Planifier des charges de travail sensibles à la topologie avec SageMaker HyperPod
Sources: https://aws.amazon.com/blogs/machine-learning/schedule-topology-aware-workloads-using-amazon-sagemaker-hyperpod-task-governance, https://aws.amazon.com/blogs/machine-learning/schedule-topology-aware-workloads-using-amazon-sagemaker-hyperpod-task-governance/, AWS ML Blog
TL;DR
- AWS annonce une planification sensible à la topologie comme nouvelle capacité de la gouvernance des tâches SageMaker HyperPod, afin d’optimiser l’efficacité de l’entraînement et la latence réseau sur les clusters Amazon EKS.
- Cette approche exploite les informations de topologie EC2 pour placer des tâches d’entraînement interconnectées au sein des mêmes nœuds et couches réseau, réduisant les sauts réseau et la latence.
- Il existe deux méthodes principales de soumission des charges sensibles à la topologie : annoter les manifestes Kubernetes avec une annotation topologique et utiliser l’outil CLI SageMaker HyperPod avec des options liées à la topologie.
- Le flux de travail comprend la vérification des informations de topologie, l’identification des nœuds partageant des couches réseau et la soumission des tâches d’entrainement sensibles à la topologie pour gagner en visibilité et en contrôle.
- L’article propose des étapes pratiques, un aperçu de la topologie et invite les utilisateurs à donner leur avis.
Contexte et contexte historique
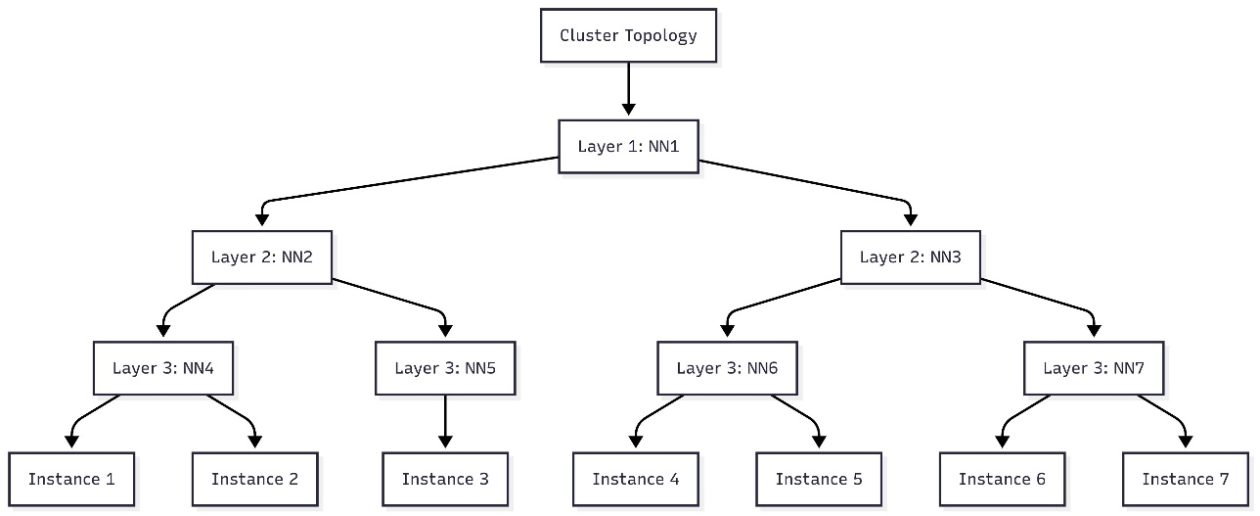
Les charges de travail d’IA générative nécessitent souvent une communication étendue entre les nœuds EC2. Dans ces environnements, la latence réseau est influencée par la façon dont les instances sont physiquement et logiquement placées dans la topologie hiérarchique d’un centre de données. AWS décrit les centres comme organisés en unités logiques imbriquées, telles que les nœuds et les ensembles de nœuds, avec plusieurs instances par nœud et plusieurs nœuds par ensemble. Les instances partageant des nœuds réseau plus proches présentent des temps de traitement plus courts en raison de moindres sauts réseau. Pour optimiser le placement des charges de travail IA dans les clusters SageMaker HyperPod, on peut intégrer les informations de topologie EC2 lors de la soumission des jobs. La topologie d’une instance EC2 est décrite par un ensemble de nœuds, avec un nœud dans chaque couche du réseau. La topologie est structurée sur plusieurs couches; le partage de couches informe sur la proximité et l’efficacité de la communication. Des étiquettes de topologie réseau permettent un planificateur sensible à la topologie qui améliore l’efficacité des tâches et l’utilisation des ressources. Dans ce contexte, la gouvernance des tâches HyperPod permet d’étendre la gouvernance à l’allocation accélérée des ressources et à l’application de politiques de priorité entre équipes et projets sur des clusters EKS. Cette gouvernance aide les administrateurs à aligner l’allocation des ressources sur les priorités organisationnelles, facilitant l’innovation en IA et accélérant le time-to-market en réduisant la coordination nécessaire pour provisionner les ressources et replanifier les tâches. Pour des conseils approfondis, AWS renvoie aux meilleures pratiques pour SageMaker HyperPod.
Nouvelles fonctionnalités
Cet article introduit l’acheminement sensible à la topologie comme capacité du SageMaker HyperPod Task Governance, afin d’optimiser l’efficacité de l’entraînement et le débit/la latence réseau en tenant compte de l’agencement physique et logique des ressources. Points clés :
- Planification sensible à la topologie qui utilise les informations de topologie EC2 pour orienter le placement des charges, les instances partageant les mêmes couches réseau étant proches.
- Les administrateurs peuvent gouverner l’allocation accélérée et appliquer des politiques de priorité pour améliorer l’utilisation des ressources.
- Les data scientists interagissent avec les clusters SageMaker HyperPod pour garantir les capacités et les permissions lors des travaux sur GPU.
- Deux méthodes de soumission et un flux de travail alternatif offrent de la flexibilité pour les équipes.
Deux méthodes principales de soumission (et un flux alternatif)
- Annotation dans les manifests Kubernetes : ajouter l’annotation de topologie kueue.x-k8s.io/podset-required-topology afin de programmer des pods qui partagent la même couche 3 du réseau. Pour vérifier où vos pods s’exécutent, utilisez :
- kubectl get pods -n hyperpod-ns-team-a -o wide
- CLI SageMaker HyperPod : soumettez des jobs via la CLI en utilisant soit —preferred-topology soit —required-topology lors de la création du job. Un exemple est présenté pour démarrer un entraînement MNIST sensible à la topologie avec un identifiant de compte AWS à remplacer (XXXXXXXXXXXX). L’article note également des considérations pratiques si vous déployez de nouvelles ressources et renvoie à la section Nettoyage du workshop SageMaker HyperPod EKS pour éviter des charges indésirables. Il souligne aussi que l’entraînement de grands modèles de langage (LLM) implique une communication importante entre les pods et que la topologie sensible peut améliorer le throughput et la latence.
Comment démarrer
Pour commencer, vous devez :
- Confirmer les informations de topologie pour tous les nœuds de votre cluster.
- Exécuter un script pour identifier les nœuds qui partagent des couches réseau entre les niveaux 1–3.
- Programmer les tâches d’entraînement sensibles à la topologie dans votre cluster via l’une des méthodes de soumission. Ce flux de travail vise à offrir une meilleure visibilité et un meilleur contrôle de la placement des tâches d’entraînement, ce qui peut conduire à des performances plus prévisibles pour les charges de travail distribuées en IA. L’article indique que les étiquettes de topologie réseau facilitent ces bénéfices et propose des visualisations (via Mermaid.js.org) pour aider à comprendre la topologie.
Pourquoi cela compte (impact pour développeurs/entreprises)
Le planificateur sensible à la topologie résout un facteur clé de performance pour l’entraînement distribué d’IA : la communication inter-nœuds. Pour les charges d’entrainement distribuées et en particulier les grands modèles, réduire les sauts réseau entre GPU sur des nœuds différents peut diminuer le temps d’entraînement et la latence de synchronisation. En intégrant les informations de topologie EC2 dans le SageMaker HyperPod Task Governance, les organisations peuvent :
- Améliorer l’utilisation des ressources en alignant le placement de calcul sur la proximité réseau.
- Simplifier la gouvernance de l’allocation des ressources accélérées entre équipes et projets.
- Accélérer le time-to-market des innovations IA en réduisant la coordination nécessaire pour provisionner des ressources et replanifier des tâches.
- Donner aux data scientists une meilleure visibilité sur l’emplacement des tâches, facilitant l’expérimentation et l’optimisation. Ces capacités sont particulièrement utiles pour les formations distribuées de grande échelle, où la communication entre pods est fréquente. La gouvernance vise à équilibrer performance (placement topologique) et contrôle administratif (politiques de priorité et gouvernance des ressources).
Détails techniques ou Mise en œuvre
Prérequis et configuration :
- Commencez par afficher les étiquettes de topologie des nœuds dans votre cluster. Une étiquette commune est topology.k8s.aws/network-node-layer-3; une sortie d’exemple peut être topology.k8s.aws/network-node-layer-3: nn-33333example, indiquant comment les instances sont organisées par couches.
- Utilisez un script pour identifier quels nœuds partagent des couches réseau entre les niveaux 1–3. La sortie peut être utilisée pour construire une visualisation de topologie (par exemple, avec Mermaid.js.org).
- Le document propose deux chemins pratiques pour soumettre des charges sensibles à la topologie :
- Annotation dans les manifests Kubernetes : ajoutez l’annotation kueue.x-k8s.io/podset-required-topology pour programmer des pods qui partagent la même couche 3 du réseau.
- CLI SageMaker HyperPod : utilisez la CLI HyperPod avec —preferred-topology ou —required-topology lors de la création d’un job. Cette approche permet un découpage basé sur la topologie dans la gouvernance HyperPod.
- Vérification de l’emplacement : après le lancement des pods, vérifiez l’allocation des nœuds avec kubectl get pods -n hyperpod-ns-team-a -o wide.
- L’article fournit un exemple de commande pour lancer un entraînement MNIST sensible à la topologie via la CLI HyperPod, en remplaçant XXXXXXXXXXXX par l’ID de votre compte AWS. L’objectif est d’illustrer le flux CLI, sans nécessairement reproduire exactement la commande. Remarques pratiques :
- Si vous avez déployé de nouvelles ressources lors de l’adoption du planificateur sensible à la topologie, suivez les recommandations de Nettoyage dans le workshop SageMaker HyperPod EKS pour éviter des coûts indésirables.
- Cette approche est particulièrement utile pour les entraînements de grands modèles de langage (LLM), où l’échange de données entre pods est fréquent.
- AWS met en avant que le planificateur sensible à la topologie peut faciliter une meilleure visibilité et un meilleur contrôle sur la placement des entraînements, ce qui peut se traduire par des performances plus prévisibles pour les workloads IA distribués.
Exemple pratique et visualisation
Le flux comprend la génération d’un diagramme qui montre comment les nœuds se relient entre les couches 1–3. Vous pouvez visualiser cette topologie dans des outils comme Mermaid.js.org pour planifier le placement des pods avant de soumettre des tâches sensibles à la topologie. L’exemple de cluster discuté dans l’article illustre comment sept instances s’alignent sur la topologie hiérarchique et guide les décisions concernant les couches réseau partagées.
Points à considérer lors de la mise en œuvre
- Décidez entre l’approche basée sur manifeste et celle via CLI, selon votre flux de travail et votre automatisation.
- Assurez-vous que votre équipe dispose des permissions pour interagir avec le cluster SageMaker HyperPod et pour annoter les ressources Kubernetes.
- Préparez une surveillance continue du placement par topologie et des métriques de performance pour valider les gains de throughput et de latence.
Points clés
- SageMaker HyperPod Task Governance prend en charge le planificateur sensible à la topologie pour améliorer l’efficacité de l’entraînement et la latence réseau.
- Le déploiement peut se faire via annotations de manifests Kubernetes ou via la CLI HyperPod, offrant une flexibilité selon les équipes.
- L’utilisation des informations de topologie EC2 guide le placement des pods sur des couches réseau partagées, réduisant les coûts de communication.
- Le flux de travail fournit une meilleure visibilité et un meilleur contrôle sur le placement des tâches d’entraînement, avec des performances plus prévisibles pour les workloads distribués.
- Cette approche est particulièrement bénéfique pour les entraînements distribués de grande dimension, où la communication entre pods est fréquente.
FAQ
Références
More news

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.

Prompting pour la précision avec Stability AI Image Services sur Amazon Bedrock
Bedrock intègre Stability AI Image Services avec neuf outils pour créer et modifier des images avec précision. Apprenez les techniques de prompting adaptées à l’entreprise.

Utiliser les AWS Deep Learning Containers avec SageMaker AI géré MLflow
Découvrez comment les AWS Deep Learning Containers (DLCs) s’intègrent à SageMaker AI géré par MLflow pour équilibrer le contrôle de l’infrastructure et une gouvernance ML robuste. Un flux TensorFlow pour la prédiction de l’âge des abalones illustre le suivi de bout en bout et la traçabilité des modè

Évoluer la production visuelle avec Stability AI Image Services dans Amazon Bedrock
Stability AI Image Services est désormais disponible dans Amazon Bedrock, offrant des capacités d’édition d’images prêtes à l’emploi via l’API Bedrock et étendant les modèles Stable Diffusion 3.5 et Stable Image Core/Ultra déjà présents.

Créer des flux de travail agentiques avec GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore
Vue d’ensemble complète sur le déploiement des modèles GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore pour alimenter un analyseur d’actions multi-agents avec LangGraph, incluant la quantification MXFP4 en 4 bits et une orchestration sans serveur.