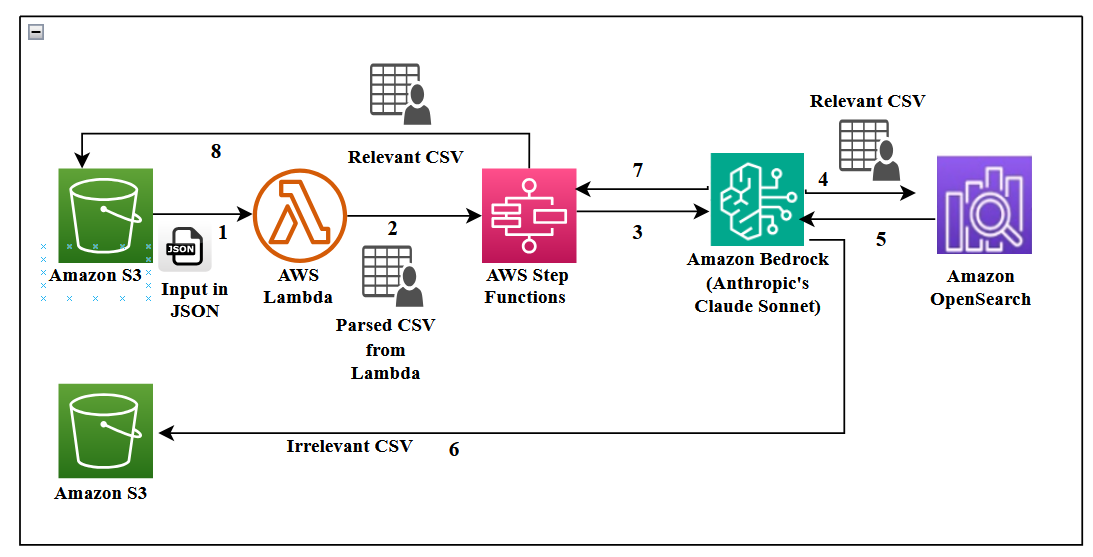
Um grande fornecedor de energia depende de um help desk técnico onde agentes atendem chamadas de clientes e assistem técnicos de campo que instalam, trocam, dão manutenção e reparam medidores. O volume é expressivo: cerca de 5.000 chamadas por semana (aproximadamente 20.000 por mês). Contratar mais agentes e treiná-los com o conhecimento necessário é dispendioso e difíceis de escalar. Para resolver isso, o Infosys Topaz se integra a capacidades do AWS Bedrock para criar um help desk impulsionado por IA que ingere transcrições, constrói uma base de conhecimento pesquisável e oferece resoluções aos agentes quase em tempo real. O objetivo é reduzir o tempo de atendimento, automatizar tarefas repetitivas e melhorar a qualidade do suporte. A arquitetura enfatiza uma integração estreita com serviços da AWS para fluxo de dados e governança dentro de um único ambiente em nuvem, incluindo Step Functions, DynamoDB e OpenSearch Service. AWS blog As conversas são gravadas para qualidade e análise. Transcrições são armazenadas em S3 no formato JSON e, em seguida, analisadas para criar uma base de conhecimento que a assistente de IA pode consultar. A solução destaca a importância do controle de acesso baseado em funções e do manuseio seguro de dados, especialmente PII. A arquitetura demonstra um fluxo de ponta a ponta desde transcrições brutas até uma UI interativa utilizada pelos agentes. A abordagem também cobre métricas como sentimento, tom e satisfação do usuário.
O que há de novo
A implementação combina Infosys Topaz com Amazon Bedrock, incluindo Claude Sonnet da Anthropic como LLM para sumarização e avaliação de contexto. Embeddings de texto Titan (Titan Text Embeddings) no Bedrock alimentam uma busca de vetor eficiente para o fluxo de Recuperação com Geração (RAG) por meio de um índice de OpenSearch Serverless. Principais escolhas de design incluem chunking de transcrições em blocos de 1.000 tokens com sobreposição de 150–200 tokens para melhorar a qualidade da recuperação. Um evento do AWS Lambda aciona o fluxo do Step Functions sempre que novas transcrições são carregadas no S3. As transcrições brutas são convertidas para CSV para filtragem (campos incluem ID de contato único, papel do falante e conteúdo da conversa). O pipeline ingere os CSVs via Step Functions para construir a base de conhecimento. Conversas irrelevantes são descartadas, enquanto as relevantes alimentam o processo de embeddings. Um elemento arquitetônico importante é o OpenSearch Serverless, que suporta armazenamento de vetores e busca em tempo quase real com embeddings atualizáveis. Um ambiente de produção com RAG depende de um armazenamento vetorial robusto e de modelos de embeddings adequados para recuperar informações contextualmente relevantes. Do ponto de vista de segurança, a solução utiliza AWS Secrets Manager para armazenar credenciais com rotação automática; S3 é criptografado com AES-256 via AWS KMS e a versioning está ativada para auditoria. Dados PII são criptografados e protegidos por políticas IAM e AWS KMS. Dados do OpenSearch Serverless são criptografados em repouso (KMS) e em trânsito (TLS 1.2). O gerenciamento de sessões inclui timeout para inatividade, exigindo reautenticação para retorno ao acesso. O sistema interage com dados ACL armazenados em DynamoDB por meio de uma camada de middleware segura, onde a tabela DynamoDB armazena IDs de usuário, seus papéis e os conteúdos permitidos por coleção OpenSearch. A implementação de RBAC usa três personas: administrador (acesso total), analista técnico de mesa (acesso médio) e agente técnico (acesso mínimo). OpenSearch Serverless utiliza coleções distintas para gerenciar diferentes níveis de acesso. A UI foi construída com Streamlit, oferecendo uma seção de FAQ no topo e uma seção de métricas de pesquisa na barra lateral. A autenticação via authenticate.login fornece o ID do usuário, e st.cache_data() armazena resultados em memória entre as sessões para melhoria de desempenho.
Por que isso importa (impacto para desenvolvedores/empresas)
Esta implementação mostra como operacionalizar uma solução de IA generativa que complementa agentes humanos, em vez de substituí-los. Construindo uma base de conhecimento a partir de transcrições reais e usando uma busca vetorial robusta (RAG), organizações podem reduzir o tempo de atendimento, padronizar resoluções e escalar o suporte sem ampliar proporcionalmente a equipe. A arquitetura demonstra como o Bedrock se integra aos serviços principais da AWS para entrega de fluxo de dados completo, governança segura de dados e auditoria. Para empresas, este padrão oferece passos práticos para implantar assistentes corporativos de IA em atendimento ao cliente, CRM e help desks, mantendo conformidade e padrões de segurança.
Detalhes técnicos ou Implementação
O fluxo começa com transcrições de chamadas gravadas por agentes e técnicos de campo. Transcrições são armazenadas no S3 em formato JSON e, em seguida, analisadas para gerar um CSV com campos estruturados: ID de contato, falante e conteúdo da conversa. O Step Functions orquestra o fluxo de ingestão de dados que transforma transcrições brutas em uma base de conhecimento pronta para uso. A camada de embeddings e recuperação utiliza Titan Text Embeddings para vetorização de texto e OpenSearch Serverless para armazenamento de vetores e busca, permitindo Geração com Recuperação (RAG) com Claude Sonnet no Bedrock para resumir conversas e identificar informações relevantes. A estratégia de chunking inclui blocos de 1.000 tokens com sobreposição de 150–200 tokens, combinada à recuperação por janela de frases para melhorar a qualidade da recuperação sem processar documentos extensos de uma vez. A UI utiliza Streamlit como framework frontend, com uma autenticação simples (authenticate.login) para atribuir IDs de usuário. A interface apresenta uma seção de FAQ e um painel de métricas com sentimento, tom e percentuais de satisfação. Os resultados são cacheados via st.cache_data() para acelerar respostas entre sessões. Do ponto de vista de segurança, a solução depende de AWS Secrets Manager para credenciais, KMS para criptografia em repouso, TLS 1.2 para dados em trânsito e CloudTrail para auditoria. O acesso é controlado por políticas IAM e por uma definição detalhada de RBAC com coleções segmentadas no OpenSearch Serverless. Três personas definem níveis de acesso: administrador, analista técnico de mesa e agente técnico. Essa abordagem de RBAC é sustentada por mapeamento de usuários/roles no DynamoDB e pela verificação de permissões por coleção no OpenSearch. Este padrão mostra como combinar caching dinâmico, FAQ relevante e uma interface de usuário clara para melhorar a experiência de agentes e usuários finais.
Principais conclusões
- IA aplicada a help desks é viável quando suportada por ingestão de dados sólida e pela recuperação baseada em contexto.
- Claude Sonnet no Bedrock e Titan Embeddings habilitam recuperação contextual efetiva sobre transcrições operacionais.
- Segurança, criptografia e governança auditável são essenciais para lidar com dados de clientes e PII em aplicações corporativas de IA.
- Uma arquitetura que usa Step Functions, Lambda, S3 e OpenSearch Serverless oferece escalabilidade para produção.
- RBAC com três personas assegura que dados sensíveis fiquem protegidos enquanto viabiliza fluxos de suporte eficientes.
FAQ
-
Qual problema esta solução busca resolver?
Reduzir o tempo de atendimento e automatizar tarefas repetitivas construindo uma base de conhecimento a partir de transcrições e fornecendo resoluções contextuais aos agentes.
-
Quais componentes de IA são usados?
Claude Sonnet da Anthropic no Bedrock para sumarização e análise de contexto, e Titan Text Embeddings no Bedrock para busca vetorial e recuperação com geração (RAG).
-
Como é garantida a segurança dos dados?
Dados são criptografados em repouso com KMS e em trânsito com TLS 1.2; Secrets Manager protege credenciais; acesso é controlado por políticas IAM e RBAC com coleções no OpenSearch Serverless e auditoria via CloudTrail.
-
Como é implementado o controle de acesso?
Três personas definem níveis de acesso (administrador, analista técnico de mesa, agente técnico), com permissões por coleção e mapeamento de usuários/roles no DynamoDB.
References
More news

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.

Prompting para precisão com Stability AI Image Services no Amazon Bedrock
O Bedrock now oferece Stability AI Image Services com nove ferramentas para criar e editar imagens com maior precisão. Veja técnicas de prompting para uso empresarial.

Aumente a produção visual com Stability AI Image Services no Amazon Bedrock
Stability AI Image Services já estão disponíveis no Amazon Bedrock, oferecendo capacidades de edição de mídia prontas para uso via Bedrock API, ampliando os modelos Stable Diffusion 3.5 e Stable Image Core/Ultra já existentes no Bedrock.

Use AWS Deep Learning Containers com o SageMaker AI gerenciado MLflow
Explore como os AWS Deep Learning Containers (DLCs) se integram ao SageMaker AI gerenciado pelo MLflow para equilibrar controle de infraestrutura e governança robusta de ML. Um fluxo de trabalho de predição de idade de ostra com TensorFlow demonstra rastreamento de ponta a ponta, governança de model

Construir Fluxos de Trabalho Agenticos com GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore
Visão geral de ponta a ponta para implantar modelos GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore, alimentando um analisador de ações com múltiplos agentes usando LangGraph, incluindo quantização MXFP4 de 4 bits e orquestração serverless.