Otimização dos endpoints de modelos da Salesforce com componentes de inferência do SageMaker AI
Sources: https://aws.amazon.com/blogs/machine-learning/optimizing-salesforces-model-endpoints-with-amazon-sagemaker-ai-inference-components, aws.amazon.com
TL;DR
- A Salesforce utilizou componentes de inferência do SageMaker AI para implantar vários modelos base em um único endpoint, com controle de recursos por modelo (aceleradores e memória), permitindo compartilhamento eficiente de GPU.
- A abordagem aumentou a utilização de GPUs e a eficiência de recursos, gerando economias substanciais de custo—reduções de até oito vezes nos custos de implantação e infraestrutura.
- A solução combina componentes de inferência com endpoints tradicionais (SMEs) em um modelo de hospedagem híbrido, permitindo escalonamento independente por modelo e otimização para padrões de tráfego.
- Ao atribuir recursos específicos de cada modelo (aceleradores, memória) e políticas de escalonamento por modelo, a Salesforce reduziu o superdimensionamento e melhorou o desempenho durante picos de tráfego.
- O projeto destaca o conjunto CodeGen (Inline para conclusão de código, BlockGen para blocos de código, FlowGPT para fluxos de processos) utilizado no ApexGuru, hospedado no SageMaker AI.”
Contexto e antecedentes
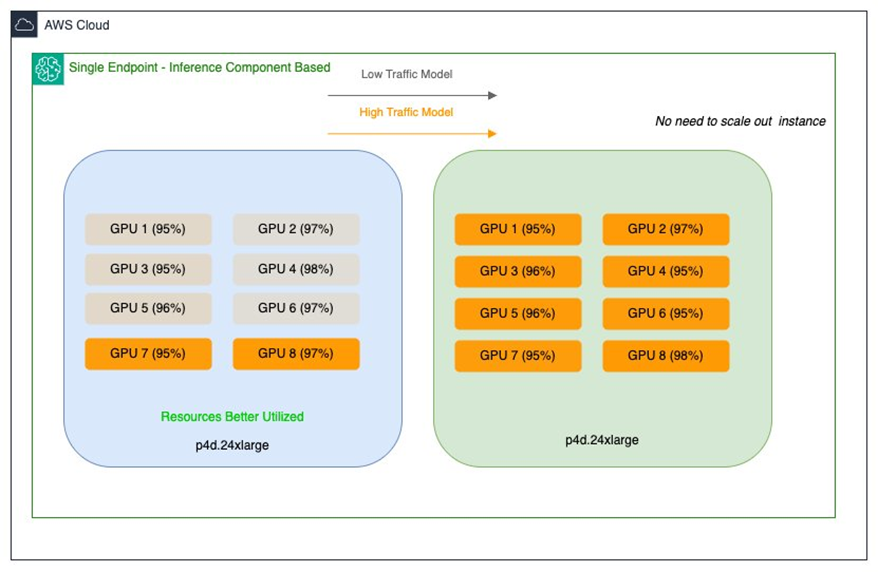
A equipe da Salesforce AI Platform Model Serving é responsável por desenvolver e gerenciar serviços que alimentam grandes modelos de linguagem (LLMs) e outras cargas de trabalho de IA dentro da Salesforce. O foco principal é a integração de modelos, fornecendo infraestrutura robusta para hospedar uma variedade de modelos de ML. A Salesforce opera modelos proprietários como CodeGen e XGen no SageMaker AI e os otimiza para inferência. Hoje, eles distribuem vários modelos entre SMEs com tamanhos que variam de alguns GB a cerca de 30 GB, cada um com requisitos de desempenho e infraestrutura distintos. Duas dificuldades de otimização surgiram: modelos maiores (20–30 GB) com tráfego baixo acabavam consumindo GPUs de alto desempenho, levando à subutilização de instâncias multi-GPU. Por outro lado, modelos médios (≈15 GB) com cargas de trabalho de alto tráfego exigiam baixa latência e alta taxa de transferência, o que poderia levar a custos maiores devido ao superdimensionamento. A Salesforce opera com instâncias EC2 P4d hoje e planeja migrar para as mais recentes P5en com GPUs NVIDIA H200, buscando uma estratégia de recursos mais eficiente que maximize a utilização de GPUs sem comprometer desempenho ou custos. Para enfrentar esses desafios, a equipe da Salesforce AI Platform adotou os componentes de inferência do SageMaker AI. Essa abordagem permite implantar vários modelos de base em um único endpoint do SageMaker AI e oferece controle granular sobre o número de aceleradores e a memória reservada para cada modelo. Um componente de inferência é configurado com artefatos de modelo, imagem de contêiner, número de cópias do modelo, além de definir políticas de escalonamento por modelo. O SageMaker AI gerencia o posicionamento para otimizar a disponibilidade e o custo. A Salesforce também utilizou uma abordagem híbrida, aproveitando as forças de cada solução para equilibrar estabilidade e escalabilidade. No contexto, a Salesforce utiliza o CodeGen em conjunto com o ApexGuru, com variantes como Inline, BlockGen e FlowGPT. Esses modelos, originalmente distribuídos em várias SMEs, passaram a compartilhar recursos de GPU de forma eficiente no mesmo endpoint, reduzindo overhead operacional e a quantidade de endpoints necessários.
O que há de novo
- Introdução dos componentes de inferência do SageMaker AI para hospedar um ou mais modelos de base em um único endpoint, com controle de recursos por modelo (aceleradores, memória, artefatos, imagem de contêiner e cópias).
- Políticas de escalonamento por modelo permitem que cada FM se ajuste a padrões de uso distintos, mantendo os custos sob controle.
- Auto scaling no nível do endpoint, com o SageMaker AI empacotando e dimensionando recursos com base no número de componentes de inferência carregados para servir o tráfego.
- Abordagem híbrida que combina SMEs para workloads estáveis com componentes de inferência para workloads variáveis, com compartilhamento de GPU e escalonamento dinâmico.
- Demonstração de economias de custo significativas (até oito vezes) na implantação e infraestrutura, mantendo alto desempenho em workloads diversos.
- A estratégia facilita a hospedagem de várias variantes de modelos no mesmo endpoint, como demonstrado com o CodeGen nas implementações do ApexGuru.
Por que isso importa (impacto para desenvolvedores/empresas)
Para desenvolvedores, a capacidade de executar vários modelos em um endpoint com controle fino de recursos facilita a implantação e o ciclo de vida dos modelos. Cada modelo pode ter seu próprio número de aceleradores e memória, além de cópias e políticas de escalonamento específicas, permitindo desempenho previsível para workloads críticas e flexibilidade para demandas variáveis. Para empresas, a abordagem traz ganhos econômicos significativos: melhor empacotamento de GPUs e alocação dinâmica de recursos reduzem subutilização de hardware e superdimensionamento, resultando em economias de custo sem comprometer a latência ou o throughput. A estratégia híbrida aproveita as vantagens tanto dos SMEs (hospedagem dedicada para workloads estáveis) quanto dos componentes de inferência (captura dinâmica de recursos e compartilhamento de GPUs), possibilitando operações de IA escaláveis que se adaptam a portfolios de modelos em evolução e padrões de tráfego. Os resultados da Salesforce demonstram como empacotamento inteligente de modelos e escalonamento por modelo podem transformar a economia de desempenho, permitindo o uso mais eficiente de GPUs caras em ambientes com cargas variadas.
Detalhes técnicos ou Implementação
Componentes de inferência: como funcionam
Um componente de inferência abstrai modelos de ML e permite atribuir CPUs, GPUs e políticas de escalonamento por modelo. Você cria o endpoint do SageMaker AI com o tipo de instância e a contagem inicial, em seguida acopla pacotes de modelo dinamicamente, configurando cada modelo como seu próprio componente de inferência. Para cada FM, você especifica o número de aceleradores e a quantidade de memória alocada para cada cópia, além dos artefatos do modelo, imagem de contêiner e o número de cópias a serem implantadas. Conforme as solicitações de inferência aumentam ou diminuem, o número de cópias de cada componente pode escalar com base nas políticas configuradas. O SageMaker AI cuida do posicionamento para otimizar o empacotamento de disponibilidade e custo. Se a escalabilidade automática de instâncias gerenciadas estiver habilitada, o SageMaker AI escala as instâncias de computação conforme a necessidade de carregar o número de componentes de inferência para atender o tráfego. Isso permite que cada modelo varie para cima ou para baixo dentro de um endpoint compartilhado mantendo o desempenho.
Hospedagem híbrida: SMEs + inferência
A Salesforce introduziu endpoints de componentes de inferência junto aos SMEs existentes para ampliar as opções de hospedagem sem comprometer a estabilidade, desempenho ou usabilidade. SMEs fornecem hospedagem dedicada para cada modelo e desempenho previsível para cargas estáticas, enquanto os componentes de inferência otimizam a utilização de recursos para workloads variáveis por meio de escalonamento dinâmico e compartilhamento de GPUs. Essa abordagem híbrida permite que as equipes aproveitem as forças de ambas as soluções.
Configuração de modelos e implantação
A equipe da Salesforce começa criando um endpoint do SageMaker AI com o tipo de instância base e a contagem inicial para atender às necessidades de inferência. Pacotes de modelo são anexados dinamicamente, iniciando contêineres individuais conforme necessário. Cada modelo, como BlockGen ou TextEval, é configurado como um componente de inferência separado, com alocações de recursos precisas (número de aceleradores, memória, artefatos, imagem de contêiner e número de cópias). Essa configuração permite hospedar várias variantes de modelos no mesmo endpoint mantendo controle granular sobre recursos e comportamento de escalonamento. Com escalonamento automático habilitado, os componentes de inferência podem ajustar automaticamente os recursos de GPU em resposta a variações de tráfego, permitindo que cada modelo escale de forma independente dentro do endpoint compartilhado. Essa abordagem reduz o impacto de picos de tráfego e garante alto throughput para workloads de pico, sem desperdiçar recursos quando a demanda diminui.
CodeGen e ApexGuru
O CodeGen da Salesforce, com seus componentes Inline, BlockGen e FlowGPT, foi implantado no ambiente híbrido (SMEs e componentes de inferência) e ajustado para o Apex. Esses modelos ajudam na compreensão e geração de código, além de fluxos de processo, demonstrando como variantes de modelos podem compartilhar um endpoint com controle de recursos por modelo, mantendo desempenho e custo sob controle.
Configuração de endpoint e eficiência de custo
A Salesforce configurou um endpoint do SageMaker AI com o tipo de instância base desejado e a contagem inicial, após o que os pacotes de modelo foram anexados para criar cópias por modelo conforme necessário. As capacidades de escalonamento automático permitem que o número de cópias cresça ou encolha com o tráfego, e o SageMaker AI realiza o empacotamento para otimizar custo e disponibilidade. O resultado é um caminho econômico para executar GPUs mais caras em workloads variadas, compartilhando-as entre modelos ao invés de dedicá-las a cada um.
Linhas-chave
- Componentes de inferência permitem hospedagem multi-modelo em um único endpoint com definições de recursos e políticas de escalonamento por modelo.
- O modelo híbrido (SMEs + inferência) oferece previsibilidade e eficiência de custo para workloads estáveis e variáveis.
- Controle fino de recursos (aceleradores, memória e cópias) por modelo melhora a utilização e reduz superdimensionamento.
- Escalonamento automático, aliado a empacotamento inteligente, otimiza o uso de GPUs e pode reduzir fortemente os custos de implantação e infraestrutura.
- A abordagem suporta portfolios de modelos complexos (por exemplo, ensembles CodeGen) mantendo desempenho e throughput.
Perguntas frequentes
-
Que problema a Salesforce procurou resolver com os componentes de inferência do SageMaker AI?
Maximizar a utilização de GPUs, melhorar a eficiência de recursos e reduzir custos de implantação e infraestrutura entre um portfólio de modelos em endpoints compartilhados.
-
Como os componentes de inferência diferem dos SMEs?
Componentes de inferência permitem hospedar vários modelos no mesmo endpoint com recursos e escalonamento por modelo, possibilitando compartilhamento de GPU; SMEs fornecem hospedagem dedicada para cada modelo com desempenho previsível.
-
Como funciona o escalonamento automático com componentes de inferência?
O SageMaker AI pode escalar as instâncias computacionais com base no número de componentes de inferência carregados; cada componente pode escalar suas cópias conforme o tráfego por modelo.
-
uais modelos da Salesforce são mencionados nessa abordagem?
O código CodeGen, com os ensembles Inline, BlockGen e FlowGPT, utilizados no ApexGuru, implantados via SMEs e componentes de inferência no SageMaker AI.
Referências
More news

NVIDIA HGX B200 reduz a Intensidade de Emissões de Carbono Incorporado
O HGX B200 da NVIDIA reduz 24% da intensidade de carbono incorporado em relação ao HGX H100, ao mesmo tempo em que aumenta o desempenho de IA e a eficiência energética. Esta análise resume os dados de PCF e as novidades de hardware.

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Playbook dos Grandmasters do Kaggle: 7 Técnicas de Modelagem Testadas para Dados Tabulares
Análise detalhada de sete técnicas testadas por Grandmasters do Kaggle para resolver grandes conjuntos de dados tabulares com aceleração por GPU, desde baselines diversificados até ensemble avançado e pseudo-rotulagem.

Como reduzir gargalos do KV Cache com NVIDIA Dynamo
O Dynamo da NVIDIA transfere o KV Cache da memória da GPU para armazenamento de custo mais baixo, permitindo janelas de contexto maiores, maior concorrência e menor custo de inferência em grandes modelos.

Microsoft transforma site da Foxconn no data center Fairwater AI, considerado o mais poderoso do mundo
A Microsoft divulga planos para um data center Fairwater AI de 1,2 milhão de pés quadrados no Wisconsin, com centenas de milhares de GPUs Nvidia GB200. projeto de US$ 3,3 bilhões promete treinamento de IA em escala sem precedentes.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.