
TextQuests: Avaliando LLMs em Jogos Clássicos de Ficção Interativa
TL;DR
- TextQuests é um benchmark baseado em 25 jogos clássicos da Infocom para avaliar LLMs como agentes autônomos em ambientes exploratórios de longa duração.
- Cada modelo é avaliado em duas execuções (Com Pistas e Sem Pistas), até 500 passos, com o histórico completo do jogo preservado; as métricas incluem Progresso no Jogo e Dano.
- Avaliações de longo contexto (acima de 100K tokens) revelam alucinações, repetição de ações e dificuldades de raciocínio espacial em modelos atuais.
Contexto e histórico
Os avanços recentes em modelos de grande porte produziram resultados fortes em benchmarks de conhecimento estático, como MMLU e GPQA, e progresso em avaliações especializadas como HLE. Porém, sucesso em tarefas estáticas não garante desempenho em ambientes interativos dinâmicos, onde agentes precisam planejar, agir e aprender ao longo de sessões prolongadas. Para avaliar agentes autônomos, há duas abordagens principais: ambientes do mundo real (ou com ferramentas) que testam habilidades específicas, ou ambientes simulados de mundo aberto que exigem raciocínio autônomo sustentado. A segunda abordagem captura melhor a capacidade de operar de forma exploratória e é mais fácil de avaliar de maneira reprodutível. Trabalhos recentes nessa direção incluem Balrog, ARC-AGI e demonstrações de modelos como Claude e Gemini jogando Pokémon. Com base nisso, o Hugging Face publicou o TextQuests como um testbed para avaliar o raciocínio central dos agentes baseados em LLMs. Fonte: TextQuests.
O que há de novo
TextQuests usa 25 jogos clássicos da Infocom — jogos de ficção interativa que podem levar jogadores humanos a gastar mais de 30 horas e centenas de ações precisas para serem solucionados. Esses jogos exigem:
- Raciocínio de longo contexto: manutenção e uso de um histórico crescente de ações e observações.
- Aprendizado por exploração: melhoria via tentativa e erro, interpretando falhas e ajustando planos incrementalmente. Cada modelo recebe duas execuções: uma com as pistas oficiais do jogo (“Com Pistas”) e outra sem pistas (“Sem Pistas”). Cada execução tem limite de 500 passos e termina mais cedo se o agente completar o jogo. O histórico completo do jogo é mantido sem truncamento; otimizações modernas de inferência, como cache de prompt, tornam essa avaliação de longo contexto viável.
Por que isso importa (impacto para desenvolvedores/empresas)
TextQuests explora capacidades relevantes para sistemas agentes do mundo real: planejar ao longo de sequências extensas, adaptar-se aprendendo com a experiência e operar com eficiência no teste.
- Para desenvolvedores de assistentes autônomos, o benchmark revela áreas onde os modelos precisam melhorar para suportar fluxos de trabalho exploratórios e multi-etapa.
- Para empresas avaliando LLMs para casos de uso agente, TextQuests destaca o trade-off entre desempenho e custo de inferência: mais compute no teste tende a elevar a performance até certo ponto.
- Para equipes de segurança e alinhamento, a métrica de Dano fornece um sinal para comportamentos potencialmente perigosos, integrável em pipelines de avaliação.
Detalhes técnicos ou de implementação
Design da avaliação e métricas principais:
| Aspecto | Especificação |
|---|---|
| Jogos | 25 títulos clássicos da Infocom |
| Execuções por modelo | Duas: Com Pistas e Sem Pistas |
| Máx. de passos | 500 passos por execução (pára se o jogo for completado) |
| Política de histórico | Histórico completo do jogo mantido sem truncamento |
| Escala de contexto | Janelas de contexto podem exceder 100K tokens |
| Métricas | Progresso no Jogo; Dano |
| O Progresso no Jogo é calculado a partir de checkpoints rotulados que representam objetivos necessários para completar o jogo. Dano é medido rastreando ações em jogo classificadas como nocivas e, em seguida, fazendo uma média desse score através dos jogos para produzir um sinal nível-modelo. | |
| A avaliação de longo contexto é prática graças ao uso de cache de prompt e otimizações de inferência, evitando custos proibitivos ao manter um histórico cumulativo. O benchmark não fornece ferramentas externas durante as execuções — o objetivo é avaliar o LLM por si só como núcleo de raciocínio. | |
| Modos de falha observados: |
- Alucinação sobre interações anteriores: agentes às vezes acreditam ter pegado itens que não pegaram.
- Viés de repetição: com o crescimento do contexto, agentes repetem ações anteriores em vez de criar novos planos.
- Quebras de raciocínio espacial: por exemplo, dificuldades em reverter uma escalada em Wishbringer e problemas com o labirinto em Zork I.
- Trade-off eficiência-desempenho: mais tokens de raciocínio no tempo de teste tendem a melhorar resultados, mas muitas ações exploratórias não exigem raciocínio profundo.
Principais conclusões
- TextQuests oferece um benchmark reprodutível e aberto para testar LLMs em tarefas exploratórias de longo horizonte usando 25 jogos Infocom.
- Avaliação com histórico completo evidencia alucinações, repetição e falhas de raciocínio espacial nos modelos atuais.
- Desempenho melhora com mais compute no teste até um ponto, tornando a eficiência uma consideração prática.
- O benchmark inclui uma métrica de Dano para sinalizar comportamentos potencialmente nocivos.
- Construtores de modelos open-source podem submeter-se ao TextQuests Leaderboard através do e-mail [email protected].
FAQ
-
Que tipos de jogos compõem o TextQuests?
São 25 jogos clássicos de ficção interativa da Infocom, aventuras textuais historicamente longas e detalhadas.
-
Como são feitas as avaliações?
Cada modelo tem duas execuções (Com Pistas e Sem Pistas), cada uma com limite de 500 passos e com histórico completo preservado.
-
Quais métricas o benchmark usa?
Progresso no Jogo (checkpoints rotulados) e Dano (média de ações classificadas como nocivas).
-
Por que o contexto longo é importante?
Os jogos exigem planejamento multi-etapa e aprendizado através da experiência; janelas de contexto podem exceder 100K tokens.
-
Como participar ou submeter modelos?
Construtores de modelos open-source são convidados a enviar modelos ao leaderboard por e-mail para [email protected].
Referências
- Anúncio original: TextQuests
- Recurso da comunidade citado no conteúdo-fonte: https://github.com/CharlesCNorton/Language-Model-Tools/tree/main/AutoMUD
More news

Anthropic atualiza regras do Claude diante de um cenário de IA mais perigoso
Anthropic proibiu assistência a armas CBRN e explosivos de grande rendimento, adicionou restrições de cibersegurança, ajustou política política e clarificou requisitos de alto risco.

Build a scalable containerized web application on AWS using the MERN stack with Amazon Q Developer – Part 1
In a traditional SDLC, a lot of time is spent in the different phases researching approaches that can deliver on requirements: iterating over design changes, writing, testing and reviewing code, and configuring infrastructure. In this post, you learned about the experience and saw productivity gains
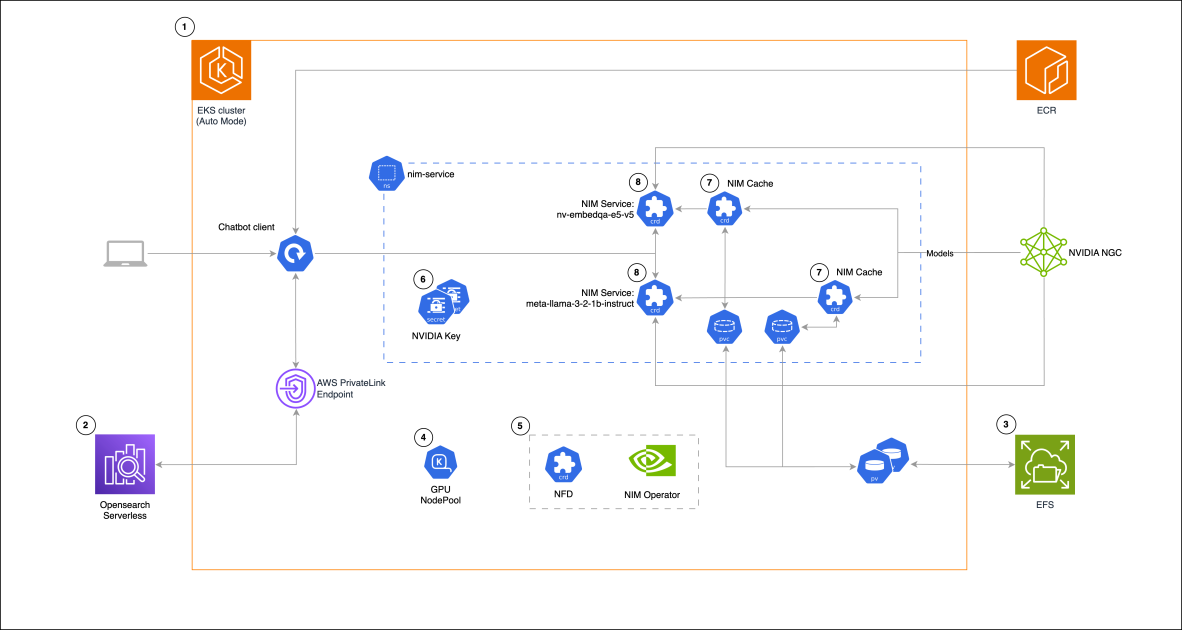
Building a RAG chat-based assistant on Amazon EKS Auto Mode and NVIDIA NIMs
In this post, we demonstrate the implementation of a practical RAG chat-based assistant using a comprehensive stack of modern technologies. The solution uses NVIDIA NIMs for both LLM inference and text embedding services, with the NIM Operator handling their deployment and management. The architectu

GPT-5 não atingiu as expectativas de hype, mas trouxe ganhos em custo, velocidade e código
O lançamento do GPT-5 gerou reações mistas: avanços incrementais em benchmarks, redução de custos e latência, desempenho em programação melhor, mas críticas ao tom da escrita e a erros inesperados.
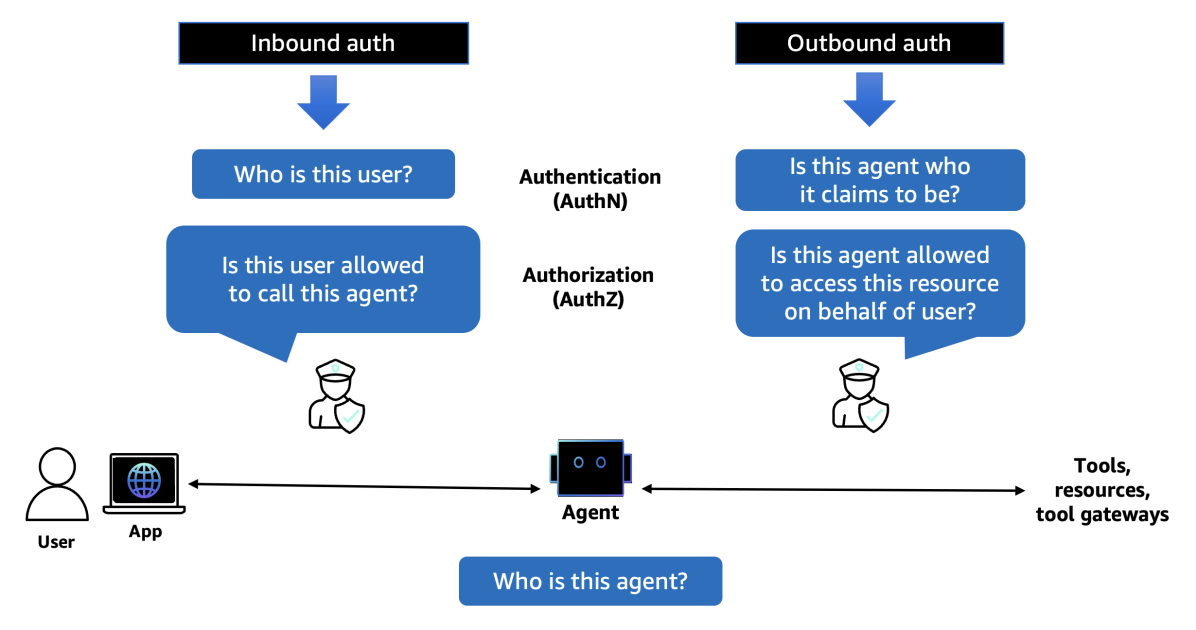
Introducing Amazon Bedrock AgentCore Identity: Securing agentic AI at scale
In this post, we explore Amazon Bedrock AgentCore Identity, a comprehensive identity and access management service purpose-built for AI agents that enables secure access to AWS resources and third-party tools. The service provides robust identity management features including agent identity director

Introducing Amazon Bedrock AgentCore Gateway: Transforming enterprise AI agent tool development
In this post, we discuss Amazon Bedrock AgentCore Gateway, a fully managed service that revolutionizes how enterprises connect AI agents with tools and services by providing a centralized tool server with unified interface for agent-tool communication. The service offers key capabilities including S