Processamento inteligente de documentos escalável com Amazon Bedrock Data Automation
Sources: https://aws.amazon.com/blogs/machine-learning/scalable-intelligent-document-processing-using-amazon-bedrock-data-automation, aws.amazon.com
TL;DR
- O Bedrock Data Automation introduz pontuação de confiança, dados de bounding box, classificação automática e desenvolvimento rápido baseado em blueprints para IDP.
- Possibilita uma arquitetura totalmente sem servidor que utiliza Bedrock Data Automation com AWS Step Functions e Amazon A2I para escalar cargas de trabalho variáveis.
- O fluxo de trabalho suporta processar vários tipos de documentos em um único projeto e utiliza normalização de dados e validações para garantir saídas consistentes.
- A revisão humana com A2I ajuda a manter a precisão para extrações de baixa confiança, mantendo a automação ponta a ponta com saídas em S3.
Contexto e pano de fundo
Intelligent document processing (IDP) automatiza a extração, análise e interpretação de informações críticas a partir de documentos. Aplicando aprendizado de máquina avançado e processamento de linguagem natural, soluções de IDP convertem texto não estruturado em dados estruturados, otimizando fluxos de documentos. Quando aprimorado com capacidades de IA generativa, o IDP permite uma compreensão mais profunda, extração de dados mais robusta e classificação automática. Essa tecnologia tem impacto em setores como serviços de apoio à criança, seguros, saúde, serviços financeiros e setor público. Processos manuais tradicionais criam gargalos e aumentam o risco de erro; IDP com IA reduz a carga administrativa e melhora a entrega de serviços. Empresas que adotam IDP com IA geram ganhos de eficiência, melhores experiencias para clientes e crescimento acelerado. Em um post anterior do AWS Machine Learning Blog, demonstramos um pipeline de IDP escalável usando modelos da Anthropic no Bedrock. A Bedrock Data Automation traz novos níveis de eficiência e flexibilidade para soluções de IDP, e este post explora suas capacidades e como acelerar a jornada de automação. Veja o post original para contexto: AWS blog.
O que há de novo
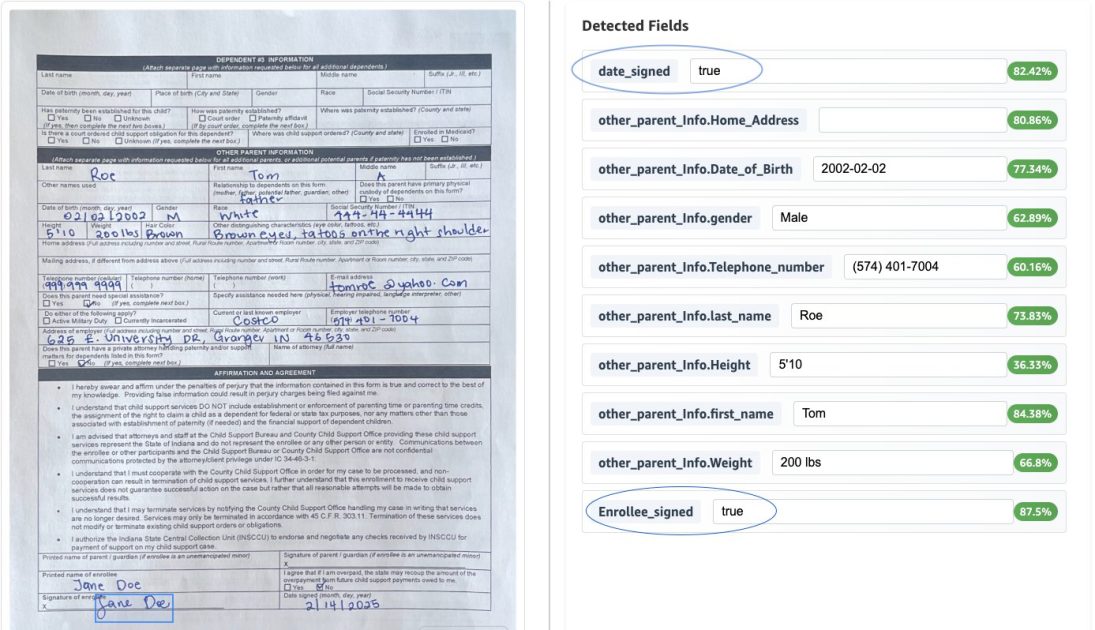
O Bedrock Data Automation introduz diversos recursos que melhoram significativamente a escalabilidade e a precisão de soluções de IDP: pontuação de confiança, dados de bounding box, classificação automática e desenvolvimento rápido por meio de blueprints. A solução pode ser implantada em uma arquitetura totalmente sem servidor que utiliza Bedrock Data Automation, AWS Step Functions e Amazon A2I para dimensionar cargas de trabalho de diferentes tamanhos. O fluxo Step Functions processa vários tipos de documentos, incluindo PDFs com várias páginas e imagens, usando blueprints do Bedrock Data Automation (padrão e personalizados) dentro de um único projeto para permitir o processamento de documentos diversos, como documentos de imunização, certificados de imposto de transferência, formulários de inscrição para apoio infantil e carteiras de motorista. O fluxo de trabalho processa um arquivo contendo um único documento ou vários documentos através das seguintes etapas: o estado Map do Step Functions processa cada documento. Se o documento atender ao limiar de confiança, o output é gravado em um bucket S3. Se algum dado extraído não atingir o limiar, o documento é encaminhado ao Amazon A2I para revisão humana. Revisores utilizam a interface do A2I com destaques de bounding box para verificar os resultados. Quando a revisão humana é concluída, o token de callback reabre a máquina de estados e os dados revisados ficam em S3. Para implantar a solução em uma conta AWS, siga os passos fornecidos no repositório GitHub acompanhante. No caso de uso de um formulário de inscrição para apoio infantil, definimos um nome de classe de documento para cada blueprint personalizado criado. Ao processar vários tipos de documentos, o sistema aplica automaticamente o blueprint apropriado com base na análise de conteúdo, assegurando a lógica de extração correta. Usamos normalização de dados para garantir que os sistemas downstream recebam dados padronizados. Tanto extrações explícitas (informação claramente visível no documento) quanto extrações implícitas (informação que requer transformação) são suportadas. Por exemplo, datas de nascimento são padronizadas para YYYY-MM-DD e números de Seguro Social são formatados como XXX-XX-XXXX. No formulário de inscrição para apoio infantil, implementamos transformações de dados personalizadas para alinhar os dados extraídos a requisitos específicos, incluindo um tipo de endereço personalizado que divide endereços em uma linha em campos estruturados (Rua, Cidade, Estado, CEP). Esses campos são reutilizados entre diferentes endereços (endereço do empregador, endereço residencial, endereço do outro responsável) para garantir consistência e facilitar a integração. As validações ajudam a manter a qualidade dos dados, incluindo a verificação da assinatura do beneficiário e de que a data de assinatura não está no futuro. Os resultados da extração contêm uma pontuação de confiança e dados de bounding box, integrados a um fluxo com revisão humana. Também é exibida a normalização aplicada à data de nascimento. O Bedrock Data Automation avança o IDP ao introduzir pontuação de confiança, dados de bounding box, classificação automática e desenvolvimento rápido por meio de blueprints. Atualizar para Bedrock Data Automation ajuda a reduzir o tempo de desenvolvimento, melhorar a qualidade dos dados e criar soluções de IDP mais robustas e escaláveis que se integram a processos de revisão humana. Siga o AWS Machine Learning Blog para ficar atualizado sobre capacidades e casos de uso do Bedrock. AWS blog.
Por que isso importa (impacto para desenvolvedores/empresas)
Para desenvolvedores e empresas, o Bedrock Data Automation reduz a barreira para construir pipelines de IDP escaláveis, oferecendo recursos avançados que antes exigiam customização extensa. A pontuação de confiança e os metadados de bounding box aumentam a confiabilidade dos dados extraídos, enquanto a classificação automática acelera o roteamento entre tipos de documentos. O modelo de desenvolvimento baseado em blueprints acelera a entrega, reduz o tempo até o valor e permite que as equipes façam iterações rápidas. A opção de revisão humana com o A2I garante alta precisão para extrações complexas ou com baixa confiança, mantendo fluxos automáticos de ponta a ponta com saída para S3 e resultados rastreáveis. Essa combinação suporta uma ampla gama de casos de uso, desde serviços governamentais até saúde, seguros e serviços financeiros, ajudando organizações a oferecer melhores experiências aos clientes, reduzir custos operacionais e escalar operações intensivas em documentos.
Detalhes técnicos ou Implementação
A solução foi desenhada como um pipeline totalmente sem servidor que utiliza Bedrock Data Automation com AWS Step Functions e Amazon A2I em um único projeto capaz de processar múltiplos tipos de documentos. Suporta formatos como PDF, JPG, PNG, TIFF, DOC e DOCX. O estado Map do Step Functions processa cada documento em um arquivo que pode conter um único documento ou vários. Se o documento atender ao limiar de confiança, seu output é salvo em um bucket S3; caso contrário, é encaminhado ao A2I para revisão humana. Após a conclusão da revisão, o estado é retomado via token de callback e os dados finalizados vão para o S3. O sistema define um nome de classe de documento para cada blueprint personalizado, permitindo comutação baseada no conteúdo entre tipos de documentos, como carteiras de motorista e formulários de inscrição para apoio infantil. A normalização de dados padroniza campos como a data de nascimento e os formatos de SSN, e extrações explícitas juntamente com transformações implícitas são suportadas. Um exemplo notável é um tipo de dados de endereço personalizado que mapeia endereços em uma linha para campos estruturados (Rua, Cidade, Estado, CEP) e garante formatação consistente entre campos relacionados. Validações ajudam a manter a qualidade dos dados, incluindo a verificação da assinatura do beneficiário e a garantia de que a data de assinatura não esteja no futuro. A arquitetura geral, incluindo dados de bounding box, pontuação de confiança, classificação automática e desenvolvimento rápido de blueprints, oferece IDP escalável e preciso com revisão humana integrada e saídas auditáveis. A implantação é orientada pelo repositório GitHub acompanhante. Os componentes-chave são ilustrados pelo exemplo do formulário de inscrição para apoio infantil e demonstram a seleção automática de blueprints com base no conteúdo.
Principais aprendizados
- Bedrock Data Automation introduz pontuação de confiança, dados de bounding box, classificação automática e desenvolvimento rápido baseado em blueprints para IDP.
- Permite uma arquitetura totalmente sem servidor usando Bedrock Data Automation, AWS Step Functions e Amazon A2I para dimensionar cargas de trabalho variáveis.
- O fluxo suporta múltiplos tipos de documentos em um único projeto e utiliza normalização de dados e validações para garantir saídas consistentes.
- A revisão humana via A2I ajuda a manter a precisão para documentos Complexos, permitindo automação de ponta a ponta.
- A solução padroniza formatos (datas, SSNs) e fornece campos estruturados para endereços, facilitando a integração com sistemas downstream.
FAQ
-
O que é Bedrock Data Automation e como ele se relaciona com IDP?
É um conjunto de recursos para aprimorar o processamento inteligente de documentos, adicionando pontuação de confiança, dados de bounding box, classificação e desenvolvimento rápido orientado por blueprints.
-
Como funciona o processo de revisão humana?
Documentos abaixo do limiar de confiança são enviados ao Amazon A2I para revisão por meio de uma interface com bounding boxes; após a revisão, um callback retoma a máquina de estados e armazena os resultados no S3.
-
uais formatos são suportados e como os múltiplos tipos de documentos são tratados?
Formats suportados incluem PDF, JPG, PNG, TIFF, DOC e DOCX; o sistema seleciona automaticamente blueprints apropriados para carteiras de motorista, formulários de inscrição para apoio infantil e outros tipos dentro de um único projeto.
-
Como posso implantar essa solução?
s etapas de implantação estão disponíveis no repositório GitHub acompanhante mencionado no post.
Referências
More news

Levar agentes de IA do conceito à produção com Amazon Bedrock AgentCore
Análise detalhada de como o Amazon Bedrock AgentCore ajuda a transformar aplicações de IA baseadas em agentes de conceito em sistemas de produção de nível empresarial, mantendo memória, segurança, observabilidade e gerenciamento de ferramentas escalável.

Monitorar Bedrock batch inference da Amazon usando métricas do CloudWatch
Saiba como monitorar e otimizar trabalhos de bedrock batch inference com métricas do CloudWatch, alarmes e painéis para melhorar desempenho, custo e governança.

Prompting para precisão com Stability AI Image Services no Amazon Bedrock
O Bedrock now oferece Stability AI Image Services com nove ferramentas para criar e editar imagens com maior precisão. Veja técnicas de prompting para uso empresarial.

Aumente a produção visual com Stability AI Image Services no Amazon Bedrock
Stability AI Image Services já estão disponíveis no Amazon Bedrock, oferecendo capacidades de edição de mídia prontas para uso via Bedrock API, ampliando os modelos Stable Diffusion 3.5 e Stable Image Core/Ultra já existentes no Bedrock.

Use AWS Deep Learning Containers com o SageMaker AI gerenciado MLflow
Explore como os AWS Deep Learning Containers (DLCs) se integram ao SageMaker AI gerenciado pelo MLflow para equilibrar controle de infraestrutura e governança robusta de ML. Um fluxo de trabalho de predição de idade de ostra com TensorFlow demonstra rastreamento de ponta a ponta, governança de model

Construir Fluxos de Trabalho Agenticos com GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore
Visão geral de ponta a ponta para implantar modelos GPT OSS da OpenAI no SageMaker AI e no Bedrock AgentCore, alimentando um analisador de ações com múltiplos agentes usando LangGraph, incluindo quantização MXFP4 de 4 bits e orquestração serverless.