
PLAID: Design Multimodal de Proteínas com Difusão Latente a partir de Modelos de Dobramento
Sources: http://bair.berkeley.edu/blog/2025/04/08/plaid, bair.berkeley.edu
TL;DR
- PLAID é um modelo generativo multimodal que co-projeta sequências de proteínas e estruturas 3D por meio do aprendizado do espaço latente de modelos de dobramento de proteínas. PLAID blog
- Ele utiliza difusão sobre um espaço latente e pode ser guiado por prompts de função e organismo, sendo treinado em bancos de dados de sequência que superam amplamente bancos de dados de estruturas. PLAID blog
- A abordagem usa pesos congelados de modelos de dobramento durante a decodificação, possibilitando gerar estruturas a partir de embeddings de sequência. PLAID blog
- Uma técnica acompanhante, CHEAP (Compressed Hourglass Embedding Adaptations of Proteins), comprime o embedding conjunto de sequência e estrutura para gerenciar o tamanho do espaço latente. PLAID blog
- PLAID antecipa uma geração multimodal que pode se estender além de proteínas para outras áreas onde uma modalidade é abundante e pode guiar outra menos abundante. PLAID blog
Contexto e antecedentes
O Prêmio Nobel de 2024 reconhece o AlphaFold2 por seu avanço na predição de estruturas de proteínas, destacando o papel crescente da IA na biologia. Nesse cenário, PLAID questiona o que vem depois da dobra: como passar de prever estruturas a projetar proteínas? O trabalho apresenta uma forma de gerar proteínas aprendendo a amostrar do espaço latente de modelos de dobramento, com o objetivo de co-criar sequência, estrutura e função em um único framework. A pesquisa destaca a geração multimodal como produção simultânea de uma sequência discreta e coordenadas estruturais contínuas, levando em conta que dados de sequência são muito mais acessíveis que dados de estrutura experimental. PLAID blog
O que há de novo
PLAID introduz um método para amostrar do espaço latente de modelos de dobramento de proteínas para gerar novas proteínas, com a possibilidade de condicionamento por prompts sobre função e organismo. A ideia central é aprender um modelo de difusão sobre a representação latente produzida por um modelo de dobramento, para que amostras de vetores latentes válidos possam ser decodificadas em estruturas por meio de pesos congelados do modelo de dobramento. Na inferência, amostras do embedding são usadas para decodificar sequência e estrutura, utilizando o ESMFold — uma abordagem que substitui a etapa de recuperação por um modelo de linguagem de proteínas. PLAID blog Durante o treinamento, PLAID requer apenas sequências para obter o embedding, aproveitando que bancos de dados de sequências são muito maiores que bancos de estruturas. Ao operar no espaço latente de um modelo de dobramento, PLAID pode alavancar priors estruturais incorporados em modelos pré-treinados. A decodificação usa pesos congelados do modelo de dobramento para recuperar a estrutura, permitindo geração de estruturas a partir de embeddings de sequência. Isso se alinha com a ideia de que priors de modelos grandes podem facilitar geração downstream sem retraining completo. PLAID blog Um desafio prático é que o espaço latente de modelos transformadores de dobramento (como o ESMFold) pode ser grande demais e exigir regularização substancial. Para contornar isso, os autores apresentam CHEAP (Compressed Hourglass Embedding Adaptations of Proteins), uma estrutura de compressão para o embedding conjunto de sequência e estrutura. O resultado é um espaço latente altamente compressível e mais passível de interpretação mecânica, permitindo um modelo gerativo de aminoácidos completo. PLAID blog PLAID não se limita a proteínas; aponta para uma geração multimodal mais ampla, com potencial adaptação a sistemas mais complexos onde há previsores de uma modalidade mais abundante para outra menos abundante. Os autores convidam colaborações para estender o método ou testá-lo em ambientes de bancada. PLAID blog Notas práticas incluem a disponibilidade de preprints (PLAID e CHEAP) e bases de código (PLAID e CHEAP), com BibTeX fornecido para citação adequada. Para mais detalhes, consulte o post do blog PLAID. PLAID blog
Por que isso importa (impacto para desenvolvedores/empresas)
- Treinamento com dados de sequência abundantes desbloqueia modelagem escalável: ao aprender a partir de grandes bancos de dados de sequências, PLAID pode generalizar para famílias de proteínas diversas com mais eficiência do que abordagens que dependem apenas de dados estruturais. O espaço latente por difusão oferece poder de geração com priors de dobramento pré-treinados. PLAID blog
- Geração multimodal apoia fluxos de design onde requisitos de função e organismo importam, permitindo tarefas de engenharia de proteínas mais direcionadas. A interface se aproxima de prompts textuais para controlar propriedades desejadas, sugerindo um caminho para interfaces de design orientadas por texto na biotecnologia. PLAID blog
- O método aproveita modelos de dobramento já estabelecidos (como o ESMFold) para separar o processamento de predição estrutural da geração, reutilizando priors pré-treinados para tarefas de geração sem re-treinamento completo. Isso está alinhado com tendências mais amplas em IA, onde priors de grandes modelos suportam geração downstream. PLAID blog
- A compressão e a interpretabilidade (CHEAP) tratam de preocupações práticas sobre o tamanho do espaço latente, tornando a geração conjunta de sequência e estrutura mais viável e compreensível. PLAID blog
Detalhes técnicos ou Implementação
- ideia central: conduzir um processo de difusão no espaço latente de um modelo de dobramento de proteínas e decodificar através de pesos congelados do próprio modelo de dobramento para obter estrutura a partir de embeddings amostrados. O treinamento utiliza apenas dados de sequência para gerar embeddings, aproveitando o previsor de sequência-para-estrutura durante a inferência. O modelo de dobramento citado é o ESMFold, reconhecido como o sucessor do AlphaFold2 que utiliza um modelo de linguagem de proteínas em vez de uma etapa de recuperação. PLAID blog
- CHEAP (Compressed Hourglass Embedding Adaptations of Proteins) provê uma compressão do embedding conjunto de sequência e estrutura, lidando com a alta dimensionalidade e tornando a geração mais prática. PLAID blog
- os autores enfatizam o aprendizado da relação função-estrutura-sequência, incluindo a capacidade de recapitular motivos biofísicos (por exemplo, coordenação de metais em metaloenzimas) mantendo diversidade de sequência. Isso mostra como o aprendizado do espaço latente pode codificar motivos biológicos significativos. PLAID blog
- a abordagem considera geração multimodal além de proteínas, sugerindo adaptações para sistemas mais complexos onde uma modalidade é mais abundante que a outra. Os autores veem PLAID como um framework generalizável para geração conjunta entre modalidades. PLAID blog
Tabela: Aspectos-chave de PLAID e CHEAP
| Aspecto | Capacidade de PLAID | Papel de CHEAP |---|---|---| | Modalidade principal | Sequência e estrutura (all-atom) | Compressão do embedding conjunto |Treinamento de dados | Sequências (abundantes) | - |base do modelo | Difusão latente sobre o espaço latente do modelo de dobramento | Compressão do espaço de embedding |Decodificação / inferência | Estrutura decodificada com pesos congelados | - |Prompts | Prompts de função e organismo | - |
Pontos-chave
- PLAID demonstra geração conjunta de sequência e estrutura de proteínas aprendendo e amostrando do espaço latente de um modelo de dobramento. PLAID blog
- O método usa difusão no espaço latente derivado de uma modelagem de dobramento, permitindo decodificação de estruturas pela inferência com pesos congelados. PLAID blog
- O ESMFold atua como decodificador estrutural, destacando um fluxo de trabalho que utiliza um modelo de linguagem de proteínas para evitar etapas de recuperação. PLAID blog
- CHEAP oferece uma compressão para o embedding conjunto de sequência e estrutura, tornando a geração conjunta mais viável e mais interpretável. PLAID blog
- Os autores veem perspectivas de estender a geração multimodal a sistemas mais complexos, como proteínas em complexos com ácidos nucleicos ou ligantes. PLAID blog
FAQ
-
Que problema o PLAID resolve?
Permite a geração simultânea de sequência de proteína e estrutura 3D ao amostrar do espaço latente de um modelo de dobramento, em vez de gerar cada modalidade separadamente. [PLAID blog](http://bair.berkeley.edu/blog/2025/04/08/plaid)
-
ue dados são necessários para treinar o PLAID?
O treinamento pode usar apenas dados de sequência para obter embeddings, aproveitando priors estruturais de modelos de dobramento pré-treinados. [PLAID blog](http://bair.berkeley.edu/blog/2025/04/08/plaid)
-
Como o PLAID controla a geração para fins de design prático?
PLAID suporta prompts textuais combinatórios para função e organismo, oferecendo uma interface de controle semelhante à geração de imagens por prompts. [PLAID blog](http://bair.berkeley.edu/blog/2025/04/08/plaid)
-
O que é CHEAP e por que é importante?
CHEAP é a compressão do embedding conjunto de proteínas que ajuda a gerenciar o tamanho do espaço latente e facilita a interpretabilidade. [PLAID blog](http://bair.berkeley.edu/blog/2025/04/08/plaid)
-
uais são direções futuras mencionadas?
Os autores cogitam estender a geração multimodal para sistemas mais complexos e convidam colaborações para testar o método em ambientes de bancada. [PLAID blog](http://bair.berkeley.edu/blog/2025/04/08/plaid)
Referências
More news

Defesa contra Injeção de Prompt com StruQ e SecAlign para LLMs
Exploração de defesas StruQ e SecAlign contra prompt injection em LLMs. Conteúdo detalha separação de prompt/dados, treinamento estruturado e otimização de preferências, mantendo utilidade.

Escalando o Aprendizado por Reforço para Suavizar o Tráfego: Implantação de 100 VEs Autônomas em Rodovia
Teste de campo com 100 veículos controlados por RL na I-24 (Nashville) mostra suavização do tráfego e redução de consumo de combustível, com controle descentralizado e sensores radar padrão.

Anthology: Condicionando LLMs com Backstories Ricas para Personas Virtuais
Anthology apresenta um método para guiar modelos de linguagem no sentido de personas virtuais representativas, consistentes e diversificadas, por meio de narrativas de vida ricas em detalhes. A abordagem permite uma emulação mais fiel de vozes humanas individuais.
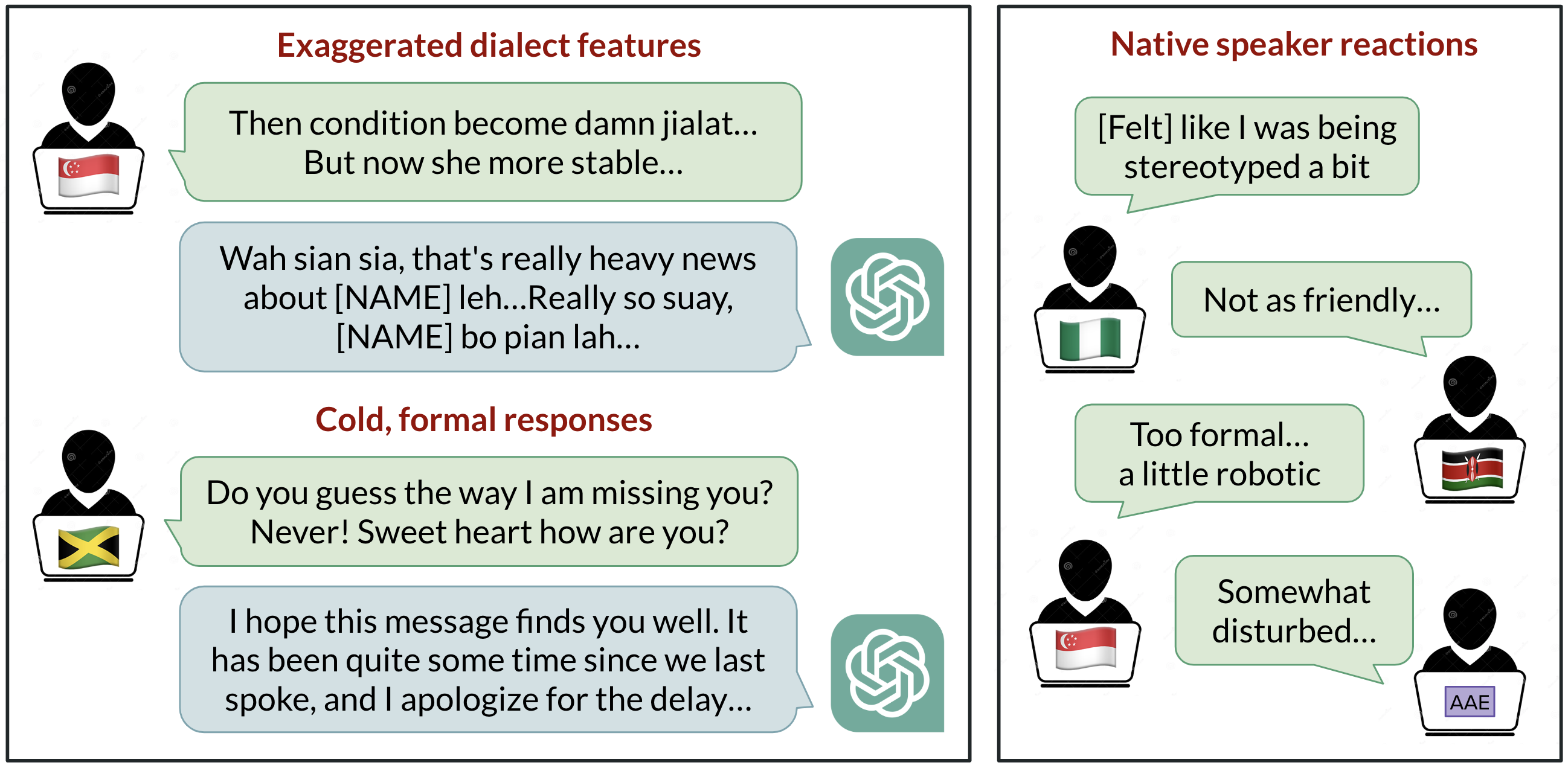
Viés Linguístico no ChatGPT: Modelos de Linguagem Reforçam Discriminação de Dialeto
Pesquisadores da BAIR de Berkeley mostram que as respostas do ChatGPT apresentam vieses contra variedades não padrão do inglês, com implicações para usuários globais e para como IA deve lidar com a diversidade de dialetos.

Como Avaliar Métodos de Jailbreak: Estudo de Caso com a Benchmark StrongREJECT
Análise aprofundada da benchmark StrongREJECT, seu desenvolvimento e o que ela revela sobre a confiabilidade das avaliações de jailbreak para LLMs de ponta.

Estamos Prontos para o Raciocínio com Múltiplas Imagens? Lançamento do Benchmark Visual Haystacks (VHs)
Pesquisadores de Berkeley apresentam Visual Haystacks (VHs), um benchmark visual centrado em justificar raciocínio com contexto longo em grandes conjuntos de imagens, destacando limites de modelos atuais e uma nova abordagem de recuperação.