Comment Skello utilise Amazon Bedrock pour interroger des données multitenantes avec des limites logiques
Sources: https://aws.amazon.com/blogs/machine-learning/how-skello-uses-amazon-bedrock-to-query-data-in-a-multi-tenant-environment-while-keeping-logical-boundaries, https://aws.amazon.com/blogs/machine-learning/how-skello-uses-amazon-bedrock-to-query-data-in-a-multi-tenant-environment-while-keeping-logical-boundaries/, AWS ML Blog
TL;DR
- Skello a construit un assistant IA avec Amazon Bedrock et AWS Lambda pour interroger des données dans un environnement multitenant tout en préservant des limites logiques strictes.
- La solution repose sur des schémas de données standardisés, une nomenclature cohérente et des vues pré-agrégées pour des réponses rapides et fiables.
- La sécurité est multi-niveaux : RBAC, authentification JWT/SAML, Bedrock SessionParameters et Bedrock Guardrails pour prévenir l’injection de prompts et le contenu inapproprié, alignés sur OWASP LLM06.
- Les frontières des données sont appliquées au niveau de la base de données et de l’API, avec des journaux d’audit immuables pour protéger les données des clients et assurer la conformité GDPR.
- Les visualisations sont générées automatiquement à partir des requêtes, simplifiant la narration des données pour des utilisateurs de profils variés.
Contexte et antécédents
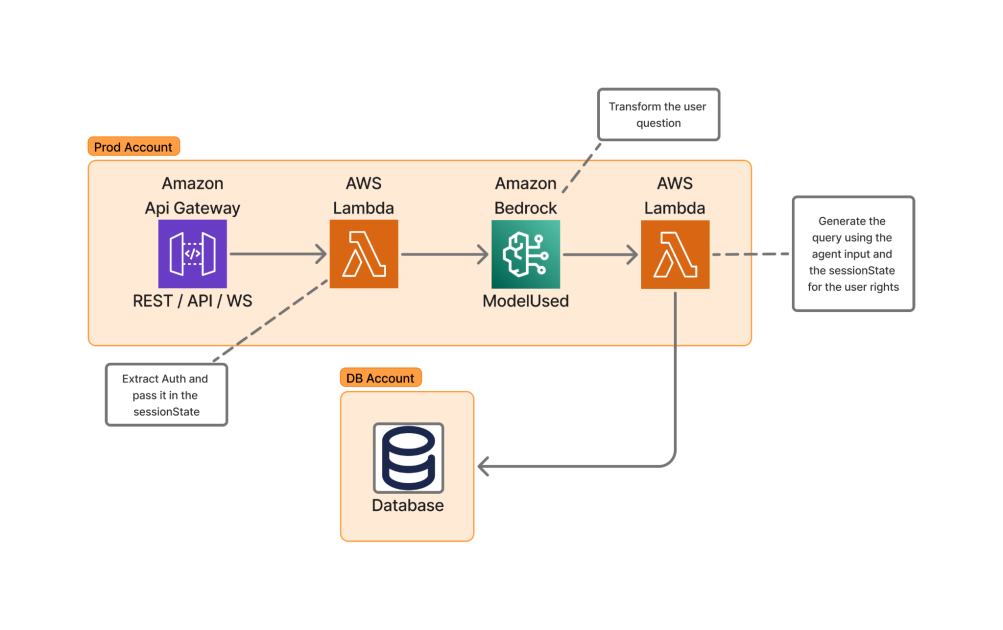
Skello est une plateforme RH SaaS axée sur la planification des employés et la gestion de la force de travail, desservant des secteurs tels que l’hôtellerie, la vente au détail, la santé, la construction et d’autres. D’ici 2024, Skello comptait environ 20 000 clients et 400 000 utilisateurs quotidiens en Europe. Face à la croissance, il était nécessaire d’accéder plus facilement aux données relatives à la main-d’œuvre. Les outils de requête traditionnels étaient trop techniques et longs pour de nombreux utilisateurs RH et opérationnels. Cela a conduit Skello à explorer comment les grands modèles de langage (LLMs) et l’IA générative pourraient traduire des questions en langage naturel en requêtes de base de données structurées, tout en respectant la protection des données et le GDPR. L’approche de Skello se fonde sur la transformation des demandes en langage naturel en requêtes de données structurées. L’architecture privilégie le maintien des frontières de données dans un environnement multitenant afin que les clients puissent interroger leurs propres données et recevoir des résultats précis sans exposer les données d’autres clients. La mise en œuvre s’appuie sur une architecture sans serveur autour d’AWS Lambda et d’Amazon Bedrock, un service géré qui donne accès à des modèles de base via une API unique, avec des garanties de sécurité et de confidentialité. Cet article explique les défis d’application des LLMs à l’interrogation de données, décrit comment Skello équilibre les capacités IA avec les exigences strictes de protection des données et montre comment Bedrock et Lambda ont été orchestrés pour un assistant IA prêt pour l’entreprise.
Quoi de neuf
L’innovation clé est l’assistant IA de Skello qui permet aux utilisateurs finaux d’interroger leurs propres données dans un environnement multitenant tout en maintenant des limites logiques claires et la conformité GDPR. L’architecture démontre comment traduire des requêtes en langage naturel en requêtes de base de données structurées, tout en veillant à ce que le contexte utilisateur et les autorisations restent en dehors du traitement LLM. Points forts :
- Architecture de haut niveau utilisant AWS Lambda et Amazon Bedrock pour transformer des questions en langage naturel en requêtes de base de données.
- Modélisation des données et stratégie organisationnelle avec des schémas standardisés, des formats cohérents pour les champs de date et des noms de champs clairs (p. ex. employee_type).
- Optimisation de la recherche et des vues : indexation selon l’usage et vues pré-agrégées pour les rapports fréquents, permettant des réponses quasi instantanées à des questions comme « Qui travaille aujourd’hui ? »
- Mesures de sécurité conformes à OWASP (LLM06) avec des services de sécurité dédiés pour l’authentification et l’autorisation, et des Bedrock SessionParameters pour le contexte utilisateur et Guardrails pour éviter les injections et le contenu inapproprié.
- Limites de données et compartimentation : isolation au niveau base de données et API, garantissant que les managers de département accèdent uniquement aux données de leur équipe, avec des journaux d’audit immuables.
- Génération automatique de visualisations professionnelles à partir des résultats, facilitant la narration des données. Par exemple, Skello montre une requête telle que « parité hommes-femmes » ou « heures travaillées par semaine par poste sur les 3 derniers mois », les résultats étant présentés sous forme de sorties structurées et de visualisations.
Pourquoi cela compte (impact pour les développeurs/entreprises)
Cette approche est pertinente pour les développeurs et les entreprises qui souhaitent exploiter l’IA pour accéder aux données dans des environnements multitenant sans compromettre la sécurité ou la régulation. Enjeux clés :
- Accès facilité aux données : les utilisateurs peuvent interroger leurs données en langage naturel, évitant SQL ou outils BI spécialisés et accélérant les décisions.
- Confidentialité et conformité : l’architecture assure des frontières strictes entre les données et conserve des journaux d’audit pour démontrer la conformité GDPR.
- Intégration IA sécurisée : en séparant les contrôles de sécurité de l’IA et en utilisant Bedrock SessionParameters et Guardrails, les risques IA sont atténués et l’utilisation responsable est favorisée.
- Modèles de données évolutifs et maintenables : schémas standardisés, dénominations claires et vues pré- agrégées améliorent les performances à mesure que le nombre de clients augmente.
- Visualisations rapides et accessibles : génération automatique de graphiques rend les insights plus accessibles à un plus large éventail d’utilisateurs. Ces résultats montrent comment une approche sans serveur associée à l’IA peut offrir un accès sécurisé et pratique aux données dans des environnements multitenant, tout en respectant les exigences de gouvernance et de confidentialité.
Détails techniques ou Mise en œuvre
La mise en œuvre repose sur une architecture serverless et une couche de données soigneusement conçue, complétée par des contrôles de sécurité et des mécanismes de gouvernance. Élément essentiels :
- Architecture serverless : AWS Lambda connecte les demandes des utilisateurs à Bedrock et retourne des requêtes structurées, offrant une évolutivité à la demande.
- Bedrock comme base IA : Amazon Bedrock donne accès à une variété de modèles de base via une API unique, permettant des capacités d’IA générative avec des garanties de sécurité et de confidentialité adaptées à l’entreprise.
- Modèle de données standardisé : schémas uniformes avec formats cohérents pour les champs de date et noms de champs conviviaux, comme employee_type, réduisant l’ambiguïté.
- Indexation et vues : indexation basée sur l’usage et vues pré-agrégées pour accélérer les rapports fréquents.
- Relations et contexte : relations claires entre les employés, les départements, les tournées et les responsables, permettant des requêtes complexes.
- Visualisation automatique : les résultats sont transformés en visualisations professionnelles intégrables dans des rapports et présentations.
- Sécurité et contrôle d’accès : conformité avec OWASP LLM06, authentification JWT/SAML et autorisation granulaire.
- Guardrails et sécurité des prompts : Guardrails Bedrock protègent contre l’injection de prompts et le contenu inapproprié.
- Limites et audit : isolation multitenant et journaux d’audit immutables enregistrant les actions avec horodatage et identifiant utilisateur.
- Considérations GDPR : l’approche équilibre IA et protection des données, avec isolation des clients et traçabilité.
Tableau de sécurité des données
| Aspect | Description |
|---|---|
| Schémas | Schémas standardisés, formats homogènes pour les dates, noms de champs clairs |
| Indexation | Pistes en fonction de l’usage pour accélérer les recherches courantes |
| Vues | Vues pré-agrégées pour les rapports fréquents |
| Sécurité | JWT/SAML, RBAC, Bedrock SessionParameters, Guardrails |
| Limites de données | Compartimentation base de données et API |
| Audit | Journaux immuables avec horodatage et identifiant utilisateur |
Points clés
- L’interrogation en langage naturel peut produire des requêtes structurées sans exposer de données d’autres clients.
- Les schémas standardisés et les vues pré-agrégées améliorent performance et précision pour les cas RH courants.
- Les contrôles de sécurité multicouches et la séparation des contrôles de sécurité et IA renforcent la sécurité.
- L’audit immuable et le RBAC assurent traçabilité et conformité GDPR dans un environnement multitenant.
- Les visualisations automatiques démocratisent l’accès aux insights et soutiennent la prise de décision.
FAQ
-
- **Q : Quel est le rôle d’Amazon Bedrock dans la solution Skello ?**
Bedrock offre un accès à des modèles de base via une API unique, permettant des capacités IA génératives avec des garanties de sécurité et de confidentialité adaptées à l’entreprise. - **Q : Comment les limites de données sont-elles assurées dans un environnement multitenant ?** **A :** Des frontières s’appliquent au niveau base de données et API, avec compartimentation, RBAC et journaux d’audit immuables pour empêcher les fuites entre clients. - **Q : Quelles mesures de sécurité protègent les composants IA ?** **A :** Respect du OWASP LLM06, services de sécurité dédiés pour l’authentification et l’autorisation, Bedrock SessionParameters pour le contexte utilisateur et Guardrails pour éviter les prompts dangereux. - **Q : Comment les schémas standardisés améliorent-ils l’utilisabilité ?** **A :** Des noms de champs clairs et des formats cohérents réduisent l’ambiguïté, facilitant la compréhension des requêtes par l’IA et la rapidité des résultats.
Références
More news

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.

Prompting pour la précision avec Stability AI Image Services sur Amazon Bedrock
Bedrock intègre Stability AI Image Services avec neuf outils pour créer et modifier des images avec précision. Apprenez les techniques de prompting adaptées à l’entreprise.

Utiliser les AWS Deep Learning Containers avec SageMaker AI géré MLflow
Découvrez comment les AWS Deep Learning Containers (DLCs) s’intègrent à SageMaker AI géré par MLflow pour équilibrer le contrôle de l’infrastructure et une gouvernance ML robuste. Un flux TensorFlow pour la prédiction de l’âge des abalones illustre le suivi de bout en bout et la traçabilité des modè

Évoluer la production visuelle avec Stability AI Image Services dans Amazon Bedrock
Stability AI Image Services est désormais disponible dans Amazon Bedrock, offrant des capacités d’édition d’images prêtes à l’emploi via l’API Bedrock et étendant les modèles Stable Diffusion 3.5 et Stable Image Core/Ultra déjà présents.

Créer des flux de travail agentiques avec GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore
Vue d’ensemble complète sur le déploiement des modèles GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore pour alimenter un analyseur d’actions multi-agents avec LangGraph, incluant la quantification MXFP4 en 4 bits et une orchestration sans serveur.