Oldcastle accélère le traitement des documents avec Amazon Bedrock et Textract
Sources: https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock, https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/, AWS ML Blog
TL;DR
- Oldcastle APG traite entre 100 000 et 300 000 billets d’expédition par mois dans plus de 200 installations, une tâche auparavant entravée par un OCR peu fiable. AWS ML Blog
- L’entreprise est passée à un flux de travail de bout en bout piloté par les événements, utilisant Amazon SES, les Notifications d’événements S3, Textract et Amazon Bedrock pour automatiser le traitement des documents POD. AWS ML Blog
- Bedrock, associé à Textract, a offert un traitement par lots rentable et une extraction cohérente des champs sur des formats de documents similaires, réduisant l’intervention manuelle. AWS ML Blog
- Oldcastle envisage une expansion vers les factures fournisseurs, la validation W-9 et les flux d’approbation automatique des documents, ce qui montre une trajectoire évolutive pour le traitement documentaire par IA. AWS ML Blog
Contexte et antécédents
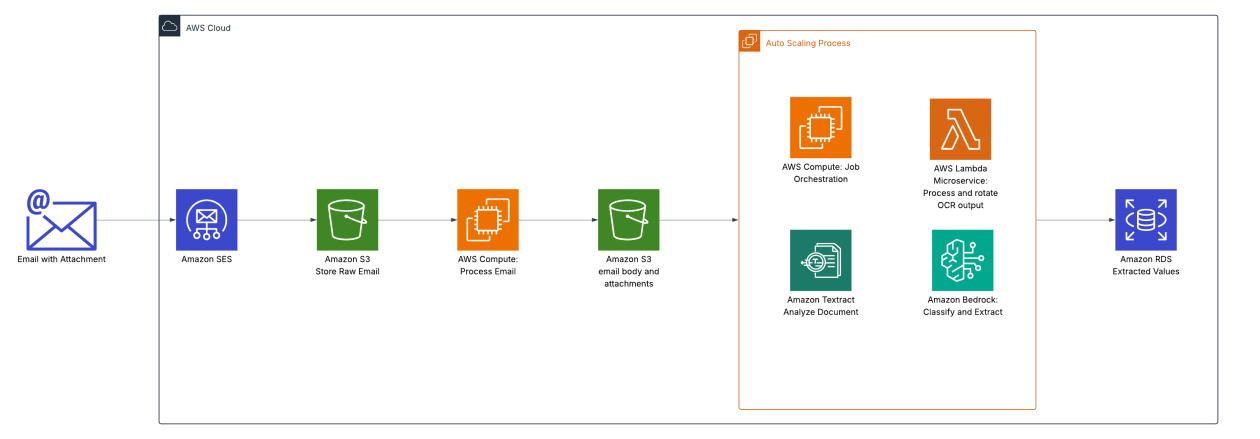
Oldcastle APG, l’un des plus grands réseaux mondiaux dans l’industrie des produits architecturaux, était confronté à un processus lourd et sujet à erreurs pour le traitement des documents de preuve de livraison (POD), connus sous le nom de tickets d’expédition. Le système OCR existant était peu fiable et nécessitait une maintenance constante et une intervention manuelle. Le résultat était une précision faible, une utilisation élevée des ressources et des retards dans plus de 200 installations. Le défi était double : automatiser le traitement des POD et mettre en place une solution pour traiter les factures fournisseurs et les faire correspondre aux commandes d’achat, compte tenu de la variabilité des formats. AWS ML Blog L’exploitation dépendait d’employés sur site consacrant 4 à 5 heures par jour au traitement des billets. L’équipe IT supportait la maintenance continue et le développement pour faire fonctionner l OCR. Des Solutions Architects d’AWS ont collaboré avec les ingénieurs d’Oldcastle pour concevoir une solution évolutive capable d’automatiser le flux de traitement des documents. AWS ML Blog L’approche d’Oldcastle repose sur une architecture pilotée par les événements qui commence par Amazon Simple Email Service (Amazon SES) recevant les billets d’expédition envoyés directement par les chauffeurs. Le flux utilise les Notifications d’événements S3 pour traiter les documents à grande échelle et les acheminer vers un orchestrateur de tâches à montée automatique. L’architecture montre comment Amazon Textract gère de gros fichiers PDF, produisant des sorties contenant les géométries nécessaires pour faire tourner et corriger le layout avant de convertir le contenu en Markdown. Un Markdown de qualité est essentiel pour que Bedrock identifie les bons couples clé–valeur. AWS ML Blog
Quoi de neuf
L’intégration combine plusieurs services AWS pour automatiser le traitement POD et le rapprochement des factures avec les bons de commande, en mettant l’accent sur l’efficacité des coûts et l’évolutivité :
- Introduction par e-mail via Amazon SES pour les billets d’expédition
- Traitement orienté événements via les Notifications d’événements S3
- Orchestrateur de tâches à montée automatique
- Extraction de documents avec Textract, y compris la gestion de gros PDFs et la production de Markdown avec des géométries pour corriger le layout
- Mise en forme des données et formatage pour Bedrock, en se concentrant sur l’extraction des données nécessaires pour limiter les jetons de sortie
- Bedrock choisi pour son coût et sa capacité à traiter des formats où les champs à extraire restent les mêmes
- Voie envisagée pour l’extension à la comptabilité fournisseurs, la validation W-9 et les flux d’approbation de documents automatisés Ces étapes démontrent une approche pratique et scalable pouvant être adaptée à d’autres défis de traitement documentaire et d’optimisation des processus avec l’IA. AWS ML Blog
Pourquoi c’est important (impact pour les développeurs et les entreprises)
Ce cas illustre comment une opération extensive et répartie peut moderniser ses flux documentaires grâce à une pipeline d’IA complète. Points clés :
- Une architecture orientée événements de bout en bout peut gérer des volumes importants de documents tout en réduisant l’intervention manuelle. AWS ML Blog
- Tirer parti de Textract et Bedrock permet d’exploiter les forces d’un OCR/ extraction de structures et d’une plateforme de modèles linguistiques pour extraire des champs cohérents dans des formats similaires. AWS ML Blog
- La conception axée sur les coûts rend l’utilisation de l’IA pour le traitement documentaire viable à grande échelle grâce à la limitation des jetons de sortie et au traitement par lots de Bedrock. AWS ML Blog
- La solution ouvre des perspectives pour des cas d’usage plus larges, tels que le traitement des factures AP, la validation W-9 et les flux d’approbation automatiques, indiquant un modèle reproductible pour les flux de travail d’entreprise. AWS ML Blog
Détails techniques ou Mise en œuvre
L’architecture repose sur une pipeline robuste, évolutive et sécurisée :
- Consentement et ingestion : les billets d’expédition arrivent via Amazon SES et sont transmis au système par les conducteurs sur le terrain. AWS ML Blog
- Ingestion et routage : les documents sont traités via une architecture pilotée par les événements utilisant les Notifications d’événements S3, permettant un traitement à l’échelle lorsque de nouveaux billets arrivent. AWS ML Blog
- Orchestration : un orchestrateur de tâches à montée automatique gère les tâches de traitement. AWS ML Blog
- Extraction et gestion de layout : Textract traite les gros PDFs et produit des sorties contenant les géométries nécessaires pour corriger le layout avant de générer Markdown. Markdown de qualité pour Bedrock afin d’identifier les paires clé–valeur correctes. AWS ML Blog
- Mise en forme et coûts : les données extraites sont formatées pour Bedrock, en limitant les jetons de sortie et en utilisant le traitement par lots pour réduire les coûts. AWS ML Blog
- Choix de la plateforme : Bedrock est choisi pour son coût et sa capacité à traiter des formats où les champs à extraire restent les mêmes. AWS ML Blog Cette implémentation peut servir de modèle pour des scénarios similaires, tels que le traitement de factures et le rapprochement avec les commandes, démontrant une approche reproductible pour les flux de documents avec l’IA. La publication d’origine détaille ces choix et résultats. AWS ML Blog
Points clés (takeaways)
- Le traitement de documents via IA peut remplacer un OCR fragile par une solution évolutive de bout en bout, du courrier électronique à l’extraction guidée par IA. AWS ML Blog
- Une architecture orientée événements peut gérer de grands volumes de documents répartis sur de nombreuses installations avec moins d’intervention manuelle. AWS ML Blog
- Textract et Bedrock travaillent ensemble pour extraire et structurer les données de manière efficace, avec des choix axés sur les coûts. AWS ML Blog
- La solution ouvre des perspectives pour d’autres cas d’utilisation, comme le traitement des factures AP, la validation W-9 et des flux d’approbation automatiques. AWS ML Blog
FAQ
-
Quel problème Oldcastle a-t-elle rencontré ?
Un flux de traitement POD inefficace et laborieux, associé à un OCR peu fiable nécessitant une maintenance constante. [AWS ML Blog](https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/)
-
Comment fonctionne la solution à haut niveau ?
Ingestion par e-mail via SES, traitement orienté événements via Notifs S3, un orchestrateur scalable, Textract pour l’extraction et Bedrock pour le traitement des données sur des champs standardisés. [AWS ML Blog](https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/)
-
Comment les coûts sont-ils gérés ?
En limitant les jetons de sortie et en utilisant le traitement par lots de Bedrock pour réduire les coûts. [AWS ML Blog](https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/)
-
uels usages futurs sont envisagés ?
Extension possible au traitement des factures AP, à la validation W-9 et aux flux d’approbation de documents automatisés. [AWS ML Blog](https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/)
Références
- AWS ML Blog: Oldcastle accélère le traitement de documents avec Amazon Bedrock. https://aws.amazon.com/blogs/machine-learning/oldcastle-accelerates-document-processing-with-amazon-bedrock/
More news

Faire passer vos agents IA du concept à la production avec Amazon Bedrock AgentCore
Une exploration détaillée de la façon dont Amazon Bedrock AgentCore aide à faire passer des applications IA basées sur des agents du proof of concept à des systèmes de production de niveau entreprise, en préservant mémoire, sécurité, observabilité et gestion d’outils à l’échelle.

Surveiller l’inférence par lot Bedrock d’AWS via les métriques CloudWatch
Apprenez à surveiller et optimiser les jobs d’inférence par lot Bedrock via CloudWatch, with alertes et tableaux de bord pour améliorer les performances, les coûts et l’exploitation.

Prompting pour la précision avec Stability AI Image Services sur Amazon Bedrock
Bedrock intègre Stability AI Image Services avec neuf outils pour créer et modifier des images avec précision. Apprenez les techniques de prompting adaptées à l’entreprise.

Utiliser les AWS Deep Learning Containers avec SageMaker AI géré MLflow
Découvrez comment les AWS Deep Learning Containers (DLCs) s’intègrent à SageMaker AI géré par MLflow pour équilibrer le contrôle de l’infrastructure et une gouvernance ML robuste. Un flux TensorFlow pour la prédiction de l’âge des abalones illustre le suivi de bout en bout et la traçabilité des modè

Évoluer la production visuelle avec Stability AI Image Services dans Amazon Bedrock
Stability AI Image Services est désormais disponible dans Amazon Bedrock, offrant des capacités d’édition d’images prêtes à l’emploi via l’API Bedrock et étendant les modèles Stable Diffusion 3.5 et Stable Image Core/Ultra déjà présents.

Créer des flux de travail agentiques avec GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore
Vue d’ensemble complète sur le déploiement des modèles GPT OSS d’OpenAI sur SageMaker AI et Bedrock AgentCore pour alimenter un analyseur d’actions multi-agents avec LangGraph, incluant la quantification MXFP4 en 4 bits et une orchestration sans serveur.