Modelando Imagens Extremamente Grandas com xT: Visão de ponta a ponta em imagens de escala gigapixel
Sources: http://bair.berkeley.edu/blog/2024/03/21/xt, bair.berkeley.edu
TL;DR
- xT introduz tokenização aninhada para dividir imagens muito grandes em peças gerenciáveis, mantendo o contexto global.
- Ele combina encoders de região, que operam em patches locais, com um encoder de contexto que costura esses patches juntos ao longo de sequências longas.
- A abordagem permite processamento de ponta a ponta em GPUs modernas e pode lidar com imagens de até 29.000 × 25.000 pixels em A100 de 40 GB.
- Em avaliações com tarefas desafiadoras, xT atinge maior precisão com menos parâmetros e menor memória por região do que muitas bases.
- O trabalho aponta para modelos que enxergam tanto a floresta quanto as árvores sem sacrificar detalhe ou alcance contextual. source
Contexto e antecedentes
Imagens grandes não são mais incomuns em aplicações modernas, desde câmeras de bolso até imagens de satélite e médicas. Conforme o tamanho da imagem aumenta, o uso de memória tende a crescer de forma quadrática, criando um gargalo para os melhores modelos de visão e para o hardware disponível. Opções tradicionais incluem redimensionamento ou recorte, ambos com perda de informação ou contexto. Esse cenário motiva uma nova abordagem para lidar com imagens grandes de ponta a ponta em GPUs atuais sem comprometer detalhes ou compreensão global. Os autores apresentam o xT como uma estrutura baseada em tokenização aninhada, uma forma hierárquica de tokenização que divide uma imagem em regiões que podem ser subdivididas, permitindo análise local e integração global. source
O que há de novo
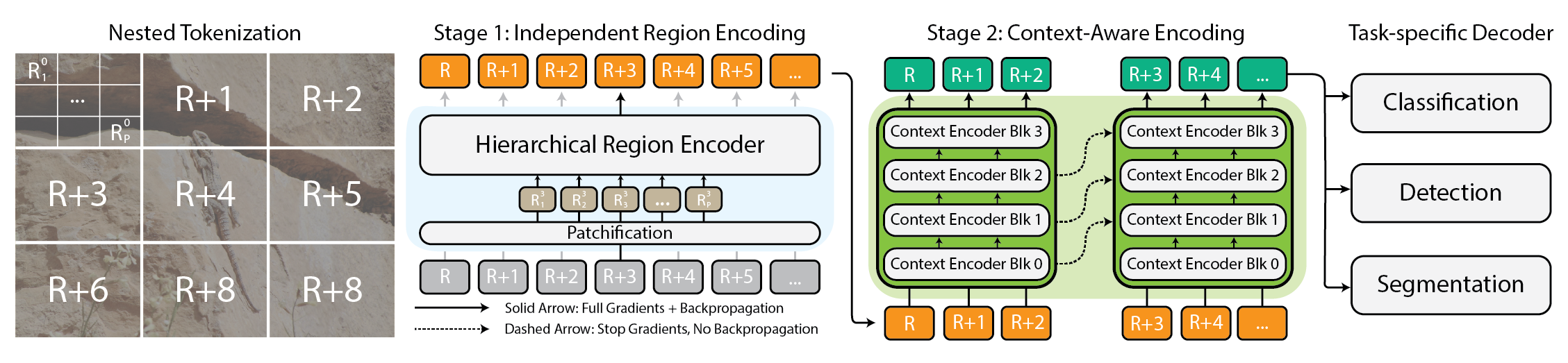
No cerne do xT está a tokenização aninhada, que divide uma imagem em regiões em várias escalas, depois tokeniza cada região para que um region encoder possa operar com detalhes locais. A concepção gera dois fluxos complementares:
- Um region encoder que funciona como um especialista local, convertendo regiões independentes em representações detalhadas. Pode ser qualquer backbone de visão de ponta, incluindo Swin, Hiera e ConvNeXt.
- Um context encoder que, ao trabalhar com as representações detalhadas das regiões, costura as informações para entender a imagem como um todo. O context encoder normalmente é um modelo de sequência longa; o artigo testa Transformer-XL e uma variante chamada Hyper, além de Mamba, sugerindo que modelos de linguagem também podem ser eficazes em tarefas de visão. O sistema combinado permite processar imagens grandes de forma end-to-end em GPUs modernas preservando detalhes locais e coerência global. source A afirmação central é que essa combinação permite modelar imagens com até 29.000 × 25.000 pixels em A100s com 40 GB, enquanto baselines comparáveis lutam com a memória em tamanhos muito menores. A abordagem é demonstrada em tarefas desafiadoras para mostrar versatilidade: iNaturalist 2018 para classificação de espécies de granulação fina, xView3-SAR para segmentação dependente do contexto e MS-COCO para detecção. Em todas as tarefas, xT com backbones adequados e modelos de contexto obtém maior precisão com menos parâmetros e com muito menos memória por região do que alguns baselines de ponta. source
Por que isso importa (impacto para desenvolvedores/empresas)
Este trabalho se posiciona como um avanço prático para cientistas e profissionais que precisam de modelos capazes de entender tanto o contexto amplo quanto os detalhes finos de imagens muito grandes. Em monitoramento ambiental, saúde e outras áreas que exigem capturar tendências amplas sem perder patches locais, xT oferece um caminho para uma compreensão de cena mais completa sem os gargalos de memória habituais. Os autores ressaltam que, embora não afirmem resolver todos os problemas de uma vez, o xT abre a porta para trabalhar com imagens ainda maiores e mais complexas de forma end-to-end em hardware atual, possibilitando análises mais ricas e detecções mais precoces em domínios como monitoramento climático e diagnóstico médico. source
Detalhes técnicos ou Implementação
A arquitetura baseia-se em três ideias-chave: tokenização aninhada, encoders de região e encoders de contexto. A tokenização aninhada quebra a imagem em regiões em várias escalas, tokeniza cada região e, em seguida, utiliza um region encoder para obter representações locais. Depois, o context encoder combina essas representações para restituir a estrutura global e dependências de longo alcance. O region encoder funciona como um especialista local e pode usar backbones variados, incluindo Swin, Hiera e ConvNeXt. O context encoder, geralmente um modelo de sequência longa, pega as saídas das regiões e raciocina sobre toda a imagem; o paper testa Transformer-XL e uma variante chamada Hyper, com Mamba como outra opção, mostrando que uma abordagem de modelo de linguagem pode ser aplicada a tarefas de visão. O sistema permite treinamento e inferência end-to-end, mantendo o consumo de memória compatível com GPUs modernas enquanto enfrenta imagens muito maiores do que pipelines tradicionais. As avaliações utilizam tarefas padrão como iNaturalist 2018, xView3-SAR e MS-COCO para demonstrar melhorias em precisão e eficiência. source | Aspecto | Tratamento tradicional de imagens grandes | Abordagem com xT |---|---|---| | Escala de memória | Crescimento quadrático com o tamanho da imagem | Processamento end-to-end em GPUs com tokenização aninhada |Granularidade de processamento | Recorte ou redimensionamento | Encoders de região mais encoder de contexto |Backbones usados | Diversos backbones | Swin, Hiera, ConvNeXt para region encoders; Transformer-XL, Hyper, Mamba para context |Tarefas-alvo | Baselines de CV gerais | iNaturalist 2018, xView3-SAR, MS-COCO |Requisito de hardware | Memória moderada a alta | Demonstração em 40 GB A100s para imagens muito grandes |
Pontos-chave
- A tokenização aninhada permite lidar com imagens extremamente grandes dividindo-as em regiões e sub-regiões próprias para processamento local e integração global. source
- A arquitetura de dois fluxos, encoders de região e um encoder de contexto, permite capturar detalhes locais e coerência global sem sacrificar a visão global da cena. source
- A estrutura mostra benefícios práticos de memória e precisão em tarefas desafiadoras, permitindo modelar imagens de tamanho gigapixel com GPUs modernas. source
- Embora não seja a solução para todos os problemas, o xT representa um avanço significativo para imagens grandes e complexas em visão computacional. source
Perguntas frequentes
-
O que é o xT em termos simples?
Uma estrutura que modela imagens extremamente grandes de ponta a ponta dividindo-as em regiões, processando-as com encoders de região e reunindo tudo com um encoder de contexto para considerar dependências de longo alcance. [source](http://bair.berkeley.edu/blog/2024/03/21/xt)
-
Como funciona a tokenização aninhada na prática?
Ela divide a imagem em regiões em várias escalas, tokeniza cada região e usa um region encoder para obter representações locais antes de um context encoder integrar informações entre regiões. [source](http://bair.berkeley.edu/blog/2024/03/21/xt)
-
ue hardware é necessário para rodar o xT com eficácia?
O método é projetado para rodar end-to-end em GPUs modernas e demonstrou lidar com imagens de até 29.000 × 25.000 pixels em 40 GB A100s. [source](http://bair.berkeley.edu/blog/2024/03/21/xt)
-
Em quais tarefas o xT foi avaliado?
iNaturalist 2018 para classificação de espécies de granulação fina, xView3-SAR para segmentação dependente de contexto e MS-COCO para detecção. [source](http://bair.berkeley.edu/blog/2024/03/21/xt)
Referências
More news

NVIDIA HGX B200 reduz a Intensidade de Emissões de Carbono Incorporado
O HGX B200 da NVIDIA reduz 24% da intensidade de carbono incorporado em relação ao HGX H100, ao mesmo tempo em que aumenta o desempenho de IA e a eficiência energética. Esta análise resume os dados de PCF e as novidades de hardware.

Playbook dos Grandmasters do Kaggle: 7 Técnicas de Modelagem Testadas para Dados Tabulares
Análise detalhada de sete técnicas testadas por Grandmasters do Kaggle para resolver grandes conjuntos de dados tabulares com aceleração por GPU, desde baselines diversificados até ensemble avançado e pseudo-rotulagem.

Como reduzir gargalos do KV Cache com NVIDIA Dynamo
O Dynamo da NVIDIA transfere o KV Cache da memória da GPU para armazenamento de custo mais baixo, permitindo janelas de contexto maiores, maior concorrência e menor custo de inferência em grandes modelos.

Microsoft transforma site da Foxconn no data center Fairwater AI, considerado o mais poderoso do mundo
A Microsoft divulga planos para um data center Fairwater AI de 1,2 milhão de pés quadrados no Wisconsin, com centenas de milhares de GPUs Nvidia GB200. projeto de US$ 3,3 bilhões promete treinamento de IA em escala sem precedentes.

NVIDIA RAPIDS 25.08 Adiciona Novo Profiler para cuML, Melhorias no Motor GPU Polars e Suporte Ampliado de Algoritmos
RAPIDS 25.08 traz profiladores function-level e line-level para cuml.accel, executor streaming padrão no motor GPU Polars, suporte ampliado de tipos e strings, novo Spectral Embedding no cuML e acelerações com zero código para mais algoritmos.

Decodificação Especulativa para Reduzir a Latência na Inferência de IA: EAGLE-3, MTP e Abordagens Draft-Target
Exploração detalhada de decodificação especulativa para inferência de IA, incluindo métodos draft-target e EAGLE-3, como reduzem latência e como implantar em GPUs NVIDIA com TensorRT.