As embeddings de texto codificam o texto perfeitamente? vec2text mostra alto potencial de inversão
Sources: https://thegradient.pub/text-embedding-inversion, thegradient.pub
TL;DR
- Embeddings de texto podem ser invertidos para recuperar o texto com alta fidelidade usando uma abordagem de otimização aprendida chamada vec2text. The Gradient.
- Em experimentos controlados, uma entrada de 32 tokens mapeia para um embedding de 768 dimensões, totalizando cerca de 24.576 bits (aproximadamente 3 KB); a inversão pode recuperar grande parte do texto e frequentemente alcançar reconstrução quase perfeita após refinamento iterativo.
- Os resultados levantam questões de segurança e privacidade para armazenamento de embeddings e sistemas do tipo RAG, onde o conjunto de dados armazena apenas vetores, não o texto cru. The Gradient.
Contexto e antecedentes
Retrieval Augmented Generation (RAG) tornou-se um padrão comum para construir sistemas de IA que ajudam na informação. Esses sistemas armazenam documentos em um banco de dados, recuperam os itens mais relevantes comparando vetores de embedding e, em seguida, geram respostas informadas pelos documentos recuperados. Os embeddings são projetados para codificar similaridade semântica, mas não há garantias de preservar o texto exato ou de reconstruir a entrada original. A ideia de que funções não aumentam a informação de entrada, apenas a mantêm ou reduzem, é um ponto de referência da teoria de processamento de dados. Em redes neurais profundas, camadas e não linearidades (como ReLU) reduzem ainda mais a informação recuperável, o que dificulta a recuperação exata de dados originais. Isso se relaciona à observação de que a recuperação de informações de representações profundas já foi explorada na visão computacional, com resultados que mostram possibilidades de reconstrução de entradas a partir de representações de alto nível. The Gradient. Para ilustrar com um problema simples, considere 32 tokens de texto embutidos em um vetor de 768 dimensões. Em precisão de 32 bits, esse embedding tem cerca de 24.576 bits, aproximadamente 3 KB. A pergunta central é se é possível reconstruir perfeitamente o texto a partir desse vetor, dado que o embedding foi desenhado para semântica e recuperação, não para reversão exata. O estudo também discute como resultados em visão computacional influenciam a interpretação de representações de texto. The Gradient. O estudo que embasa essa discussão é apresentado na obra Text Embeddings Reveal As Much as Text (EMNLP 2023). A pergunta-chave é se é possível recuperar o texto a partir de embeddings de saída. A investigação enfatiza que, embora os embeddings sejam destinados à semelharidade, eles podem conter informações suficientes para reconstruir, ao menos parcialmente, o texto original. The Gradient.
O que há de novo
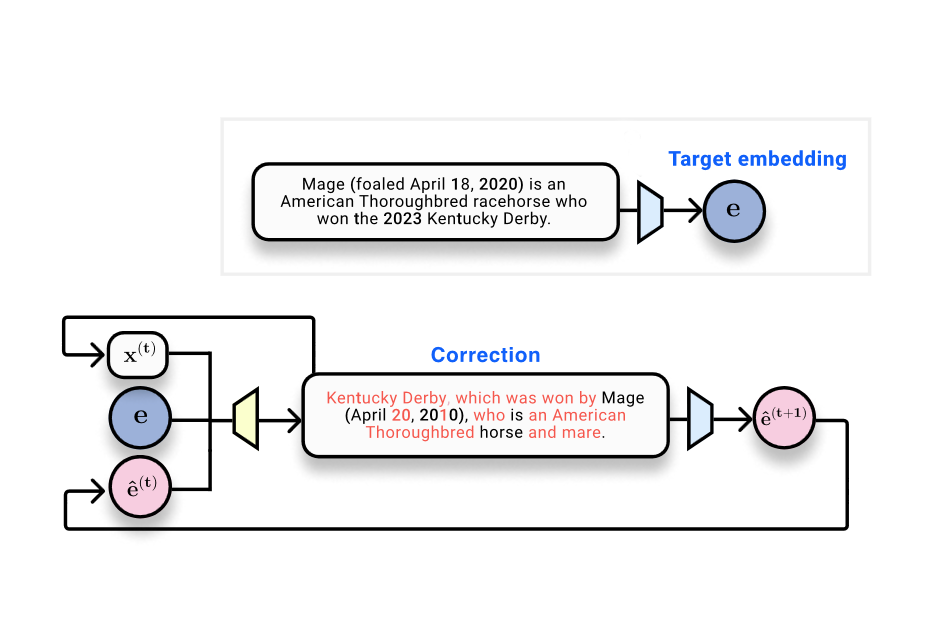
O trabalho apresenta vec2text, uma abordagem que trata a inversão de embeddings como um problema de otimização aprendida. A ideia é partir de um embedding-alvo (o objetivo) e de uma hipótese de texto com seu embedding (o estado atual), treinando um modelo corretor para mover a hipótese em direção ao ground truth no espaço de embedding. Trata-se de uma forma de otimização discreta em sequências de texto, guiada pela distância até o embedding de referência. Os autores relatam uma melhoria marcante: um único passo corretivo eleva o BLEU de cerca de 30/100 para cerca de 50, indicando melhora substancial na correspondência do conteúdo, embora a fidelidade exata da ordem das palavras ainda seja imperfecta após um único passo. Um insight-chave é avaliar a qualidade da inversão através do espaço de embedding, em vez de tentar reconstruir o texto exato em uma única passagem. Quando o texto gerado é re-embedding e comparado com o embedding original, a similaridade coseno é muito alta, por volta de 0,97, o que mostra que o hipótese reside próximo no espaço de embedding, mesmo que o texto não seja idêntico. Essa observação motiva um processo iterativo de refinamento: gere uma hipótese, re-embed, refine novamente. Esse fluxo está no cerne da abordagem vec2text. The Gradient. Com várias etapas de refinamento, os autores relatam resultados impressionantes: após 50 passos e alguns truques, é possível recuperar aproximadamente 92% de sequências de 32 tokens com exatidão e obter BLEU próximo de 97. Em outras palavras, a abordagem pode reconstruir quase todas as sentenças com alta fidelidade estrutural, com pequenas diferenças de pontuação em alguns casos. The Gradient.
Observações sobre métricas de precisão
Os autores comparam exatidão absoluta e semelhança no espaço de embedding. O modelo inicial não conseguiu exatidão, mas a semelhança com o embedding original ficou em torno de 0,97. Isso motiva uma visão de que a recuperação em embedding space pode ser extremamente informativa, ainda que não garanta a cópia textual exata em todos os casos. The Gradient.
Tabela de métricas-chave (principais)
| Métrica | Valor |
|---|---|
| Contagem de tokens de entrada | 32 tokens |
| Dimensionalidade do embedding | 768 dims |
| Bits no embedding (aprox.) | 24.576 bits (~3 KB) |
| BLEU (modelo de inversão inicial) | ~30/100 |
| BLEU (após correção) | ~50 |
| Exata após 50 passos | ~92% |
| BLEU final (iteração) | ~97 |
Por que isso importa (impacto para desenvolvedores/empresas)
Os resultados têm implicações diretas para desenvolvedores e organizações que dependem de armazenamento e recuperação baseados em embeddings. Bancos de embeddings e bancos de dados vetoriais, comumente usados para alimentar pipelines RAG, armazenam apenas vetores ao invés do texto cru. Se embeddings puderem ser invertidos para recuperar texto, surgem riscos de privacidade e segurança se o acesso às embeddings não for devidamente controlado. A possibilidade de reconstrução de conteúdo sensível a partir de dados de embedding exige uma reavaliação das políticas de segurança e de como os dados são protegidos em ambientes de produção. The Gradient.
Detalhes técnicos ou Implementação (o que entender para implementação)
- Processo de embedding e o problema-modelo: o estudo começa descrevendo um cenário simples onde 32 tokens são embutidos em um vetor de 768 dimensões. Em precisão de 32 bits, isso soma cerca de 24.576 bits, ou aproximadamente 3 KB, destacando que a representação é relativamente compacta em relação ao texto original.
- Estratégia de inversão: em vez de tentar uma reversão direta, os autores propõem vec2text, um framework de otimização aprendida. Eles treinam um transformer que mapeia embeddings para texto, obtendo inicialmente um BLEU de cerca de 30/100, porém com quase nenhuma correspondência exata entre entrada e saída. A virada ocorre ao tratar o problema como refinamento iterativo: gerar uma hipótese, re-embedá-la e usar um corretor para aproximar o texto da sequência original.
- Proximidade no embedding como guia: a observação central é que, mesmo que o texto gerado em uma passagem não seja idêntico, o embedding resultante pode ficar muito próximo do embedding original, permitindo um processo de refinamento. Isso permite que o sistema melhore com múltiplas iterações. The Gradient.
- Recursividade na prática: o método é naturalmente recursivo. Repetindo a geração de hipóteses, a re-embedding e a alimentação de volta ao corretor, os resultados melhoram com o tempo. Com 50 passos e algumas técnicas adicionais, é possível obter alta fidelidade para entradas de 32 tokens.
- Observação sobre estabilidade e colisões: se o espaço de embedding fosse tão lossy a ponto de mapear várias entradas para o mesmo embedding, a inversão seria inviável. Nos experimentos, esse tipo de colisão não foi observado, o que sustenta a viabilidade do approach em cenários estudados. The Gradient.
Observações para implementação prática
- A abordagem demonstra como um embedding de referência, uma hipótese de texto e o embedding correspondente podem ser usados para treinar um modelo corretor que aproxima o texto da verdade.
- O processo funciona como uma sequência de passos discretos em espaço de texto, guiados pela distância em embedding, ilustrando um paradigma híbrido de aprendizado e otimização.
- Em produção, é crucial considerar controles de acesso, criptografia de stores de embeddings e políticas de compartilhamento para evitar vazamentos de conteúdo sensível por meio de embeddings expostos. Essas considerações são centrais para como bancos de vetores são protegidos em fluxos reais. The Gradient.
Principais aprendizados
- Embeddings não são intrinsecamente opacos: podem manter informações significativas sobre o texto original, possibilitando reconstrução sob refinamento iterativo.
- vec2text demonstra que uma otimização de aprendizado cuidadosa pode recuperar, para entradas de 32 tokens, o texto a partir de embeddings de 768 dimensões, com altos scores de BLEU e taxas de correspondência exata muito altas após várias etapas.
- Os resultados reforçam considerações de segurança para armazenamentos de vetores e para políticas de acesso em pipelines que dependem de embeddings.
- A viabilidade da inversão depende do tamanho e da complexidade do texto; textos mais longos podem ser mais desafiadores para reconstrução exata, ainda que permaneçam informativos no espaço de embedding.
- O estudo contribui para o debate sobre a natureza da informação presente em representações profundas e destaca a necessidade de avaliação contínua de riscos de privacidade em sistemas de dados baseados em IA.
FAQ
-
É possível recuperar perfeitamente o texto a partir de embeddings?
O estudo mostra recuperação quase perfeita para entradas de 32 tokens após iterações, com alta probabilidade de exatidão após várias etapas, mas não afirma exatidão em todos os casos.
-
O que é vec2text?
Vec2text é uma abordagem de otimização aprendida que usa embedding de referência, uma hipótese de texto e seu embedding para refinar progressivamente o texto até se aproximar do ground truth.
-
Por que isso importa para segurança?
Se embeddings podem ser invertidos para recuperar texto, há riscos de privacidade e vazamento de conteúdo quando vetores são acessíveis, exigindo revisão de políticas de segurança.
-
Existem limites práticos para inversão?
Textos mais longos ou mais complexos podem não ter exatidão total, mas a recuperação em espaço de embedding continua sendo informativa, possibilitando reconstrução poderosa para textos moderados.
Referências
More news

Otimize o acesso a alterações de conteúdo ISO-rating com Verisk Rating Insights e Amazon Bedrock
Verisk Rating Insights, impulsionado pelo Amazon Bedrock, LLMs e RAG, oferece uma interface conversacional para acessar mudanças ERC ISO, reduzindo downloads manuais e aumentando a velocidade e a precisão das informações.

Automatize pipelines RAG avançadas com SageMaker AI da AWS
Aperfeiçoe a experimentação até a produção para Retrieval Augmented Generation (RAG) com SageMaker AI, MLflow e Pipelines, promovendo fluxos reprodutíveis, escaláveis e com governança.

Desbloqueie insights do modelo com suporte a probabilidades de log para Importação de Modelo Personalizado no Amazon Bedrock
Explica dados de confiança por token para modelos importados do Bedrock via probabilidades de log, como habilitar e aplicações práticas.

Implante Inferência de IA Escalável com NVIDIA NIM Operator 3.0.0
O NVIDIA NIM Operator 3.0.0 amplia a inferência de IA escalável no Kubernetes, permitindo implantações multi-LLM e multi-nó, integração com KServe e suporte a DRA em modo de tecnologia, com colaboração da Red Hat e NeMo Guardrails.

Implantar bases de conhecimento do Amazon Bedrock com Terraform para aplicações de IA generativa baseadas em RAG
Automatize a implantação de bases de conhecimento Bedrock e conexões de fontes de dados para fluxos RAG com um template Terraform IaC, permitindo setups rápidos e reproducíveis em produção.
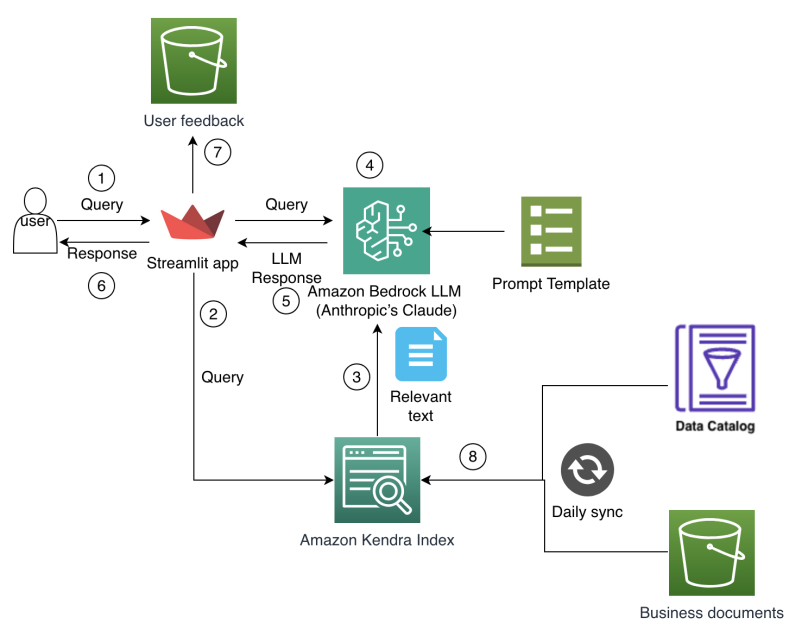
Como o Amazon Finance construiu um assistente de IA usando Amazon Bedrock e Amazon Kendra para apoiar analistas na descoberta de dados e insights de negócios
O Amazon Finance detalha um assistente de IA que combina Bedrock e Kendra para acelerar a descoberta de dados, preservar o conhecimento institucional e entregar insights financeiros precisos em escala.