Voltando ao Futuro: Avaliando agentes de IA na previsão de eventos futuros
Sources: https://huggingface.co/blog/futurebench, Hugging Face Blog
TL;DR
- O FutureBench avalia agentes de IA prevendo eventos futuros em vez de apenas facts passados, visando medir capacidades de raciocínio e tomada de decisão no mundo real. FutureBench defende que a previsão de futuros oferece inteligência mais transferível do que benchmarks estáticos.
- O benchmark utiliza duas fontes de dados complementares: um fluxo de trabalho de scraping de notícias baseado em smolagents que gera perguntas com prazo definido, e perguntas de mercado de previsão da Polymarket.
- A avaliação é organizada em três níveis para isolar onde ocorrem ganhos de desempenho: (1) diferenças de framework, (2) desempenho de ferramentas e (3) capacidades do modelo. Isso ajuda a decidir onde investir em ferramentas, acesso a dados ou design de modelos.
- Resultados iniciais mostram que modelos com capacidade de agente superam modelos de linguagem básicos sem acesso à internet, com diferenças notáveis em como os modelos coletam informações (busca versus scraping) que afetam custos e resultados.
- O leaderboard ao vivo e o toolkit enxuto permitem avaliação contínua, com padrões claros em como os modelos abordam tarefas de previsão.
Contexto e antecedentes
Benchmarks tradicionais de IA costumam medir perguntas sobre o passado—testando conhecimentos armazenados, fatos estáticos ou problemas resolvidos. Os autores do FutureBench argumentam que o verdadeiro avanço para IA útil, e potencialmente para IA Geral (AGI), dependerá da capacidade de sintetizar informações atuais e prever resultados futuros. Questões de previsão abrangem ciência, economia, geopolítica e adoção tecnológica, exigindo raciocínio sofisticado, síntese e ponderação de probabilidades, em vez de apenas correspondência de padrões. Além disso, a previsão oferece verificabilidade objetiva ao longo do tempo, resolvendo preocupações sobre vazamento de dados em benchmarks fixos. Mais detalhes sobre o FutureBench podem ser encontrados no post oficial FutureBench. A abordagem do FutureBench está alinhada com fluxos de trabalho práticos de previsão, onde qualidade de coleta de informações informa diretamente a tomada de decisão. Ao usar notícias ao vivo e mercados de previsão, as perguntas ficam ancoradas em desfechos reais, promovendo raciocínio sob incerteza como desafio central. O design enfatiza que a previsão não é adivinhação desinformada, mas síntese de dados relevantes para prever resultados prováveis. O ecossistema também destaca a importância de um pipeline orientado a agentes: coleta de dados, formulação de perguntas e raciocínio estruturado. A avaliação utiliza um conjunto de ferramentas enxuto para manter a tarefa desafiadora e enfatizar estratégias de obtenção de informação. O objetivo é revelar como diferentes modelos se saem em termos de aquisição de dados, raciocínio causal e calibração de previsões. A intenção é que o ecossistema seja aberto a experimentos contínuos com novas arquiteturas e dados.
O que há de novo
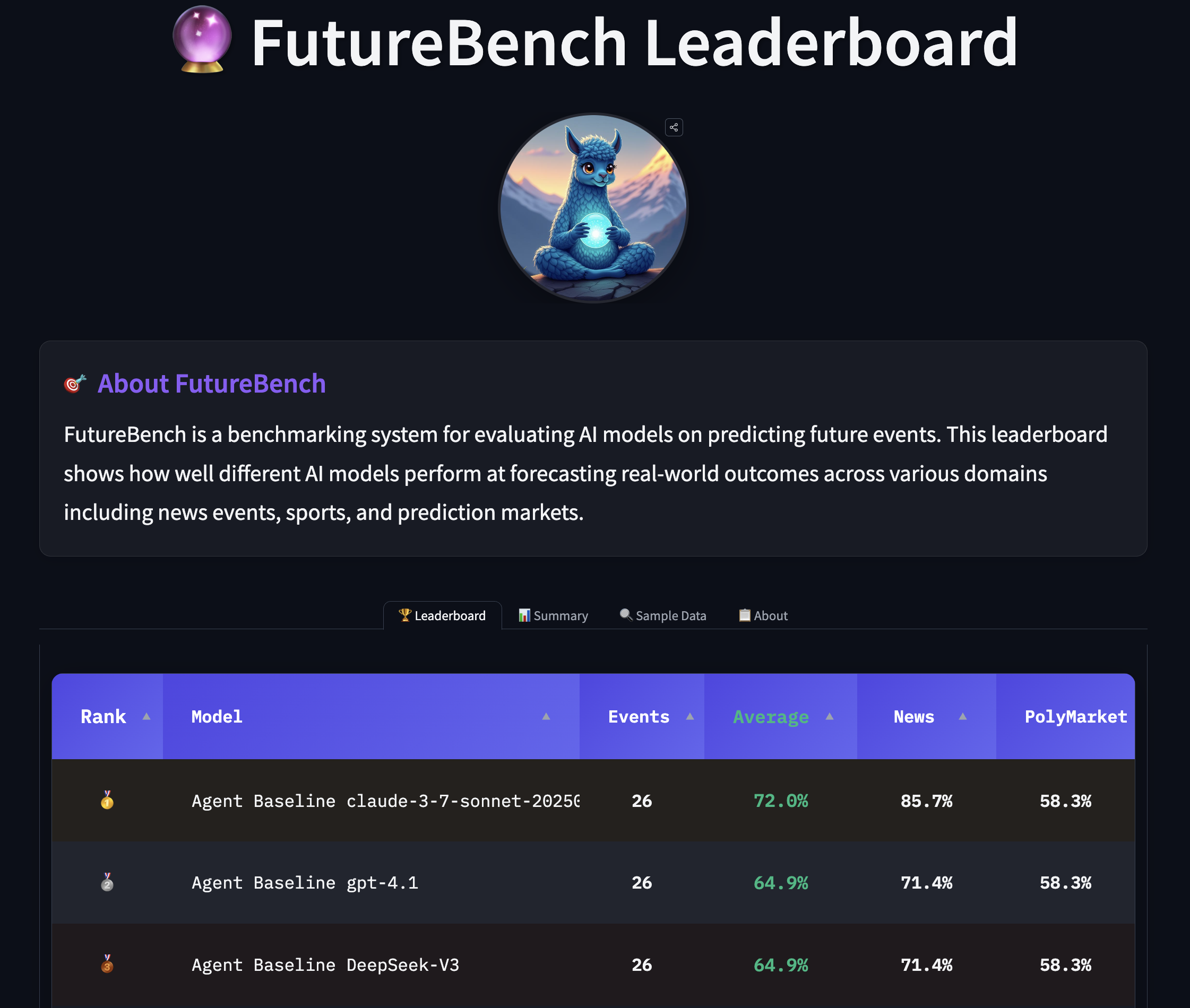
O FutureBench apresenta duas fontes principais de perguntas com foco futuro. Primeiro, um agente baseado em SmolAgents varre grandes veículos de notícia para gerar cinco perguntas com prazos definidos por sessão de scraping (com horizonte de uma semana). Em segundo lugar, a Polymarket fornece uma corrente de perguntas de mercado de previsão, aproximadamente oito por semana. Há filtragem para evitar perguntas genéricas sobre tempo ou sobre certos temas de mercado, reconhecendo que os tempos de “realização” podem variar até o fim do ano. O objetivo é manter perguntas significativas, incertas e verificáveis. A contribuição central do FutureBench é o seu framework de avaliação em três níveis. Nível 1 isola efeitos de framework ao manter LLMs e ferramentas constantes e variar apenas o framework do agente. Nível 2 isola desempenho de ferramentas mantendo o LLM e o framework constantes, comparando mecanismos de busca. Nível 3 isola capacidades do modelo mantendo o mesmo framework e ferramentas e testando diferentes LLMs. Esse design permite atribuir ganhos de desempenho a arquitetura, acesso a dados ou capacidades de raciocínio. A avaliação também analisa o seguimento de instruções, exigindo que os agentes respeitem formatos e outputs parseáveis. Em termos práticos, o FutureBench utiliza SmolAgents como baseline para todas as perguntas e computa o desempenho também em modelos-base. O task de previsão é realizado com um toolkit focado para forçar uma coleta de informações estratégica, mantendo ainda o acesso às capacidades necessárias. Observações iniciais indicam que modelos com capacidade de agente tendem a superar LMs simples, com modelos mais fortes mostrando maior estabilidade de qualidade. Um exemplo citado envolve a inflação de junho de 2025: diferentes modelos fizeram caminhos de previsão distintos. O GPT-4.1 utilizou buscas direcionadas ao consenso de mercado, encontrou CPI de maio em 2,4% e concluiu que o salto para 2,6% em junho era improvável dadas as forças de crescimento abaixo do esperado. Claude3.7 e Claude4 recorreram a uma exploração mais ampla da web e coleta de dados CPI de maio, identificando tendências de desaceleração mensal e também concluindo que o limiar de 2,6% era improvável. Observou-se ainda que Claude tentou acessar diretamente o site do Bureau of Labor Statistics para scraping, mas a tentativa falhou, ilustrando tanto o potencial quanto as limitações de acesso a dados em tempo real. Essas observações refletem experimentos ao vivo descritos no post do FutureBench FutureBench. O ecossistema FutureBench também oferece um leaderboard ao vivo no Hugging Face Spaces, promovendo comparação entre agentes, conjuntos de dados e modelos. O design é modular, permitindo que pesquisadores substituam componentes como agentes, ferramentas ou fontes de dados para replicar ou ampliar a avaliação. Isso facilita a comparação entre abordagens novas e as já estabelecidas no ecossistema de IA.
Por que isso importa (impacto para desenvolvedores/empresas)
Benchmarks centrados em previsão oferecem várias vantagens para equipes que desenvolvem IA voltada a suporte à decisão:
- Avaliação mais relevante de raciocínio sob incerteza: ao enfatizar previsões futuras, o benchmark alinha-se com casos de uso que impactam estratégia, gestão de risco e política pública, indo além de simply memorization.
- Resultados verificáveis e transparentes: as previsões aguardam desfechos reais, permitindo validação objetiva ao longo do tempo. Isso ajuda a estabelecer confiança e reduz dúvidas sobre vazamento de dados.
- Diagnóstico claro: o framework em três níveis oferece orientações acionáveis sobre onde investir — arquitetura de agentes, ferramentas de acesso a dados ou capacidades de raciocínio do modelo.
- Dados práticos e formatos realistas: usar notícias ao vivo e mercados de previsão reproduz fluxos de trabalho profissionais, ajudando a alinhar IA com operações de negócios, finanças e políticas públicas.
- Consciência de custo e eficiência: as observações sobre estratégias de coleta de informações ajudam equipes a equilibrar a qualidade dos dados com o custo computacional, especialmente em deployments corporativos. Para organizações que constroem ferramentas de IA para suporte a decisão, o FutureBench oferece uma maneira disciplinada de avaliar capacidades de previsão e diagnosticar onde melhorias são mais valiosas. A ênfase na verificabilidade, na reprodutibilidade e na relevância prática faz do FutureBench um complemento sólido a benchmarks de acurácia tradicionais, especialmente para casos de uso onde previsões moldam estratégia, avaliação de risco ou design de políticas. A comunidade pode acompanhar o leaderboard ao vivo e contribuir para o ecossistema de avaliação em evolução FutureBench.
Detalhes técnicos ou Implementação
O FutureBench depende de duas cadeias principais de perguntas com foco em previsão e de um regime de avaliação estruturado:
- Fontes de dados: scraping de notícias em tempo real com SmolAgents para gerar cinco perguntas por sessão; perguntas de Polymarket com aproximadamente oito por semana. Filtros removem questões genéricas sobre tempo e certos tópicos de mercado para manter o conjunto gerenciável; reconhece-se que algumas questões podem ter janelas de realização que se estendem além de uma semana.
- Ferramentas e baseline: um conjunto enxuto de ferramentas para manter o desafio de raciocínio, com SmolAgents atuando como baseline para todas as perguntas. O desempenho é calculado para modelos-base e configurações com agentes.
- Níveis de avaliação e controles: níveis 1, 2 e 3 para isolar efeitos de framework, ferramentas e capacidades do modelo, respectivamente. Esse arranjo permite atribuir ganhos de desempenho a componentes específicos da cadeia.
- Observações de comportamento de modelos: em geral, abordagens com agentes superam LMs sem acesso à internet. Diferenças na coleta de informações aparecem com clareza: alguns modelos dependem mais de resultados de busca, outros exploram mais amplamente a web e scraping, o que pode aumentar o custo de tokens. Um exemplo mostra modelos calibrando previsões ao considerar dados CPI, impactos tarifários e política do Fed para estimar uma previsão de inflação, enquanto outros se apoiam mais em consenso de mercado e CPI de maio para avaliar a probabilidade de um salto específico.
- Implementação prática: o design facilita revelar onde ganhos ocorrem na linha de aquisição de dados, formulação de perguntas e raciocínio sob incerteza. O leaderboard ao vivo e o ecossistema Hugging Face permitem replicar, estender e comparar novas arquiteturas de agentes, ferramentas ou dados FutureBench.
Tabela: Elementos-chave da configuração FutureBench
| Componente | Descrição | Relevância |---|---|---| | Fontes de dados | Notícias ao vivo e perguntas de Polymarket | Ancoram tarefas de previsão em eventos reais |Cadência de perguntas | ~5 por sessão de scraping; ~8 por semana de Polymarket | Garante fluxo contínuo de material de avaliação |Horizontes | Principalmente janelas de uma semana; alguns prazos de realização variam | Testa capacidade de prever dentro de prazos úteis |Níveis de avaliação | Framework, ferramentas e capacidades do modelo | Diagnóstico de onde melhorar |Linhas de baseline | SmolAgents como baseline; LMs base | Demonstra valor de abordagens com agentes |
Principais conclusões
- Benchmarks focados em previsão deslocam o interesse de memorização para raciocínio, síntese e gerenciamento de incerteza.
- O framework em três níveis facilita identificar se ganhos vêm do framework de agente, das ferramentas de acesso a dados ou das capacidades do modelo.
- Abordagens baseadas em agentes costumam superar LMs simples nesses exercícios, com modelos mais fortes oferecendo maior estabilidade de qualidade.
- Estratégias de coleta de informações afetam resultados e custo; diferentes modelos equilibram busca e scraping de maneiras distintas.
- O FutureBench oferece leaderboard ao vivo e toolkit extensível, convidando pesquisadores a incorporar novos agentes, ferramentas ou fontes de dados e comparar resultados com uma linha de base comum.
FAQ
-
O que é o FutureBench?
Um benchmark para avaliar agentes de IA na previsão de eventos futuros usando fontes de dados reais.
-
uais são as fontes de dados do FutureBench?
Notícias de frente de sites de notícias por scraping de SmolAgents e perguntas de mercado de Polymarket.
-
uantas perguntas são geradas por sessão/por semana?
Cerca de cinco por sessão de scraping e aproximadamente oito perguntas por semana da Polymarket.
-
Como as avaliações são estruturadas?
Em três níveis: comparação de frameworks, desempenho de ferramentas e capacidade do modelo.
-
Onde ver resultados ao vivo?
O leaderboard está disponível no Hugging Face Spaces como parte do ecossistema FutureBench [FutureBench](https://huggingface.co/blog/futurebench).
Referências
More news

Scaleway Como Novo Fornecedor de Inferência no Hugging Face para Inferência serverless de Baixa Latência
A Scaleway é agora um Fornecedor de Inferência compatível no Hugging Face Hub, permitindo inferência serverless diretamente nas páginas de modelo com as SDKs JS e Python. Acesse modelos abertos populares com operações escaláveis e baixa latência.

Reduzindo a Latência de Cold Start para Inferência de LLM com NVIDIA Run:ai Model Streamer
Análise detalhada de como o NVIDIA Run:ai Model Streamer reduz o tempo de cold-start na inferência de LLMs ao transmitir pesos para a memória da GPU, com benchmarks em GP3, IO2 e S3.

Como a msg otimizou a transformação de RH com Amazon Bedrock e msg.ProfileMap
Este post mostra como a msg automatizou a harmonização de dados para o msg.ProfileMap usando o Amazon Bedrock para alimentar fluxos de enriquecimento de dados alimentados por LLM, elevando a precisão na correspondência de conceitos de RH, reduzindo trabalho manual e alinhando-se ao EU AI Act e ao GD

Como o Treinamento com Quantização Detecta e Recupera Precisão em Inferência de Baixa Precisão
Explora quantization aware training (QAT) e distilação quantization aware (QAD) como métodos para recuperar precisão em modelos de baixa precisão, usando o TensorRT Model Optimizer da NVIDIA e formatos FP8/NVFP4/MXFP4.

Acelere a Inferência de Estrutura de Proteínas em Mais de 100x com o NVIDIA RTX PRO 6000 Blackwell Server Edition
O RTX PRO 6000 Blackwell Server Edition da NVIDIA acelera drasticamente a inferência de estruturas de proteínas, permitindo fluxos de trabalho end-to-end movidos a GPU com OpenFold e TensorRT, atingindo até 138x mais rápido que o AlphaFold2.

Por que modelos de linguagem alucinam — e como a OpenAI está reformulando avaliações para aumentar a confiabilidade
A OpenAI descreve que as alucinações em modelos de linguagem surgem de incentivos de avaliação que favorecem adivinhação em vez da incerteza. O texto explica como pontuações e benchmarks focados na incerteza podem reduzir erros confiantes e melhorar a confiabilidade.