TinyAgent: Chamada de Funções na Borda para LMs Pequenos
Sources: http://bair.berkeley.edu/blog/2024/05/29/tiny-agent, bair.berkeley.edu
TL;DR
- TinyAgent foca em modelos de linguagem pequenos (SLMs) para realizar chamadas de função e orquestrar ferramentas na borda, possibilitando operação privada e offline. BAIR
- Utiliza dados de alta qualidade, cuidadosamente curados, para chamadas de função e planejamento, seguido de ajuste fino que pode superar modelos abertos maiores nessa tarefa. BAIR
- Introduz o método Tool RAG para melhorar a eficiência e a escalabilidade da chamada de funções em borda. BAIR
- Demonstração com TinyAgent‑1B aliado ao Whisper‑v3 rodando localmente em um MacBook M3 Pro, destacando a viabilidade de implantação de borda. BAIR
- O framework é de código aberto e está disponível no repositório do projeto, permitindo que desenvolvedores construam soluções de IA privadas e de baixa latência na borda. TinyAgent no GitHub
Contexto e antecedentes
Modelos de linguagem grandes (LLMs) estão cada vez mais capacitados a executar comandos via linguagem natural ao orquestrar um conjunto adequado de ferramentas, criando sistemas com algum grau de agência que podem atender a uma consulta do usuário invocando APIs ou scripts predefinidos. No entanto, a implementação prática em larga escala é dificultada pelo tamanho e pelos requisitos computacionais, geralmente levando a inferência na nuvem. Enviar dados como vídeo, áudio ou documentos de texto para fornecedores terceiros levanta preocupações de privacidade, e o acesso à nuvem requer conectividade que pode não estar disponível em ambientes reais (por exemplo, robôs em campo). Além disso, a latência associada à transferência de dados e à espera por respostas pode comprometer o tempo de solução. A solução proposta é implantar modelos LLM menores localmente na borda, mas isso exigia reduzir o peso computacional sem perder desempenho. BAIR Observa-se que modelos maiores tendem a memorizar informações gerais do mundo em sua memória paramétrica, o que facilita comportamentos emergentes como aprendizado por contexto e raciocínio complexo — fatores que impulsionaram a escala de modelos. A ideia é que um modelo menor aprenda a invocar as funções corretas e a orquestrar chamadas sem depender de memória de conhecimento geral. O projeto TinyAgent investiga se LMs abertos e menores podem aprender a realizar chamadas de função com dados de alta qualidade, tornando possível aplicações de IA sem depender de dados amplos da internet. BAIR O trabalho foca em um aplicativo MacOS local para demonstrar a integração de agentes com scripts Apple predefinidos. O objetivo é que o modelo aprenda a identificar quais funções chamar, com quais argumentos e em que ordem, enfatizando a orquestração de funções em vez de memorização de fatos globais. BAIR TinyAgent no GitHub
O que há de novo
Este trabalho traz várias contribuições para implantações reais de agentes no edge com LMs pequenos:
- Demonstração de que modelos abertos pequenos podem executar chamadas de função com precisão quando treinados com um conjunto de dados altamente curado para planejamento e orquestração de chamadas. TinyLLaMA‑1.1B e Wizard‑2‑7B, sem ajuste, apresentaram dificuldades iniciais para gerar planos corretos; a solução envolve dados específicos para a tarefa. BAIR
- Geração de dados sintéticos com um LLM (GPT‑4‑Turbo) para produzir consultas realistas de usuário que requerem funções específicas, acompanhadas de planos de chamadas de função e argumentos. Sanidade dos planos garante que gerados formem um gráfico viável e que nomes de funções e tipos de entrada estejam corretos. O conjunto tem 80K de treino, 1K de validação e 1K de teste, com custo total de cerca de US$ 500. BAIR
- O framework LLMCompiler emite um plano de chamadas de função, incluindo quais funções usar, quais inputs fornecer e as dependências entre chamadas. Após a geração, o plano é analisado e as funções são executadas conforme as dependências. BAIR
- Introdução do Tool RAG como uma forma de aumentar a eficiência do processo de chamadas de função para borda. BAIR
- Demonstração prática com TinyAgent‑1B e Whisper‑v3 rodando localmente em um MacBook M3 Pro, evidenciando respostas em tempo real sem acesso à nuvem. BAIR
- A estrutura é de código aberto e pode ser acessada em https://github.com/SqueezeAILab/TinyAgent, convidando a comunidade a explorar soluções de agente no edge com LMs pequenos. TinyAgent no GitHub
Por que isso importa (impacto para desenvolvedores/empresas)
Implantar IA no edge oferece privacidade, resiliência e baixa latência mantendo dados e computação localmente. TinyAgent aborda o principal gargalo dessa abordagem: depender de LLMs grandes na nuvem para chamadas de função e orquestração de ferramentas. Ao demonstrar que LMs pequenos podem aprender a planejar e executar chamadas de função por meio de dados curados e ajuste fino direcionado, o trabalho aponta um caminho para implantar agentes competentes no edge sem sacrificar desempenho. Para desenvolvedores e empresas, isso pode significar automação privada, offline, que ainda utiliza chamadas de função estruturadas e APIs, permitindo casos de uso como aplicação local para criação de compromissos no calendário, busca de e-mails ou outros fluxos de trabalho específicos de domínio, sem expor dados a serviços externos. O projeto enfatiza adaptadores e scripts predefinidos que podem ser integrados aos pipelines existentes de ferramentas, promovendo uma pegada de IA no edge mais segura. BAIR TinyAgent no GitHub
Detalhes técnicos ou Implementação
Aplicação orientadora e plataforma alvo
- A aplicação de referência é um assistente MacOS local capaz de interagir com aplicações Mac através de scripts Apple predefinidos. Serve de exemplo para um agente local que entende perguntas em linguagem natural e orquestra chamadas de API para realizar tarefas, como criar itens de calendário. O papel do modelo é decidir quais funções chamar, quais argumentos fornecer e a ordem correta de execução. BAIR
- O sistema suporta 16 funções que interagem com diferentes aplicações do Mac. Scripts Apple já existem para cada função, cabendo ao modelo apenas definir o plano de chamadas e fornecer os inputs necessários. BAIR
Plano de chamadas de função e LLMCompiler
- Um desafio central é permitir que modelos pequenos gerem um plano de chamadas de função correto. O framework LLMCompiler orienta o LM a emitir um plano que indica quais funções chamar, quais argumentos usar e a dependência entre as chamadas. O plano é então analisado e as funções são executadas conforme as dependências. BAIR
- Embora modelos grandes consigam gerar planos precisos com prompts adequados, modelos pequenos (p. ex., TinyLLaMA‑1.1B ou Wizard‑2‑7B) inicialmente apresentaram erros como conjuntos de funções incorretos, nomes fabricados, dependências erradas ou sintaxe inconsistente. O trabalho demonstra que isso pode ser superado com dados curados e ajuste fino focalizado na tarefa. BAIR
Dados, dados sintéticos e avaliação
- Como dados manuais para planos diversos de chamadas de função não são escaláveis, a equipe usa um LLM para gerar dados sintéticos com conjuntos de funções e consultas realistas que exigem essas funções. Cada exemplo inclui um plano de chamada de função e os argumentos de entrada. Verificações de sanidade asseguram que os planos formem um gráfico viável e que nomes de funções e tipos de entrada estejam corretos. O conjunto resulta em 80K exemplos de treino, 1K validação e 1K teste, com custo total de aproximadamente US$ 500. BAIR
- A métrica Graph Isomorphism Success Rate é utilizada: o plano recebe 1 se o DAG gerado for isomórfico ao DAG de referência, indicando que as dependências funcionais foram capturadas com precisão, mesmo que a ordem de chamadas varie. Isso é ilustrado nos gráficos da publicação. BAIR
Tool RAG e eficiência no edge
- O trabalho apresenta o conceito de Tool RAG como uma forma de aumentar a eficiência da chamada de funções em implantações de borda, ajudando a tornar o planejamento e a execução mais escaláveis. BAIR
Código aberto e disponibilidade
- O framework TinyAgent, incluindo código e materiais, é de código aberto e está disponível em https://github.com/SqueezeAILab/TinyAgent, convidando pesquisadores e desenvolvedores a explorar soluções de agentes no edge com LMs pequenos. TinyAgent no GitHub
Demonstração e hardware
- A demonstração ao vivo apresenta TinyAgent‑1B com Whisper‑v3 rodando localmente em um MacBook M3 Pro, evidenciando respostas em tempo real sem acesso à nuvem. BAIR
Principais conclusões
- Modelos de linguagem pequenos podem ser treinados para realizar chamadas de função e orquestração de ferramentas para IA no edge, reduzindo a dependência de inferência na nuvem. BAIR
- Dados curados de alta qualidade e ajuste fino direcionado podem melhorar significativamente as capacidades de chamada de função em modelos compactos, com potencial para superar referências maiores nessa tarefa. BAIR
- Tool RAG é apresentado como uma abordagem de eficiência para chamadas de função em ambientes de borda. BAIR
- A abordagem enfatiza a orquestração determinística de funções em vez de depender de conhecimento geral memorizado, alinhando-se a casos de uso de edge privado. BAIR
- O projeto está disponível como código aberto, permitindo que terceiros construam soluções de IA privadas e de baixa latência em hardware local. TinyAgent no GitHub
FAQ
-
Qual é o objetivo do TinyAgent?
Permitir que modelos de linguagem pequenos realizem chamadas de função e orchestration de ferramentas no edge, apoiando implantação privada e offline. [BAIR](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent)
-
Como os dados são gerados e validados?
Dados sintéticos são gerados com um LLM (GPT‑4‑Turbo) para produzir consultas realistas e planos de chamadas de função, seguidos de verificações de sanidade para confirmar a viabilidade do plano e a correção dos nomes/funções. O conjunto tem 80K treino, 1K validação e 1K teste, com custo de cerca de US$ 500. [BAIR](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent)
-
O que é Tool RAG?
Tool Retrieval-Augmented Generation, um método para aumentar a eficiência do processamento de chamadas de função em borda. [BAIR](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent)
-
ue hardware/modelos foram demonstrados?
Demonstração com TinyAgent‑1B e Whisper‑v3 rodando localmente em um MacBook M3 Pro, mostrando resposta em tempo real sem nuvem. [BAIR](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent)
Referências
More news

Otimize o acesso a alterações de conteúdo ISO-rating com Verisk Rating Insights e Amazon Bedrock
Verisk Rating Insights, impulsionado pelo Amazon Bedrock, LLMs e RAG, oferece uma interface conversacional para acessar mudanças ERC ISO, reduzindo downloads manuais e aumentando a velocidade e a precisão das informações.

Automatize pipelines RAG avançadas com SageMaker AI da AWS
Aperfeiçoe a experimentação até a produção para Retrieval Augmented Generation (RAG) com SageMaker AI, MLflow e Pipelines, promovendo fluxos reprodutíveis, escaláveis e com governança.

Desbloqueie insights do modelo com suporte a probabilidades de log para Importação de Modelo Personalizado no Amazon Bedrock
Explica dados de confiança por token para modelos importados do Bedrock via probabilidades de log, como habilitar e aplicações práticas.

Implante Inferência de IA Escalável com NVIDIA NIM Operator 3.0.0
O NVIDIA NIM Operator 3.0.0 amplia a inferência de IA escalável no Kubernetes, permitindo implantações multi-LLM e multi-nó, integração com KServe e suporte a DRA em modo de tecnologia, com colaboração da Red Hat e NeMo Guardrails.

Implantar bases de conhecimento do Amazon Bedrock com Terraform para aplicações de IA generativa baseadas em RAG
Automatize a implantação de bases de conhecimento Bedrock e conexões de fontes de dados para fluxos RAG com um template Terraform IaC, permitindo setups rápidos e reproducíveis em produção.
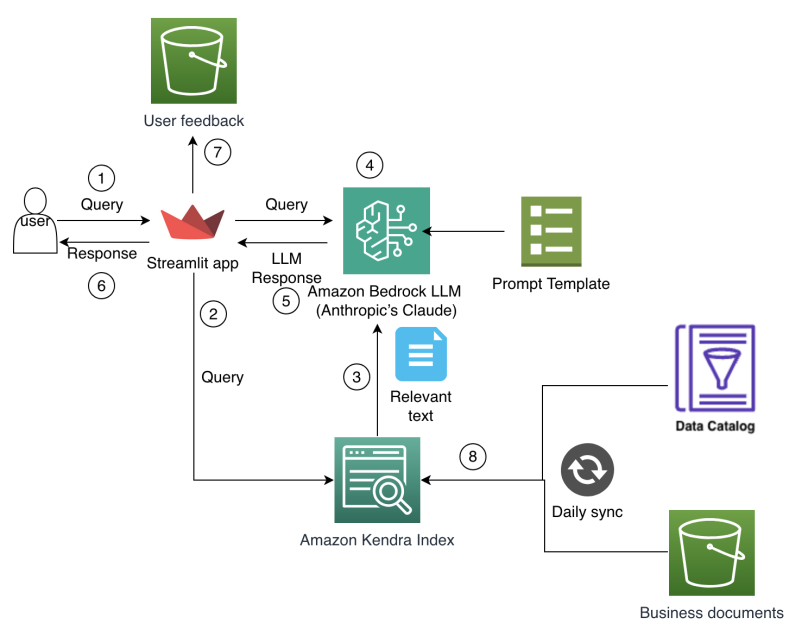
Como o Amazon Finance construiu um assistente de IA usando Amazon Bedrock e Amazon Kendra para apoiar analistas na descoberta de dados e insights de negócios
O Amazon Finance detalha um assistente de IA que combina Bedrock e Kendra para acelerar a descoberta de dados, preservar o conhecimento institucional e entregar insights financeiros precisos em escala.